

データベースシステムの監視 ~監視方法と監視例~
PostgreSQLインサイド
データベースシステムの監視の重要性については、「データベースシステムの監視 ~監視の概要~」で説明しました。ここでは、「死活監視、状態監視」、「メッセージ監視」、「容量監視」、「性能監視」に利用するコマンド、関数、統計情報ビューと、それらの実行例について説明します。なお、この記事は、PostgreSQL 11.1をベースに作成しています。また、Linuxを前提としています。
1. 死活監視、状態監視
サーバーとPostgreSQLの死活監視および状態監視は、OSのコマンドおよびPostgreSQLのコマンドで行います。以下に監視方法を示します。なお、表中の記号「N/A」は機能無しを意味しています。
| 分類 | 監視内容 | 監視方法 | |
|---|---|---|---|
| OS | PostgreSQL | ||
| 死活監視 | サーバーOSの応答 | pingコマンド | N/A |
| PostgreSQLプロセスの有無 | psコマンド | pg_isreadyコマンド | |
| SQL実行可否(SQLが正常に実行できるか確認) | N/A | 「SELECT 1」などの簡単なSQLを実行 | |
| 状態監視 | CPU使用率 | sarコマンド vmstatコマンド mpstatコマンド |
N/A |
| メモリー使用率 | freeコマンド vmstatコマンド |
N/A | |
| I/Oビジー率 | sarコマンド iostatコマンド |
N/A | |
| ネットワーク帯域使用状況 | sarコマンド | N/A | |
各コマンドで示すオプションは一例になりますので、監視の方針に沿って他の有用なオプションとの併用も検討してください。コマンドの戻り値は、シェルスクリプトで確認するときに利用してください。
サーバーOSの応答(pingコマンド)
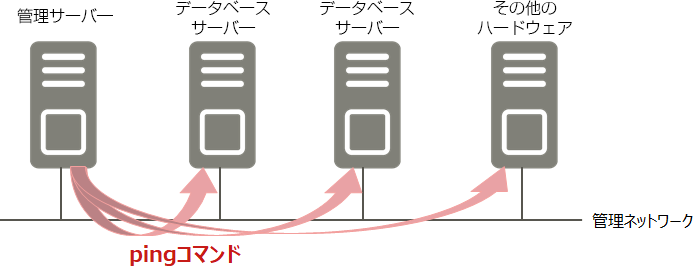
サーバーの死活監視は、OSの「ping コマンド」に「-cオプション」を指定して確認します。例のように「1」を指定すると1回試行します。ネットワークの一時的な断線などの影響を受けないようにするため、数回リトライするようにしてください。サーバーが動作している場合は、「1 packets transmitted, 1 received」と表示され、応答があったことがわかります。pingコマンドの戻り値は、0:応答を受信した、0以外:応答を受信できない、または、エラーです。
pingコマンドは、管理サーバーなどの別サーバーから実行してください。
PostgreSQLプロセスの有無(psコマンド)
PostgreSQLの死活監視は、規定のPostgreSQLプロセスが存在することを、OSの「psコマンド」を使用して確認します。PostgreSQLでは、マスタープロセス(postmasterプロセス)の監視を推奨します。他のpostgres子プロセスの監視は必要ありません。一時的にマスタープロセスが2つ以上存在することがあるため、マスタープロセス数が1以上のときを正常としてください。
psコマンドは、PostgreSQLデータベースサーバー上で実行してください。

PostgreSQLプロセスの有無(pg_isreadyコマンド)
PostgreSQLの死活監視は、PostgreSQLの「pg_isreadyコマンド」でも確認することができます。PostgreSQLサーバーの接続状態を検査することで、PostgreSQLプロセスの有無を確認することができる簡易的なコマンドです。pg_isreadyコマンドの戻り値は、0:接続を受け付けている、1:サーバーが接続を拒絶している、2:応答がない、3:無効なパラメーターなどにより試行が行われないです。
pg_isreadyコマンドは、PostgreSQLクライアント(別マシン)からも実行できます。

