第3回:間接的ステークホルダーの存在では、裁判所の再犯予測AIの事例を用い、AI倫理を考える上では、AIの直接的な利用シーンに登場する人物だけではなく、間接的に影響を 与える/受ける ステークホルダーも含めて考慮する必要がある、というお話をしました。今回は、チャットボットAIについての事例をご紹介し、AIに学習させたくないデータの存在について考えます。
チャットボットの事例を見てみましょう
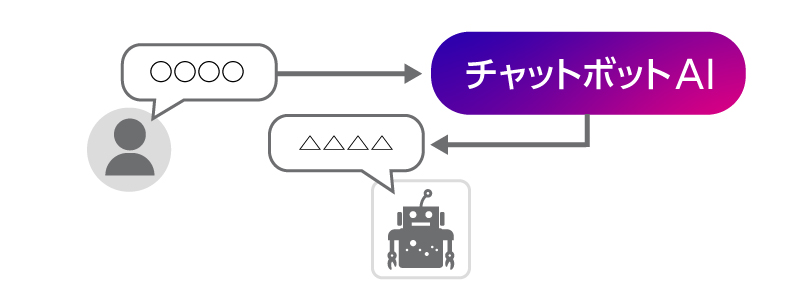
一般的にAIといえば、映画やアニメのように、人間と会話するロボットを最初にイメージされる方も多いのではないのでしょうか。近年、受付窓口や端末操作などにおいて、チャットボットと呼ばれる、会話に自動的に応答するAIが登場するシーンが本当に多くなりました。ここでは、ユーザーが会話文を入力すると、定型ではない会話文を返してくる、自由会話型のチャットボットを想定しましょう。
実は、筆者の中に、遠い学生時代にこのような自由会話型のチャットボットの研究を行っていた者がいます。チャットボットにも様々な仕組みがありますが、そのチャットボットは、ユーザーと交わした会話文をデータとして蓄積し、以降、蓄積したデータを使って自身の発言のバリエーションを増やしていく仕組みでした。会話を重ねてデータを溜めていくと、いつの間にか、チャットボットは、こちらが思いもよらない面白い返しをするようになってきて、開発しながら1ユーザーとして夢中になりました。
しばらくの間、同じ研究室の仲間たちも、チャットボットを育てるべく、暇を見つけてはせっせとチャットボットと会話をしてくれました。ある程度会話データが溜まってきたあるとき、近隣の小学生たちにチャットボットと会話をしてもらう実験イベントを実施しました。すると…小学生との会話を新しく覚えたチャットボットは、そのイベント以降、「バカなの?」などと発言するようになりました。一生懸命チャットボットを育ててきた研究室の面々は、突然、暴言を吐くダークなキャラクターに豹変したチャットボットにショックを受け、しばし呆然とすることになったのです。
この話は、昔々の個人的な思い出話ですが、実は近年、世の中で似たような事例が実際に起こりました。あるSNS上でユーザーとの会話を学習するチャットボットが公開され、その後そのチャットボットは短時間で膨大な量の会話を学習し、問題発言を連発するようになって、1日も経たないうちにサービス停止に追い込まれたのです。SNS上で誰でも利用できるチャットボットであったため、暴言事件は世界中の知るところとなってしまいました。同様の事例は様々なところで発生しています。
AIに学習させたくないデータの存在について考えてみましょう
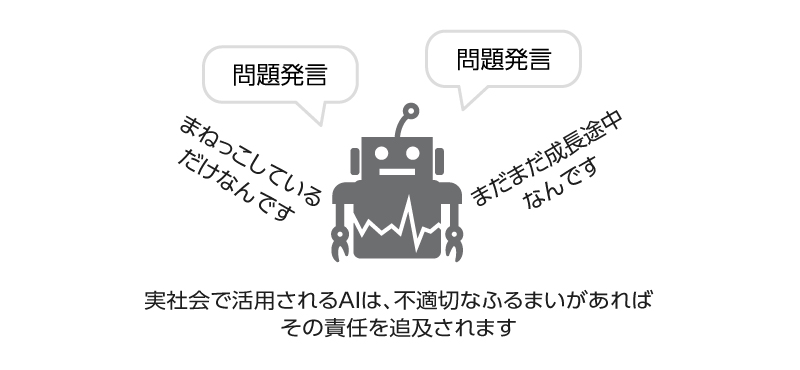
これらチャットボットの仕組みは、人が使っている言葉を取り込んで、自分でも使ってみる、という、小さい子どもが言葉を覚えるのと同じような学習です。小さい子どもが、覚えたての言葉をあまりにも率直に真似て発言してしまい、周囲を苦笑させるシーン、よくありますよね。子どもは、言ってみて、周囲にたしなめられて、その発言は不適切だった、と覚えていきます。無邪気な子どもであれば、多少、不適切な発言があっても、「まったく、しょうがないな…まだ、学びの途中だからね」と大目に見てもらえます。ですが、実社会の中で活用されるAIは、そうはいきません。不適切なふるまいがあれば、その責任を追及されるのです。
