
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Interpreting relationships from images with world-leading accuracy
– Fujitsu’s scene graph generation technology sets new standards for image recognition, recognizing the relationship between people, objects, and the environment to create a highly accurate understanding
September 9, 2022
Japanese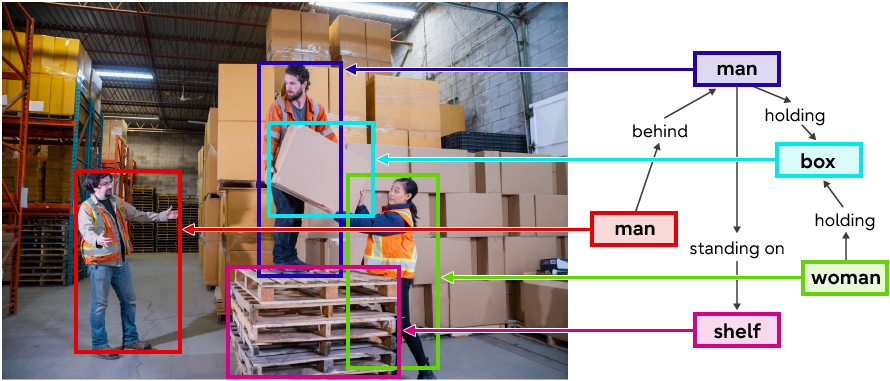
The amazing advances in Deep Learning technology in recent years has transformed how we can use technology to recognize people and objects from images, with important new social implementations.
For example, AI is being used to analyze the flow of people in stores and to detect suspicious individuals from surveillance camera images.
But the key to arriving at a real understanding of a given situation relies on being able to interpret the relationship between people and objects. Automation using AI only gives us an insight into what people are doing in a store, such as looking at products, or where workers are standing in a factory. The missing element is to add their relationship to the objects, such as watching, holding, standing etc, and whether they are interested in buying the object or doing something potentially dangerous in the workplace.
We decided to develop a new technology capable of accurately understanding an entire scene, called scene graph technology. It works by automatically recognizing and extracting all the important information contained in images to provide a highly accurate picture of the relationships between people, objects, and the environment. In addition to information about the types of people and objects, our technology also provides insights into their positional relationships (covering 15 types such as being on, behind, above) and the state of the actions (35 different types including to have, wear, and eat) between the people and objects. It recognizes these with world-leading accuracy, generating a detailed scene graph.
This exciting technology was recently presented on the world stage at the "ICPR 2022 ![]() (26th International Conference on Pattern Recognition)" in Montreal, Canada, which took place on August 21, 2022.
(26th International Conference on Pattern Recognition)" in Montreal, Canada, which took place on August 21, 2022.
Overcoming the Challenges
One way of expressing the relationships in an image is to use a Scene graph, which is a graphical representation of scene entities (Figure 1).
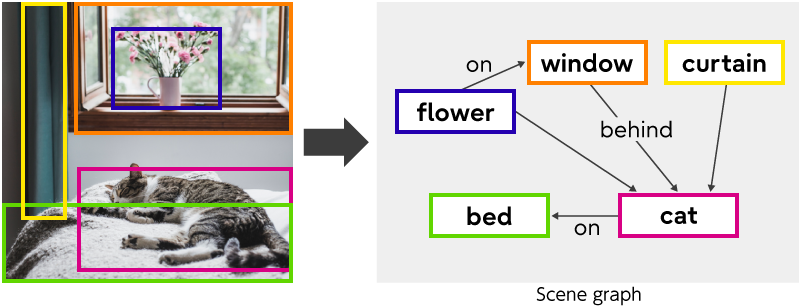 Figure 1 Example of a scene graph
Figure 1 Example of a scene graph
Previous approaches extracted objects detected in an image and estimated the relationships between them using a rectangular system. The problem with this, however, is that important information often exists outside of the segmented area, leading to a lack of accuracy in the relationship recognition (Figure 2).
For example, if you want to determine the relationship between the curtains and the cat, and you only look at these objects, it is impossible to arrive at a result. You need to know the overall structure of the room and how it relates to the surrounding objects such as the table, the window etc in order to estimate the relationship correctly.
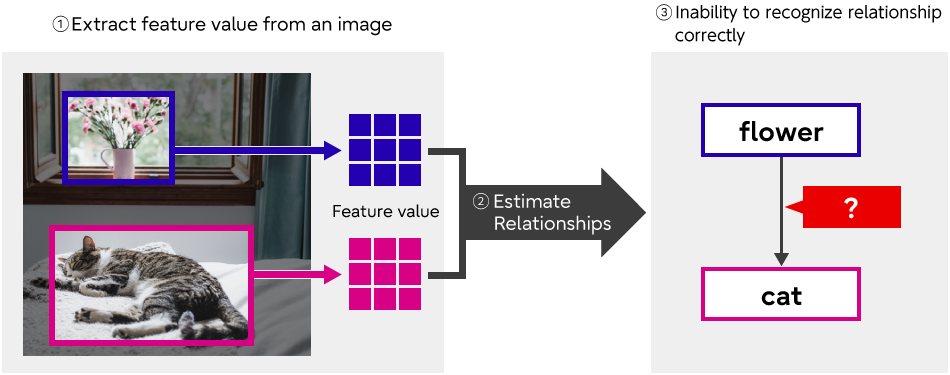 Figure 2 Problems with previous approaches
Figure 2 Problems with previous approaches
Scene graph generation works in a different way, learning annotation data created by manually assigning the correct answers to tens of thousands of images. However, even a single image can contain many objects. And since the potential relationships between them results in an enormous number of combinations, it is very difficult manually to create an exhaustive list of possible annotations, leading to omissions. This can lead to incorrect learning as objects and relationships are missed, impacting on performance.
A novel new approach to scene graph technology
At Fujitsu, we have developed a different method that looks at each object in an image and adaptively extracts the regions of interest that are important for recognizing relationships (Fig. 3).
On detecting an object within an image, our technology extracts the feature values between two objects (a subject and an object) and applies a relational estimation that in turn generates a pair feature value. By correlating this pair feature value with each pixel, it is possible to create a high value relational attention map in the target area, which is the key to being able to recognize the relationship between the different objects.
This approach involving a learned relational attention map greatly improves the accuracy of relationship recognition and allows the target area to be extracted automatically. Finally, the relationship between the subject and the object can be estimated from the information extracted according to the relational attention map. This makes it possible to factor in not only the subject and object areas, but also information about the target areas that are important for estimating the relationships with high accuracy.
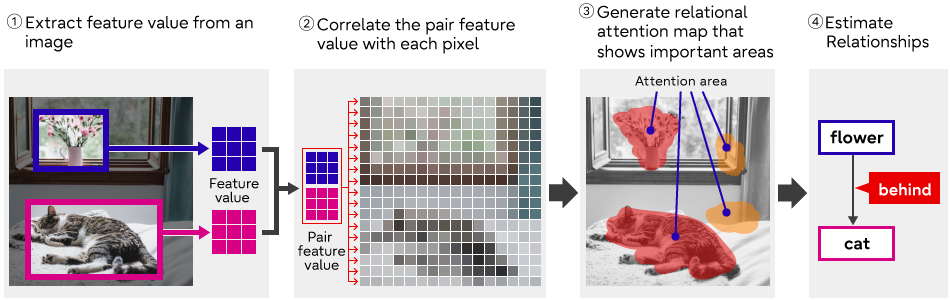 Figure 3 Automatic “important area” extraction mechanism
Figure 3 Automatic “important area” extraction mechanism
In addition, in order to ensure the correct recognition of relationships in images, we developed a method to supplement incomplete training data by creating pseudo annotation data. In the overall training data, any annotation omissions are small compared to the number of correct annotations. As a result, we focused on the fact that many of the omissions can be detected by generating a Scene graph of the training image, using the trained model just once. By adding the scene graph generated by this trained model to the original training data as pseudo annotation data, we can successfully supplement any incomplete training data. With a degree of fine-tuning that uses the completed training data to re-learn the model, we can achieve even higher accuracy.
Our innovative technology has been thoroughly tested and evaluated, using the world standard public data set Visual Genome for scene graph generation that includes 150 object types and 50 defined relationships. We achieved world-class accuracy in recognizing 26,000 test images that are not used for training, a performance that is more than 40% higher than conventional technology.
Overview of ICPR 2022
Details of this technology were presented at the International Conference on Image Recognition (ICPR 2022).
- Conference: 26TH International Conference on Pattern Recognition
 (ICPR)
(ICPR) - Date: August 21, 2022 to 25th
- Title: Transformer-based Scene Graph Generation Network With Relational Attention Module
- Authors: (Fujitsu) Takuma Yamamoto, Yuya Obinata, Osafumi Nakayama
Developer Comments
Development Team Members from the Advanced Converging Technologies Laboratories.

