
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
世界トップクラスの精度で人と「ヒト・モノ・環境」の関係性を映像から認識し、状況を的確に理解するシーングラフ生成技術を開発
2022年8月22日
English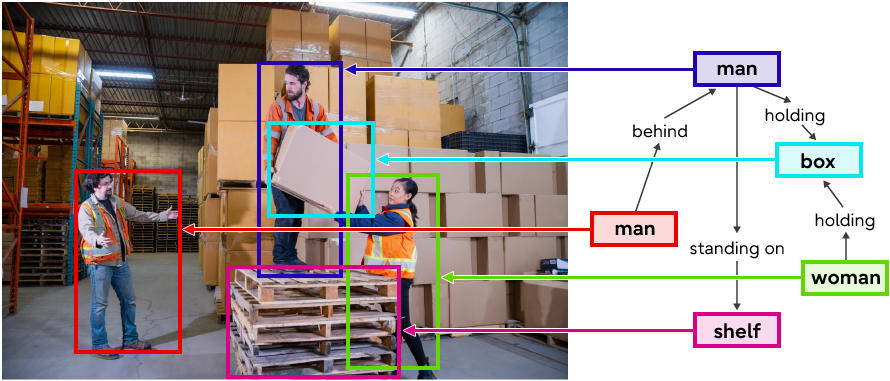
近年、Deep Learning技術の著しい発展により、映像から人や物体を認識する技術の社会実装が様々な分野で進んでいます。例えば、店舗内での人の動線分析や監視カメラ映像における不審者の検出などに応用され、AIによる複雑な業務の自動化が進んでいます。
しかし、店舗内顧客の購買意欲の高さや工場での危険作業の認識などでは、「商品を見ながら男女が会話している」や「棚の上に立ちながら大きな箱を複数人で持っている」といった、人や物体の有無だけでなく、それらの間の関係性(見ている、持っている、立っている等)を含めた状況の理解が必要となり、AIによる自動化はできていませんでした。
今回、映像に映っている人と「ヒト・モノ・環境」の関係性を認識するために重要な対象領域を漏れなく自動で抽出し、シーン全体の状況を的確に理解するシーングラフ生成技術を開発しました。本技術により、映像に映る人や物体の種類に加え、それら人や物体間の位置関係(on, behind, above等15種類)と作用状態(have, wear, eat等35種類)を高精度に認識し、シーングラフとして生成できます。
本技術は、2022年8月21日よりカナダMontrealで開催される国際会議「ICPR 2022 ![]() (26th International Conference on Pattern Recognition)」にて、発表します。
(26th International Conference on Pattern Recognition)」にて、発表します。
従来の課題
現在、画像内の関係性を表現する方法としてシーンの構成要素をグラフ構造で表したシーングラフがあります(図1)。
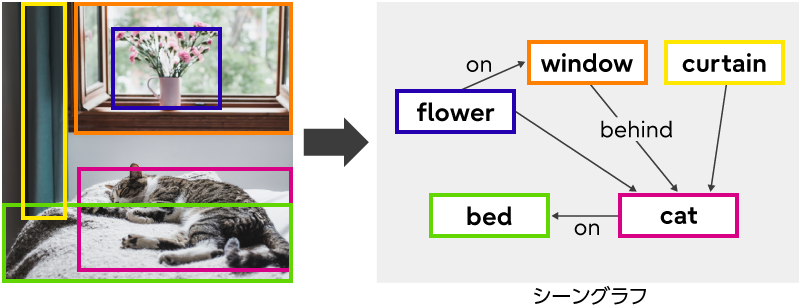 図1 シーングラフの例
図1 シーングラフの例
従来技術では、シーングラフを生成するのに画像内で検出された物体を囲う長方形などの矩形にしたがって切り出して、それらの間の関係性を推定していました。しかし、切り出された領域以外のところに関係性を認識する上で重要な情報が存在する場合があり、それらが欠落することで、正しく関係性を認識できないことがありました(図2)。
関係性を推定する対象であるカーテン(curtain)と猫(cat)の領域だけ見ても、奥行きのある部屋全体の構造や、テーブルなど周囲の物体との位置関係がわからないと、それらの間の関係性は判断できません。
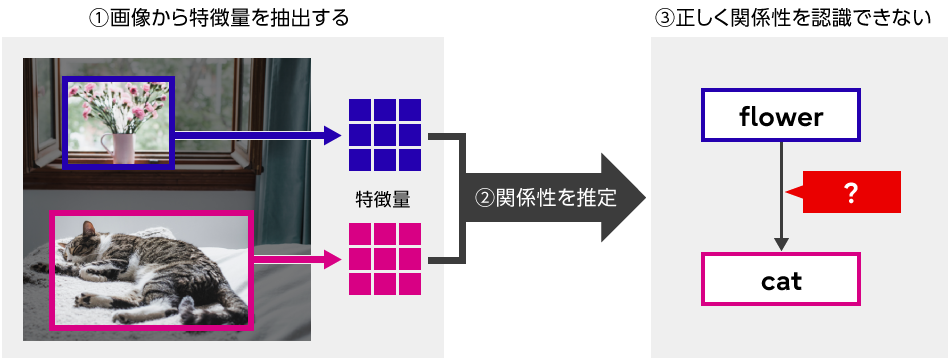 図2 従来技術の問題点
図2 従来技術の問題点
また、シーングラフ生成は、何万枚もの画像に対して人手で正解を付与して作成したアノテーションデータを学習することで実現されます。しかし、一枚の画像であってもその中には多くの物体が写っていることがあります。さらにそれらの間の関係性は組み合わせで膨大な数となるため、網羅的に人手でアノテーションを作成することは難しく、どうしても漏れが発生してしまいます。本来検出すべき物体や関係性が画像上に存在するにも関わらずアノテーションが漏れている場合、「それらの物体や関係性は検出してはいけない」と誤った学習を行うため、性能を阻害する要因となっていました。
開発した技術
今回、画像から関係性を推定する対象ごとに、関係性を認識する上で重要な対象領域を画像全体から適応的に抽出する方式を開発しました(図3)。
具体的には、まず画像の中に含まれる物体を検出し、関係性を推定する対象となる二つの物体(サブジェクトとオブジェクト)の特徴量を抽出し、それらを一つに合成したペア特徴量を生成します。このペア特徴量と各画素との相関をとることで関係性アテンションマップを生成します。関係性アテンションマップは関係性を認識する上で重要な対象領域で高い値を示します。
関係性を認識する上でどの領域に着目する(アテンションをかける)のかは、様々な物体が写った画像データセットを学習することで獲得されます。具体的には、学習データの中の様々な物体間の関係性を認識する上で認識精度が高くなるようにアテンションのかけ方を調整して最適化します。学習が完了したAIは関係性を認識する上で重要な対象領域を自動的に抽出できるようになります。最後に、この関係性アテンションマップにしたがって抽出した情報からサブジェクトとオブジェクトの関係性を推定します。こうすることで、サブジェクトとオブジェクトの領域以外にも関係性の推定に重要な対象領域の情報を考慮できるため、高精度な推定が可能となります。
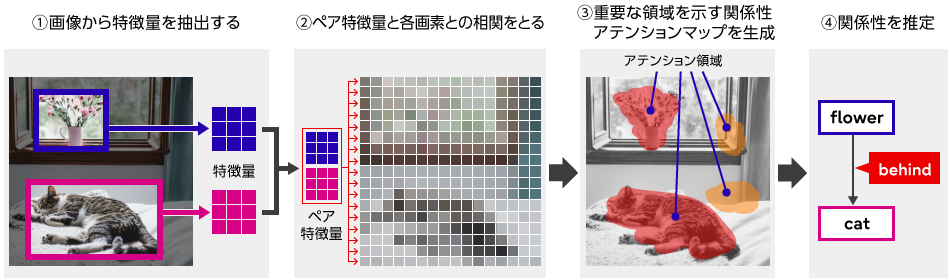 図3 対象領域の自動抽出メカニズム
図3 対象領域の自動抽出メカニズム
さらに、画像内の関係性を正しく認識するために、疑似的なアノテーションデータを作成し、不完全な学習データを補う方式を開発しました。学習データ全体の中では、正しいアノテーションと比較しアノテーション漏れは少ないため、一度学習したモデルを用い学習画像のシーングラフを生成すると、漏れていたアノテーションの多くが検出できることに着目しました。この学習済みモデルが生成したシーングラフを疑似的なアノテーションデータとしてオリジナルの学習データに追加することで、不完全な学習データを補います。補完された学習データを用いてモデルを再学習するファインチューニングを行うことで、さらなる高精度化を可能にしました。
今回開発した技術を物体の種類が150種類、関係性が50種類定義されたシーングラフ生成における世界標準の公開データセットVisual Genomeを用いて評価しました。学習には用いていない約2万6千枚のテスト画像に対する認識性能は、従来技術から40%以上向上となる世界トップクラスの精度を達成しました。
ICPR 2022の概要
本技術の詳細は、画像認識分野の国際会議ICPR2022にて発表します。
- 学会名:26TH International Conference on Pattern Recognition
 (ICPR)
(ICPR) - 開催日:2022年8月21日~25日
- タイトル:Transformer-based Scene Graph Generation Network With Relational Attention Module
- 著者:(富士通)山本 琢麿、大日方 裕也、中山 收文
開発者コメント
コンバージングテクノロジー研究所 開発チームメンバー

