
{kind=link}
{kind=link}
{kind=link}
-202x49px_tcm102-7514827_tcm102-2750236-32.png)
本ページの製品は2024年4月1日より、エフサステクノロジーズ株式会社に統合となり、順次、切り替えを実施してまいります。一部、富士通表記が混在することがありますので、ご了承ください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- ストレージトップ
- 製品ラインナップ
- ETERNUS関連情報
- お役立ち情報
-
ユニファイドストレージ徹底活用
お客様の選定・検討に有用な情報を集約
-
1分でマスター!オールフラッシュ
技術用語解説やフラッシュストレージの特長、展望などが1分程度で理解できる
-
ストレージ技術用語解説
ストレージ製品に関する技術用語を解説
-
用語集
ETERNUSにまつわる用語を解説
-
ユニファイドストレージ徹底活用
- コンセプト
Hadoopとは
Hadoop(ハドゥープ)は、データを複数のサーバに分散し、並列して処理するミドルウェア(ソフトウェア基盤)です。テラバイト、ペタバイト級大容量データの分析などを高速処理できるため、「ビッグデータ」活用における主要技術として活用が進んでいます。
Hadoop登場の背景
近年、大量でかつ多種多様なデータを分析し、その結果得られる情報をもとに、マーケティングや新たなビジネスを創出しようというICT活用が新たな潮流となっています。
例えば、ソーシャルメディアなどに日々蓄積する、テキストデータや音声、動画データなど非構造データも、その意味では価値のある「ビッグデータ」ですが、これらテラバイト(1兆バイト以上)からペタバイト(1,000兆バイト)におよぶデータを高速・効率的に処理するために、新たな手法が必要となりました。従来では一般的だった「対象となるデータを1つのサーバに蓄積し、あるキーワードで問いかけて、目的のデータを抽出する方法」では高速処理が難しいのです。
そこで考えられたのがデータを分散並列処理する手法です。つまり、データを複数のサーバに分散させ、各サーバに計算処理させることで、1台のコンピュータでは難しい大容量データの高速分析処理を行おうというものです。
ただ、分散並列処理を行う上ではいくつかの課題もありました。例えば、複数のサーバをネットワークでつなぎ、データを分散させたり、計算処理の同期をとったり、あるサーバが何らかの理由でストップした場合に対処する仕組みも求められるなど、複雑なシステム構築になるのです。当然、スピードアップや容量アップしようとする場合も容易ではありません。これらの課題に応えるのが、Hadoopなのです。
Hadoopのユニークな仕組み
Hadoopでは、1台のマスターサーバと、その配下につながる多数のスレーブサーバが連係プレーでデータの高速処理を行います。データ処理全体の流れをコントロールするのがマスターサーバで、実際の計算処理は配下のスレーブサーバが手分けして行います。したがって、スレーブサーバの台数が多ければ多いほど処理能力は高まり、爆発的に増大するデータを高速で計算処理できるようになるわけです。
Hadoopを特長づけているのは、HDFS(Hadoop Distributed File System)と呼ばれるファイルシステム、そしてMapReduceと呼ばれる計算プログラミングの2つの技術です。 HDFSは、多数のスレーブサーバのハードディスクを取りまとめ、そこに計算すべき膨大なデータを書き込んだり、また集計した結果を書き込んだりできる仮想的なファイルシステムです。 MapReduceは、計算処理を2つの手順、「Map処理(与えられたデータから欲しいデータを抽出・分解する)」と「Reduce処理(抽出されたデータ集計する)」でこなす手法です。各スレーブサーバは割り振られた分をMapReduceによって計算処理します。複数台のスレーブサーバで並列処理ができるので効率的です。
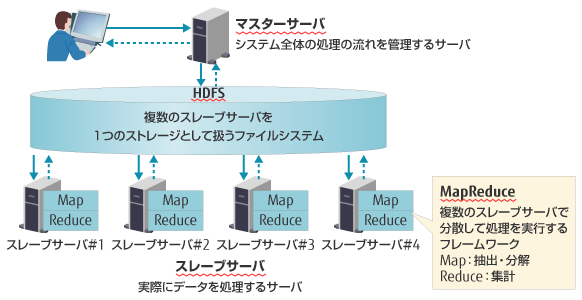 図1. Hadoopにおけるデータ処理全体の流れ
図1. Hadoopにおけるデータ処理全体の流れ
図2のMapReduceの処理イメージをご覧ください。「季節の人気おかずランキング(口コミ)」を例にとり、口コミより得た情報から、人気のおかずを抽出、分解、集計し、順位づけした略図です。
ユーザー数が1千万人を超える料理レシピサイトでは、約1年分の膨大すぎるRelational Data Baseのデータ解析に約10カ月要する見積もりに対し、Hadoopの利用により、その処理を1日半程度に短縮されたという事例もあります。
このように、HDFSとMapReduceの組み合わせで、現在、数ペタバイト程度のデータまでを迅速に分散並列処理できるようになっています。
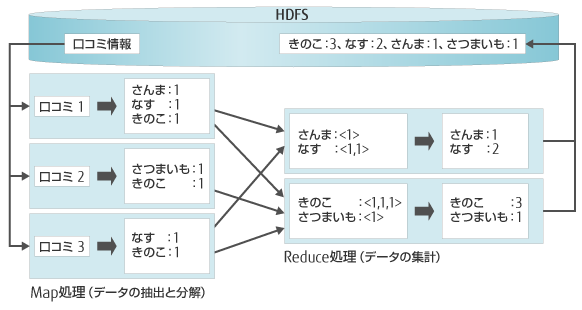 図2. MapReduceの処理イメージ
図2. MapReduceの処理イメージ
掲載日:2012年9月26日
関連情報を探す
ストレージシステム ETERNUS製品・サービスに関するお問い合わせ
-
入力フォーム
当社はセキュリティ保護の観点からSSL技術を使用しております。
この製品に関するお問い合わせは、富士通株式会社のフォームを使用し、2024年4月1日よりエフサステクノロジーズ株式会社が対応いたします。