
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Fujitsu and Carnegie Mellon University collaboration achieves breakthrough in dynamic 3D structure representation, presented at CVPR 2023
July 21, 2023
JapaneseFujitsu and Carnegie Mellon University (CMU) joint research project has been selected for presentation at CVPR (The IEEE/CVF Conference on Computer Vision and Pattern Recognition) 2023, the premier computer vision conference, held from June 18-22, 2023.
This technology enables fast and highly-accurate image generation from dynamic neural 3D structure representations. Plans for the future include leveraging this technology in various applications, including simulation analysis based on dynamic 3D scenes and 3D avatars.

About CVPR 2023
- Conference: CVPR 2023
 (The IEEE/CVF Conference on Computer Vision and Pattern Recognition)
(The IEEE/CVF Conference on Computer Vision and Pattern Recognition) - Date: June 18, - June 22, 2023
- Venue: Vancouver, Canada
- Title: DyLiN: Making Light Field Networks Dynamic
Authors:(Fujitsu) Koichiro Niinuma
(CMU) Heng Yu, Joel Julin, Zoltán Á Milacski, László A. Jeni
Limitation of existing neural 3D structure representation
There has been significant attention paid to implicit neural 3D representation, with Neural Radiance Field (NeRF) representing a prominent example. These technologies enable the high-precision 3D reconstruction of objects from multiple photographs taken from different angles. Introduced initially in 2020, NeRF had a number of limitations such its unsuitability for dynamic scenes and the significant computational time required for image generation. These limitations greatly restricted its practical usability in real-world applications. To address these challenges, many NeRF extension approaches have been proposed, and some of them focused on either accommodating dynamic scenes or enabling fast image generation. However, none of the proposed approaches so far have been able simultaneously to meet both requirements.
Our approach: Dynamic neural 3D representation with fast rendering
Our breakthrough involves the development of Dynamic Light Field Network (DyLiN), which accomplishes both dynamic scene adaptation and fast image generation. DyLiN can be applied to a range of applications, including real-time generation of photo-realistic 3D avatars as shown in Figure 1.
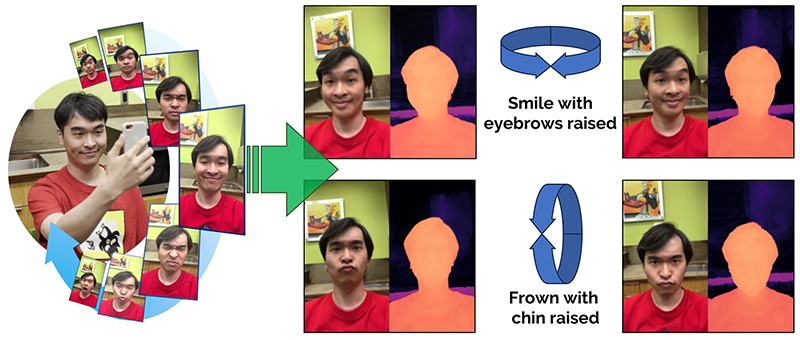 Figure 1. Application example using our technology
Figure 1. Application example using our technology
Figure 2 shows the pipeline of training DyLiN. First, we train a dynamic teacher NeRF using real data from a given scene. Then, we synthesize pseudodata from the teacher. Finally, using both the pseudodata and real data, we train our very deep dynamic student DyLiN network. Figure 3 illustrates the DyLiN network architecture. Given a ray r, with origin and direction, and time t as inputs, we deform r and sample few points along the deformed ray for encoding with the blue MLP. In parallel, we also lift the ray and time T to the hyperspace code w, using the green MLP, and concatenate it with each of the sampled points. The concatenation is then passed to regress the RGB color of the ray at time t directly using the red MLP. To obtain this architecture, we directly extended the R2L LFN architecture to represent dynamic scenes. Specifically, we added two MLPs. The first to offset the ray and the second to learn a hyperspace for the ray, given a camera ray at time T. We also introduced Controllable Dynamic Light Field Network (CoDyLiN), which enhances DyLiN with controllable attribute inputs.
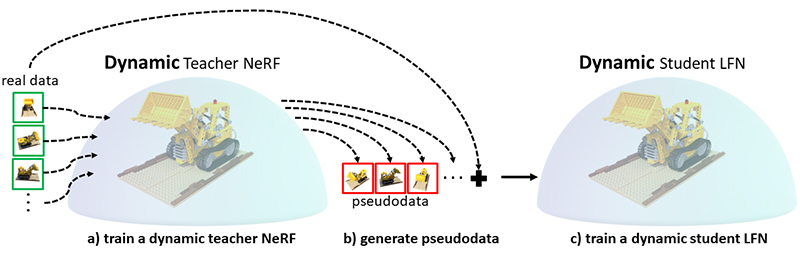 Figure 2. Pipeline of training DyLiN
Figure 2. Pipeline of training DyLiN
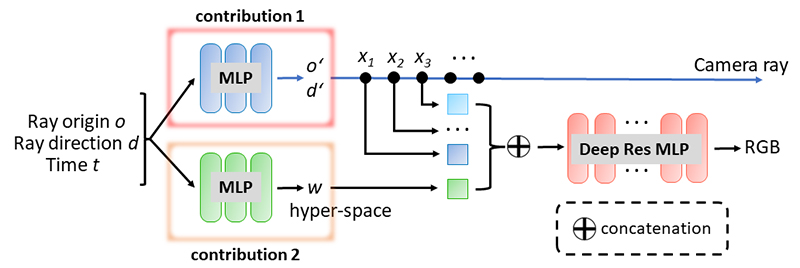 Figure 3. DyLiN network architecture
Figure 3. DyLiN network architecture
Comparison between the existing approach (HyperNeRF)and DyLiN
- DyLiN: Making Light Field Networks Dynamic(CVPR 2023 open access)
- DyLiN Project Webpage
Future plan
This technology forms a crucial component in supporting Converging Technologies developed by Fujitsu, and will be applied to applications for Social Digital Twin (SDT) and the enterprise metaverse. More specifically, we intend to explore its utilization in mobility, security and smart city services that involve the generation and analysis of real-world 3D scenes. Additionally, we will advance its applications in virtual space communication service using 3D avatars generated from real images.
* Social Digital Twin
A Social Digital Twin digitally reproduces the relationships and connections between people, goods, the economy and society to offer a simulation, prediction and decision-making environment in which to solve diverse and complex social issues.
Comment from developers
-

Carnegie Mellon University
Heng Yu -

Carnegie Mellon University
Joel Julin -

Carnegie Mellon University
Zoltán Á Milacski -

Fujitsu
Koichiro Niinuma -

Carnegie Mellon University
László A. Jeni
In our projects, we are conducting research and development of core technologies required for the implementation of SDT and the enterprise metaverse. The close collaboration between researchers from Fujitsu and CMU allows us to leverage our strengths and pursue the development of innovative technologies that have a positive impact on society.
Inquiries about this article
Fujitsu Research Converging Technology Laboratory
contact-cvprpaper2023@cs.jp.fujitsu.com
Share
Recommend
Connect with Fujitsu Research