Takuma Yamamoto

Yuya Obinata

Osafumi Nakayama
In our project, we are focusing on field practice and the implementation of technology, aiming to achieve the world's best performance in various benchmark tests and competitions, as well as gaining recognition at leading conferences in the field of AI image recognition. We expect this technology to have wide-ranging applications, including in marketing, manufacturing, public safety, and support for wellbeing. We will continue to pursue our research and development to create a safe, secure, and resilient society through cutting-edge technologies.
Looking Ahead
This technology will be implemented as a new function in our action-recognition AI, "Actlyzer" behavioral analysis technology, and will be put into practical use by the end of FY 2023. It will be demonstrated at various sites for applications such as improving retail store operations by estimating purchasing intent, identifying dangerous behavior through video surveillance, and analyzing factory operations.
Related links
・Enhancing the Retail Experience with Actlyzer - Fujitsu’s intelligent behavioral analysis technology delivers in-store context marketing [Fujitsu Global Site] (April 7, 2022 Technical Topics)
・Fujitsu Technical Computing Solution GREENAGES Citywide Surveillance [Fujitsu Global Site]
・Fujitsu Develops New "Actlyzer" AI Technology for Video-Based Behavioral Analysis [Fujitsu Global Site] (November 25, 2019 Press Released)
For more information on this topic
fj-actlyzer-contact@dl.jp.fujitsu.com
Please note that we would like to ask the people who reside in EEA (European Economic Area) to contact us at the following address.
Ask Fujitsu
Tel: +44-12-3579-7711
http://www.fujitsu.com/uk/contact/index.html![]()
Fujitsu, London Office
Address :22 Baker Street
London United Kingdom
W1U 3BW
Share
Recommend
Connect with Fujitsu Research