AIは、学習データ次第でそのふるまいが変化します。人間のふるまいをAIの学習データとするのはよくあるやり方ですが、大人のふるまいといえども子どもに真似られては不都合なこともあるように、AIに真似られては問題になることもあります。つまり、AIがユーザーから取り込んだデータをそのまま学習してアクションを起こすことには、注意が必要なのです。場合によっては、チャットボットにあえて悪い言葉を覚えさせようとする、悪意のあるユーザーもいるかもしれません。技術者のみなさんは、世界をより良くしようという熱意を持ってものづくりをしていると思いますが、AIが技術者の手を離れて出ていく世の中は、残念なことに、悪意がない世界だとは言えません。万が一のケースとして、悪意を持って使用されるというシナリオも想定しておく必要があるのです。これはどのようなシステムに対しても言える当たり前のことかもしれませんが、学習データをもとに自身のふるまいを決定するAIでは特に、学習データの汚染に注意した仕組みにしておく必要があります。
チャットボットの倫理リスクを分析してみましょう
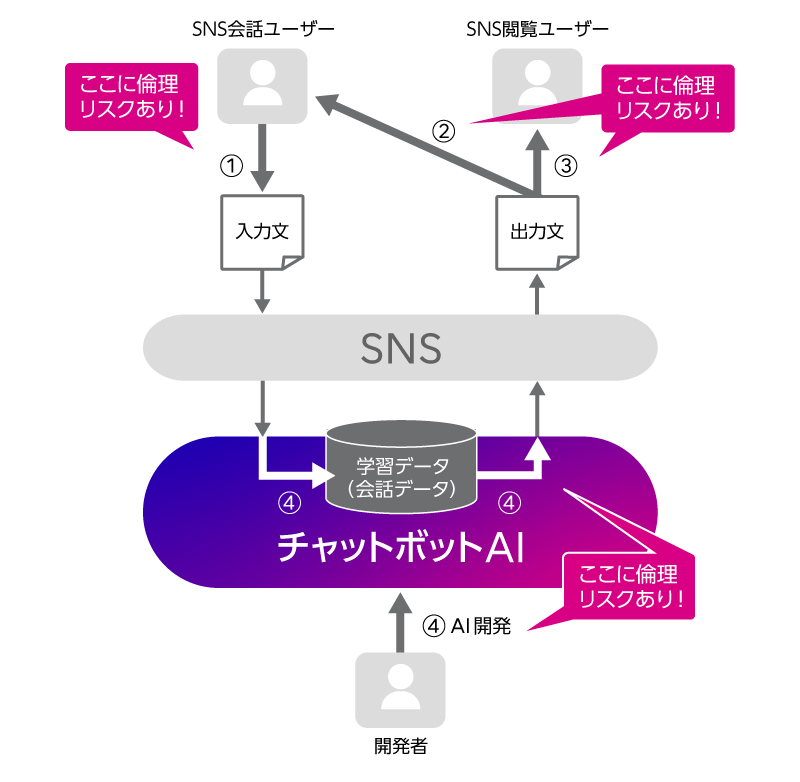
さて、今回のチャットボットの事例、SNS上のチャットボットであるとして、分析図で示すと、次のようになります。
チャットボットAIの開発をしているのが開発者、SNSを通じてチャットボットを利用するのがSNSユーザーです。会話はSNS上でオープンに行われている設定ですので、SNSユーザーには、チャットボットとの「会話ユーザー」の他に、会話を横から見ている「閲覧ユーザー」もいます。また、チャットボットとの会話ユーザーは複数名であることも想定できます。
今回の事例でAI倫理リスクがあるのは矢印①~④の部分です。まず矢印①、SNS会話ユーザーからの入力に、暴言や差別的発言など、不適切な文言が含まれる可能性があります。チャットボットを破壊する目的で、故意に悪意を持って入力される恐れもあります。すると、矢印②、SNS会話ユーザーに提示される出力において、チャットボットが人を不快にさせる不適切な発言をすることが起こりえます。人と楽しく会話するために世に送り出されたチャットボットが、一部の会話ユーザーの不適切な行為によって、いつの間にか暴言ばかり吐くようになるかもしれないのです。また、矢印③、SNS上でチャットボットの暴挙を見るのは、チャットボットと直接会話した会話ユーザーだけとは限りません。SNSを利用している多数の閲覧ユーザーにも、ひどいショックを与えかねません。そして、これらの①②③のリスクは、矢印④の部分にリスクがあることが関係しています。今回の事例では、運用しながら継続的に学習し続ける方法を採用しており、そこで、悪意のある入力シナリオの想定が不十分だったこと、矢印①で入力されたSNSユーザーとの会話を精査せずに学習データに加え出力に利用していること(④)が、①②③のリスクを生み出す要因となり得るのです。
実際はもっと細かい図を使って分析しており、ここに挙げた以外のインタラクションに紐づく倫理リスクも見えてきます。こうして、AI倫理リスク分析を行うことによって、どこに倫理リスクがあるのか見えてくれば、事前にそこに対処し、AIをうまく使っていくことができますね。
AI倫理リスクを理解するには、さらにいろいろな事例を見ることが役に立ちます。本連載でその勘所を掴んでいただければと思います。次回、別の事例もご紹介します。
もし、我々の研究に興味を持っていただけた方がいらっしゃいましたら、ぜひ、お気軽にお問い合わせください。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}