
文字识别技术
原理
为什么能识别文字呢
(1)将句中的文字一个个隔开。

(2)分割每个文字。
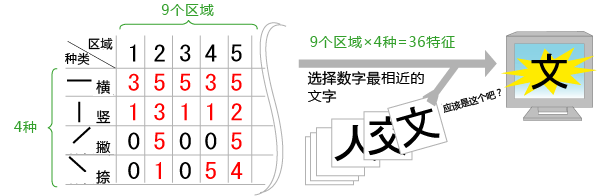
分割的数量视平假名、片假名、汉字而定。这里假设分成9个部分。

(3)调查每个区域内文字的朝向特征。
用数字表示这个字的主要特征,即“横、竖、撇、捺”4种。数字越大,说明文字朝向越正确。

(4)每个区域用4种特征表示,共有9个区域,所以共计会显示出36个表示特征的数字,接着开始辨别文字。
由于手写体文字存在个人差异,数字不一定能与词典中记载的数字相同,因此要选择数字最相近的文字,再利用相关知识(地点、姓名等)来确定文字。
- 通常1个文字是由100-400(因字而异)个特征表示。
- 使用该技术,1秒钟之内(使用3.2GHz的电脑时)可以识别的文字达到3080字,速度位于世界领先水平。
- 该技术还可以识别中文和韩文。
如何选择表示特征的数字
放大手写体文字的线会发现,横向排列着3个像素,接着向上多出1个像素,又横向3个像素,向上1个像素,像素按照这样的形式排列。因为1个区域内的横向像素总数是12个,横向像素总数是4个,所以,横竖之间的比是3比1。这个方格内的特征就是横3竖1。
(为什么“撇”特征为零呢?因为手写“文”字的撇的角度低于X轴右上22.5度,所以被判断为横线。)
