第1回の記事では、果物の等級評価AIの事例を使って、AI単体ではなく、登場人物(ステークホルダー)を含めた、AIの利用シーン全体を見る必要がある、というお話をしました。今回は、AIを活用した人材採用についての事例をご紹介します。
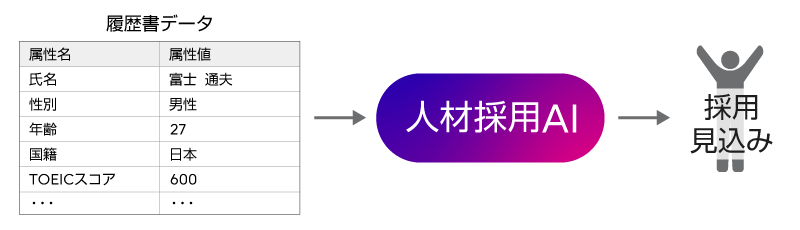
求人に対する応募者の履歴書審査にAIを用い、採用する有力候補を見つけようとするシーンを考えます。応募者数が何千、何万という単位だと、採用担当者が履歴書に目を通すだけでも大変な作業になるので、AIで少しでもその作業を支援できたら、というニーズがありますよね。ここで例に挙げる人材採用AIは、自社の過去の採用者/不採用者の履歴書を学習します。そして、求人応募に対する第1次書類選考として、新しい応募者の履歴書が入力されたら、AIが採用/不採用の見込みを判定します。その後、AIが「採用見込み」と判定した応募者を有力候補として、次の段階の面接に呼ぶ…という使い方が想定されます。
仮に、ITベンダーの求人にこの人材採用AIを導入した場合、どういう結果になったでしょうか? 求人応募者のうち、面接に呼ばれるのは、男性ばかり、ということが起きてしまいました。そうです、過去の採用者の多くが男性で、その履歴書データを学習したため、AIが過剰に男性優位の判定を行うようになってしまったのです。学習データに依存したふるまいをするAIの、わりとよくある失敗パターンで、AI技術者にとってはなじみの問題かもしれません。しかし、現実社会での雇用という重大な局面においては、あまりにも影響が大きい問題です。AIの判定によって、女性の応募者は、女性であるというだけでまず入り口でシャットアウトされ、面接にすら呼ばれません。著者の私たちは3人とも女性会社員ですから、そんな事態には震えが止まりません。そして、採用する側の企業・団体にとっても、女性の人材を採用できなくなる機会損失というだけではなく、男女差別をする不公平なAIを意識・無意識にかかわらず使っているとなれば、世間のバッシングを浴びることは免れないでしょう。
では、AIが男女差別をするのを防ぐには、どうすればよいでしょうか?男女の不公平が出ないよう、AIが学習および採用判定に利用する履歴書の項目(属性、と言います)のうち、性別欄の値をマスキングしてみましょう。これで、男女公平に判定できるようになったでしょうか。
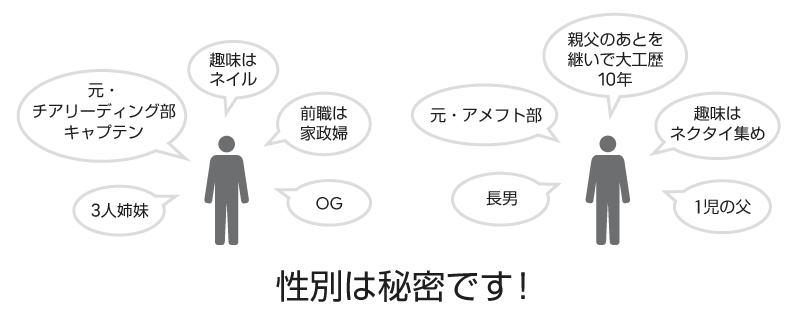
残念ながら、そう簡単ではありませんでした。今度は何がまずかったでしょうか。実は、履歴書中、性別欄以外にも、間接的に男女がわかってしまう情報が含まれていたのです。例えば、「女子○○部のキャプテンをしていた」という記述。これ、応募者はおそらく女性ですね。そして、出身校名が「△△女子大」。これもまず女性の可能性が高いですね。頭かくして尻かくさず…ということわざが頭をよぎった方もいらっしゃるのではないでしょうか。
では、「女子」「男子」というキーワードが出てきたら、その情報はマスキングするようにしてはどうでしょう。「相撲部」…うーん、男子というキーワードは含んでいませんが、おおかたは、男性でしょうね…。他にも、暗黙的に男性的/女性的とわかるボキャブラリーはいろいろありますね。これは一筋縄ではいかないな、と感じていただけたかと思います。