山本 琢麿

大日方 裕也

中山 收文
我々のプロジェクトでは、AI映像認識分野のトップカンファレンスへの論文採択や様々なベンチマーク・コンペティションの世界一を目指し、技術の現場実践や導入にも力を入れています。今回の技術は、マーケティング、ものづくり、公共安全、ウェルビーイングな暮らしのサポートなど様々な分野への応用が期待できます。今後も、最先端の技術により安心・安全でレジリエントな社会づくりを実現する研究開発に邁進していきます。
今後について
本技術を、当社の行動認識AI「行動分析技術 Actlyzer(アクトライザー)」の機能として実装し、購買意欲の推定による店舗運営の改善や、映像監視での危険行為の認識、工場における作業分析など様々な現場で実証を進め、2023年度内の実用化を目指します。
関連情報
・行動分析技術Actlyzerでリアル店舗におけるコンテキストマーケティングを実現可能に(2022年3月7日 技術トピックス)
・行動分析技術Actlyzer
人のように理解し、人のように予測・判断するAI
・Fujitsu Technical Computing Solution GREENAGES Citywide Surveillance
リアル空間のデータを活用して、ニューノーマルにおける"顧客価値の最大化" を提供しつづけるサービス
・映像から人の様々な行動を認識するAI技術「行動分析技術 Actlyzer」を開発 ![]() (2019年11月25日 プレスリリース)
(2019年11月25日 プレスリリース)
本件に関するお問い合わせ
fj-actlyzer-contact@dl.jp.fujitsu.com
EEA (European Economic Area) 加盟国所在の方は以下からお問い合わせください。
Ask Fujitsu
Tel: +44-12-3579-7711
http://www.fujitsu.com/uk/contact/index.html![]()
Fujitsu, London Office
Address :22 Baker Street
London United Kingdom
W1U 3BW
このページをシェア
Recommend
Connect with Fujitsu Research


