
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Harnessing Supercomputer Power for AI Modeling
- Achieving world-leading high-speed calculation performance and recognition accuracy with state of the art software technology
December 21, 2021
JapaneseAI has rapidly evolved in recent years in terms of performing large-scale processing with high performance, in order to analyze and utilize various data. It has even achieved comparable quality levels for translation and document generation to those of humans.
Learning large-scale AI models can take standards computers several months, significantly hampering their usefulness for this sort of task. Supercomputers, however, can revolutionize this and do the job in the blink of an eye. But they do require specialized knowledge to master their operation.

Fujitsu has been working to solve this problem, developing an innovative software technology that can easily process large-scale AI learning at high speed by utilizing its expertise in numerical calculations on supercomputers. We applied this technology to training a large-scale Japanese AI model, and successfully trained it in record time. By using a supercomputer, we cut the AI model training process from several months to just 4.7 hours using a supercomputer.
This ground-breaking technology was recently presented at the international conference CANDAR 2021, in November 2021.
Mastering a supercomputer
While large-scale computers are becoming more readily available for general use, it takes time to master the processing power that is thousands or tens of thousands of times greater than that of a normal computer. This is mainly due to the fact that large-scale computers are made up of many computers. As an example, let's say that a computer is processing some data by referring to it. If it is a normal computer, there is no problem because only that one computer is referencing the data. On the other hand, if 10,000 computers try to access the same data at the same time, the network lines exchanging the data will be compromised. This type of process requires a distributed processing approach in order to prevent the network from becoming flat, using multiple computers to divide and distribute the data. It is also necessary to aggregate the results of the distributed processing efficiently. Without an environment offering large-scale computers, it is extremely challenging for users to create such AI models freely.
A distributed processing optimization system that maximizes the performance of supercomputers
We have now developed a technology that enables anyone to easily prepare a training environment on a large-scale computer for high-performance natural language processing AI models, which are becoming increasingly large. Since supercomputer systems have different network configurations, file systems, and other environments, even just efficiently referencing the above data requires knowledge and skills of the system. In this software technology, HPC (High Performance Computing) experts optimize the optimization techniques according to the supercomputer system. This system applies automatic data placement and automatic distributed processing to the jobs executed by the user. As a result, the computational infrastructure can be easily transferred to a supercomputer without changing the environment of the AI framework, and the high-speed AI framework can be used without prior knowledge or skills of the supercomputer.
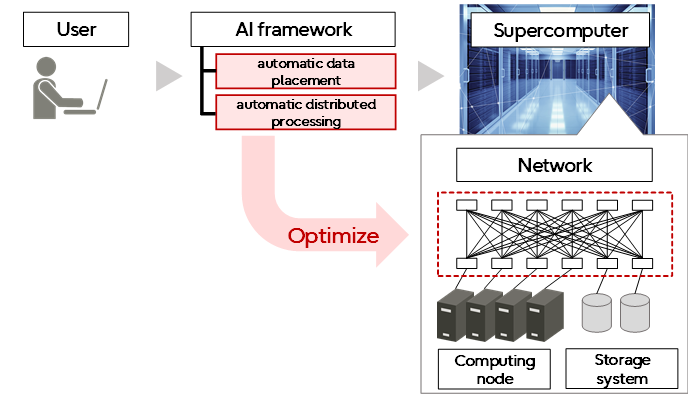 Adaptation of automatic optimization
Adaptation of automatic optimization
Tried and Tested on a large-scale Japanese AI model
In order to evaluate this environment, we established a large-scale, high-efficiency learning technique for the learning algorithm, which enabled us to improve accuracy and make the learning process faster. For the learning evaluation, we used more than 100 million training data sets and performed the calculations on a single GPU, which took several months. We used two large models, BERT-XLarge with about 1.2 billion parameter elements and BERT-3.9B with about 3.9 billion parameter elements. Using our technology, we were able to complete the training of the BERT 3.9B model in about 16 hours and the XLarge model in 4.7 hours using 768 GPUs. Due to the large scale, we also achieved the highest accuracy (according to our research) for Japanese natural language models.
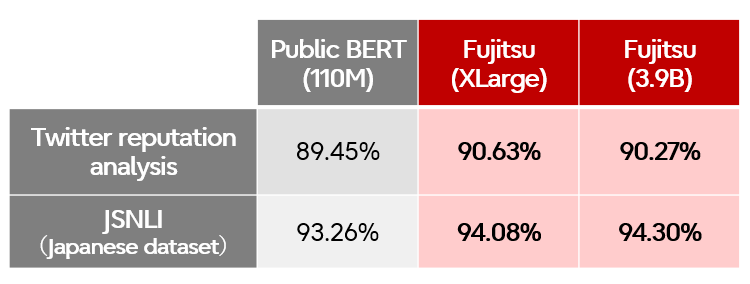
Thanks to this technology, it is now possible for any company to build its own AI based on its own data in a short period of time, using the logic required as a core technology for knowledge utilization and automatic response services using natural language.
This enables knowledge utilization of documents with greatly improved language performance. The next phase involves deploying the large-scale technology for other AI computations.
About CANDAR 2021
The details of this technology were presented at CANDAR 2021, an international conference in the field of computer science.
・Conference:CANDAR 2021 ![]()
・Data:Nov. 23-26, 2021
・Title:Efficient and Large Scale Pre-training Techniques for Japanese Natural Language Processing
・Author:Akihiko Kasagi, Masahiro Asaoka,Akihiro Tabuchi, Yosuke Oyama, Takumi Honda, Yasufumi Sakai, Thang Dang, Tsuguchika Tabaru (Fujitsu Limited)
■The Inside View from our Development Team

Akihiko Kasagi

Masahiro Asaoka

Akihiro Tabuchi

Yosuke Oyama

Takumi Honda

Yasufumi Sakai

Thang Dang

Tsuguchika Tabaru
The topic of large-scale natural language processing AI models has received a great deal of attention in recent years, both in research and in practice. On the other hand, cluster computers, which are composed of many computers, are required for their learning. In order to get the best performance out of cluster computers, we have developed a system that can easily perform training with the best performance by utilizing our experience in large-scale distributed learning of AI. This made it possible for researchers who were not familiar with large-scale environments smoothly to start research on natural language processing AI.
Acknowledgement
Computational resource of AI Bridging Cloud Infrastructure (ABCI) was awarded by “ABCI Grand Challenge” Program, National Institute of Advanced Industrial Science and Technology (AIST).
For more information on this topic
fj-hspj-contact@dl.jp.fujitsu.com
Please note that we would like to ask the people who reside in EEA (European Economic Area) to contact us at the following address.
Ask Fujitsu
Tel: +44-12-3579-7711
http://www.fujitsu.com/uk/contact/index.html![]()
Fujitsu, London Office
Address :22 Baker Street
London United Kingdom
W1U 3BW
Share
Recommend
Connect with Fujitsu Research