AIの設計・開発においては、AIに入力するデータとして、元データのうちどの属性を使うのか、「属性Xと属性Yを使う」と明示的にピックアップします(もしくは、属性をあるだけ全部使う、と明示的に指定します)。AI技術者にとってはそれが一般的な感覚で、使用する属性選びがAIの精度を左右するポイントだったりもします。しかし、現実の世界では、Aさんのデータは、全部Aさんの日々の生活から生み出されていて、紐づいているのです。元のデータから単独の属性だけを取り除き、残りの属性への影響を完全に残さないことは難しいのです。今回の事例で挙げた性別の他、国籍や人種のように、明らかに不公平が生じてはならない属性のことをセンシティブ属性と言いますが、状況によって、センシティブ属性の中身を間接的に推測できてしまう場合がある「かくれセンシティブ属性」が、そこかしこに潜んでいます。先の例でいえば、性別をかくしても、学生時代の部活や出身校やその他の属性から、性別が推測できてしまうケースがあるわけです。この「状況によって」というかくれ具合が厄介な点です。常時この属性はマスキングするべき、とは特定できないからです。近年、実際にあったAI人材採用の実事例でも、こういった影響が取り除ききれず、残念ながら、プロジェクトは打ち切りになったそうです。AIを社会実装するときには、現実ではデータの各属性の影響を完全に切り離すことは難しく、データのかくれセンシティブ属性に配慮する必要があるということを覚えておいていただければと思います。つまり、AIを設計・開発する時点から、これらのAI倫理リスクを考慮する必要がある、というわけです。AI倫理は、精度の良いAIが完成した後で、余裕があれば考慮しようか、というものではないということです。
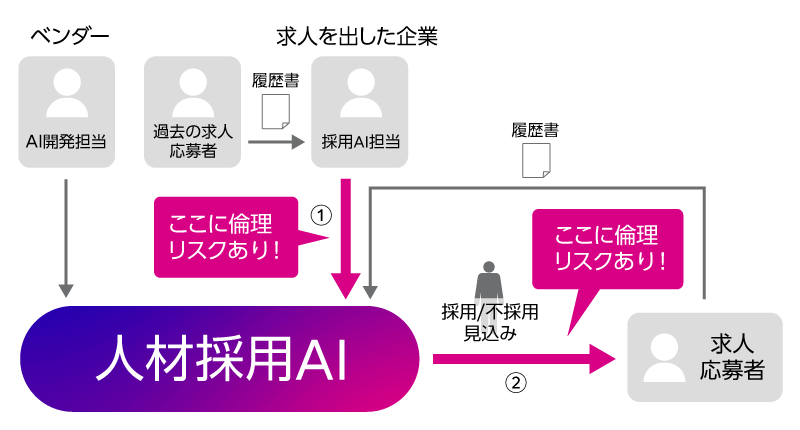
富士通では、ステークホルダーとAIのインタラクションに着目し、各インタラクションにひそむ倫理リスクを示す、AI倫理リスク分析技術を開発しています。今回の人材採用AIの利用シーンを分析図で示すと、次のようになります。人マークがステークホルダー、矢印はステークホルダー間およびステークホルダーとAI間のインタラクションです。このインタラクションに、倫理リスクを紐づけて表現しています。人材採用AIのシーンで倫理リスクがあるのは2か所です。①求人を出している企業の採用AI担当者から人材採用AIの部分です。採用AI担当者が学習データとして用意した過去の採用者データが、男性のものばかりに偏っていました。➁は、人材採用AIから求人応募者の部分です。男性の応募者には過剰に採用見込み判定が出てしまう一方で、女性の応募者には不採用見込みの判定ばかりが出て、次の面接に呼ばれないという影響がありました。実際はもっと細かい図を使って分析しており、ここに挙げた以外のインタラクションに紐づく倫理リスクも見えてきます。こうして、AI倫理リスク分析によって、どこに倫理リスクがあるのか見えてくれば、事前にそこに対処し、AIをうまく使っていくことができますね。
ここで、第1回でご紹介した、農業団体での果物の等級評価事例を、あらためて振り返ってみると、実は同じ視点を含んでいます。AIは果物の画像だけを見ていますが、現実の果物は画像データとしてではなく、農家Aさんが丹精込めて作った果物として存在しています。AIが使うデータには含まれていなかったとしても、人間から見れば、現実の果物には、背景にある属性として「農家さんの名前」の情報がついているとも言えます。そのかくれ属性である農家さんの情報が、意図しないトラブルを生んでしまう可能性がある、という言い方もできるのです。つまり、本記事タイトルの「かくれ属性の影響」とは、人材採用AIの例で挙げた「かくれセンシティブ属性」だけではなく、「システム的なデータ上にはないが現実には背景にかくれている、モノやヒトについての関連属性」という意味も含んでいます。
AI倫理リスクを理解するには、さらにいろいろな事例を見ることが役に立ちます。本連載でその勘所を掴んでいただければと思いますので、次回、別の事例もご紹介します。
もし、我々の研究に興味を持っていただけた方がいらっしゃいましたら、ぜひ、お気軽にお問い合わせください。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}