
{kind=link}
{kind=link}
{kind=link}
-202x49px_tcm102-7514827_tcm102-2750236-32.png)
本ページの製品は2024年4月1日より、エフサステクノロジーズ株式会社に統合となり、順次、切り替えを実施してまいります。一部、富士通表記が混在することがありますので、ご了承ください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- ストレージトップ
- 製品ラインナップ
- ETERNUS関連情報
- お役立ち情報
-
ユニファイドストレージ徹底活用
お客様の選定・検討に有用な情報を集約
-
1分でマスター!オールフラッシュ
技術用語解説やフラッシュストレージの特長、展望などが1分程度で理解できる
-
ストレージ技術用語解説
ストレージ製品に関する技術用語を解説
-
用語集
ETERNUSにまつわる用語を解説
-
ユニファイドストレージ徹底活用
- コンセプト
重複排除(デデュプリケーション、デデュープ)
重複排除とは、バックアップの際に対象データを解析し、重複データを自動的に検出して排除する技術です。英語ではDe-duplicationと表記され、「デデュプリケーション」「デデュープ」などと表現されることもあります。
大容量のデータをいかにして保管しておくか。これは多くの企業が抱える課題です。データの重複をなくすことで、バックアップする際のデータ転送量や格納容量を大幅に削減できます。
必要となった背景
昨今の加速的なビジネスデータの増大により、ストレージにかかるコストも増加してきています。このコスト増加を抑える手段である技術開発が必要とされたのです。
業務のシステム化や内部統制により、幅広いビジネスデータがデジタル化され、ストレージに保存されるようになってきました。さらに、大容量の静止画や動画もデジタル化・保存が増大を促しています。これらデータの増加に併せて、ストレージを買い足していっては、IT投資予算を圧迫してしまいます。また、蓄積されるデータに重複が多いのも事実です。ドキュメントを世代管理している場合、ほとんどが重複データとなります。例えば、社内メールでドキュメント・ファイルを添付して複数の宛先に送信した場合、宛先の数だけ重複したデータが生成されることになります。グループ内で同じドキュメントを、それぞれに保存している場合も少なくありません。
このように、重複データを排除し、ストレージのデータ容量を削減、コスト増加を抑えることができる技術が、重複排除なのです。
重複排除の仕組み
例えば、図1のようなサーバに格納されているデータをバックアップする場合、既にバックアップされているデータと比較、重複しているデータを検出し、そのデータはバックアップしないようにします。
サーバAのデータをバックアップした後に、サーバBのデータをバックアップする場合、A、B、D、Eのデータは既にバックアップされているため、Fのデータのみがバックアップされます。サーバCのデータも同じように、既にバックアップされているA、B、C、Dのデータを除く、Gのデータのみがバックアップされます。
このように、重複排除機能を活用すると、データ容量は10分の1~50分の1にも圧縮できるケースもでてきます。
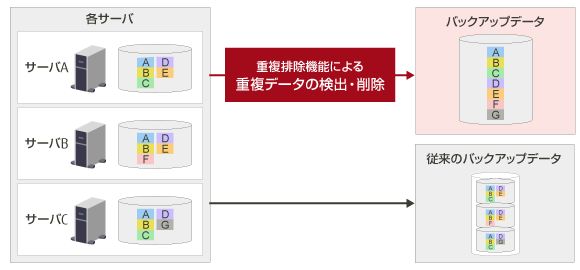 図1. 重複排除の仕組み
図1. 重複排除の仕組み
重複排除の3つの方式
重複排除には、実行する場所とタイミングで大きく3つの方式があります。
ひとつめは、サーバ側で重複を検出、排除後にデータをストレージへ転送する「プリ・プロセス方式」。2つめは、サーバからストレージにデータを転送する過程で重複を検知し、保存する前に排除する「インライン方式」。3つめは、サーバからストレージにすべてのデータを保存した後、ストレージ内で重複排除する「ポスト・プロセス方式」です。
それぞれ図2のような特徴があります。
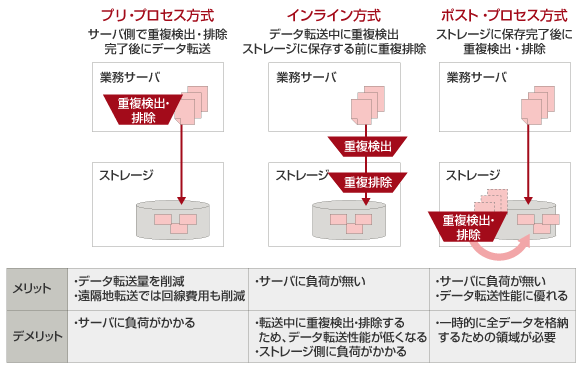 図2.重複排除の3つの方式のメリット/デメリット
図2.重複排除の3つの方式のメリット/デメリット
ETERNUSでは重複排除に対応した製品、オールフラッシュストレージ、 ハイブリッドストレージを提供しています。
更新日:2021年7月6日
掲載日:2012年4月24日
関連情報を探す
ストレージシステム ETERNUS製品・サービスに関するお問い合わせ
-
入力フォーム
当社はセキュリティ保護の観点からSSL技術を使用しております。
この製品に関するお問い合わせは、富士通株式会社のフォームを使用し、2024年4月1日よりエフサステクノロジーズ株式会社が対応いたします。