
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
スーパーコンピュータを活用したAIモデルの開発において、世界トップクラスの高速演算性能と認識精度を実現できるソフトウェア技術を開発
2021年11月24日
English近年、様々なデータを解析し活用するために、AIは進化し大規模な処理を高性能に行えるようになりました。例えば、人が作業したのと同じような品質の高い翻訳や文書生成が実現されてきています。
しかし、一般のコンピュータでは大規模なAIモデルを学習するには、数か月以上かかることがあります。スーパーコンピュータ(以下、スパコン)を使えば瞬く間にできますが、使いこなすには専門の知識が必要です。
そこで、富士通はスパコンでの数値計算のノウハウを活かし、大規模なAI学習を簡単に高速処理できるソフトウェア技術を開発しました。大規模な日本語AIモデルの学習にこの技術を適用し、短時間での学習に成功しました。今回構築した規模のAIモデルの学習処理では通常数カ月以上かかりますが、スパコンを利用し4.7時間で学習できる様になりました。
本技術は、2021年11月23日から開催の国際会議CANDAR 2021で発表します。

なぜ、誰でも簡単にスパコンを使えなかったのか?
大規模コンピュータは一般利用が可能になってきている一方、普通のコンピュータの何千倍、何万倍の処理能力を使いこなすのには時間が掛かります。これは、大規模コンピュータが、多数のコンピュータを組み合わせて出来ているためです。一例として、コンピュータがあるデータを参照しながら処理を行うとします。普通のコンピュータであれば、一台のコンピュータがデータを参照するだけなので問題は起こりません。一方、1万台のコンピュータが同時に同じデータにアクセスしようとすると、データとやりとりするネットワークの回線がパンクしてしまいます。ネットワークがパンクしないように、多数のコンピュータに処理を分散させ、データも分割分散させる必要があります。また、分散して処理した結果を効率よく集約することも必要です。このようなAIモデルを自由にユーザーが作成するためには、簡単に大規模コンピュータを使いこなせる環境が無いことが課題でした。
スパコンの性能を最大限に使いこなせる分散処理最適化システム
今回、大規模化が著しい高性能な自然言語処理AIモデルの学習環境を、誰でも簡単に大規模コンピュータ上に準備できる技術を開発しました。スパコンのシステムではネットワーク構成やファイルシステム等の環境が異なっているため、上記のデータへの参照を効率良く行うだけでもシステムの知識と技術を必要とます。このソフトウェア技術ではスパコンのシステムに応じた最適化技法をHPC(High Performance Computing)の専門家が最適化し、ユーザーが実行するジョブに対して自動データ配置と自動分散処理を適用します。これにより、AIフレームワークによる環境はそのままに、計算基盤を簡単にスパコンに移す事ができ、スパコンの事前知識や技術無しで高速なAIフレームワークが利用可能になります。
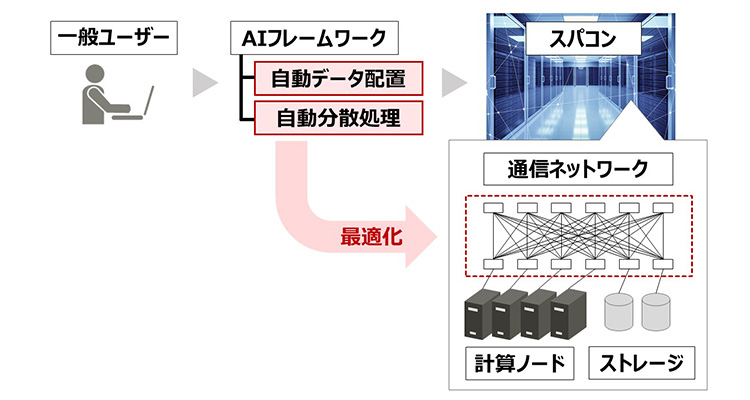 自動最適化技術の適用イメージ
自動最適化技術の適用イメージ
大規模な日本語AIモデルに適用し効果を検証
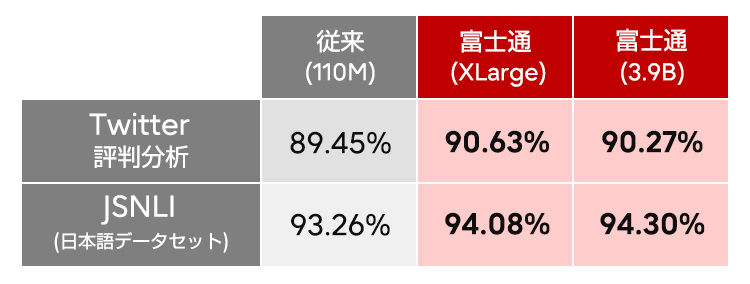
今回の環境を評価するに当たり、学習アルゴリズムの大規模、高効率学技術を確立し、精度の向上と、より高速に学習させることを可能にしました。学習の評価では1億件以上の学習用データを用いて1台のGPUで数カ月以上かかる演算を実施しました。この学習の評価ではパラメータの要素数が約12億個のBERT-XLargeとパラメータ要素数が約39億個のBERT-3.9Bの巨大なモデルを用いました。我々の技術を用いる事で、768個のGPUを用いてBERT 3.9Bモデルの学習を約16時間、XLargeモデルの学習を4.7時間で完了できるようになりました。また、大規模化により、日本語自然言語モデルとしては、最高精度(当社調べ)を達成しました。
この技術により、自然言語によるナレッジ活用や自動応答サービス等のコア技術として必要なロジックを、各企業が独自のデータで独自のAIを短時間で構築することが可能になります。
これまで出来なかった大規模AI計算を誰でも行えるようになり、大きく前進した言語性能で文書のナレッジ活用等が可能になります。他のAI計算に対しても、大規模化技術を展開していく予定です。
CANDAR 2021の概要
本技術の詳細は、コンピュータサイエンス分野の国際会議CANDAR 2021にて発表します。
・学会名:CANDAR 2021 ![]()
・開催日:2021年11月23日~11月26日
・タイトル:Efficient and Large Scale Pre-training Techniques for Japanese Natural Language Processing
・著者:富士通:笠置 明彦、麻岡 正洋、田渕 晶大、大山 洋介、本田 巧、坂井 靖文、Thang Dang、田原 司睦
■開発者コメント

笠置 明彦

麻岡 正洋

田渕 晶大

大山 洋介

本田 巧

坂井 靖文

Thang Dang

田原 司睦
大規模自然言語処理AIモデルは、研究と実用の両面で近年非常に注目されているテーマです。一方、その学習には、多数のコンピュータを結合させたクラスタコンピュータが必要です。クラスタコンピュータの性能を引き出すには独特のコツが必要なため、私たちは、これまで培ったAIの大規模分散学習の経験を活かし、簡単に性能を引き出した学習を実行できる仕組みを開発しました。これによって、大規模環境に不慣れな研究員もスムーズに自然言語処理AIの研究に着手できました。
謝辞
本研究の一部は、産業技術総合研究所様「ABCIグランドチャレンジ」プログラムにより提供を受けた,AI橋渡しクラウド(ABCI)の計算リソースを用いておこないました。
本件に関するお問い合わせ
fj-hspj-contact@dl.jp.fujitsu.com
EEA (European Economic Area) 加盟国所在の方は以下からお問い合わせください。
Ask Fujitsu
Tel: +44-12-3579-7711
http://www.fujitsu.com/uk/contact/index.html![]()
Fujitsu, London Office
Address :22 Baker Street
London United Kingdom
W1U 3BW
このページをシェア
Recommend
Connect with Fujitsu Research