SQL実行可否(「SELECT 1」などの簡単なSQLを実行)
最低限のSQLが実行できるか、「psql –c」で簡単なSQLを実行して確認します。ここでは、「SELECT 1」を実行し、適切な結果が返ることを確認します。psqlコマンドの戻り値は、0:正常、0以外:異常です。
psqlコマンドは、PostgreSQLクライアント(別マシン)からも実行できます。

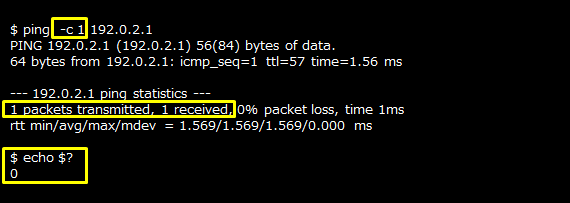
CPU使用率(sarコマンド)
CPU使用率は、OSの「sarコマンド」を使用して確認します。全体を取得する場合は「-uオプション」を、コア単位に取得する場合は「-P ALL」を指定します。例のように、「1 60」と指定すると、「1秒おきに60回」取得することができます。CPU使用率は、「%user」(ユーザーが利用しているCPU使用率)、「%nice」(nice値を変更しているプロセスのCPU使用率)、「%system」(システムが利用しているCPU使用率)で確認することができます。「%user」が上昇している場合、特定のアプリケーションでCPUが消費されている可能性があるので、psコマンドなどで対象のアプリケーションを確認してください。
sarコマンドは、PostgreSQLデータベースサーバー上で実行してください。
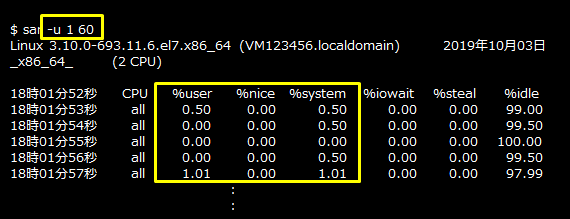
メモリー使用率(freeコマンド)
メモリー使用率は、OSの「freeコマンド」を使用して確認します。バイト単位での表示では見にくいので、メガバイト単位で表示する「-mオプション」と、物理メモリーとスワップメモリーの合計を表示する「-tオプション」を指定します。メモリー使用率は、「total」(総容量)と「available」(スワップせずに利用可能と見積もられたメモリー)を使用し、「メモリー使用率 =((total - available)÷ total × 100)」で確認することができます。
freeコマンドは、PostgreSQLデータベースサーバー上で実行してください。
-
備考availableは、Red Hat® Enterprise Linux® 7から追加された項目です。
I/Oビジー率(iostatコマンド)
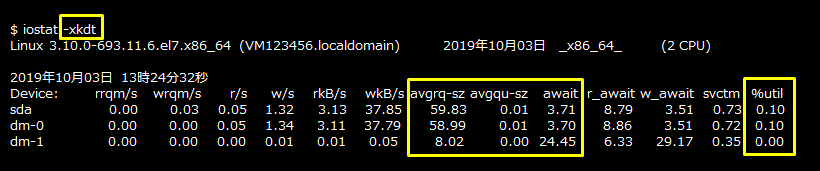
ディスクごとのI/Oに関する情報は、OSの「iostatコマンド」を使用して確認します。デフォルトで、CPU統計とディスク統計が表示されます。「-xオプション」を指定することで、より詳細なディスクの統計データを表示することができます。I/Oビジー率は「%util」(デバイスの帯域幅使用率)で確認することができます。また、「avgrq-sz」(リクエストの平均サイズ)、「avgqu-sz」(リクエストの平均キュー長)、「await」(リクエストの平均待ち時間(ミリ秒))から具体的な状況を確認することもできます。
iostatコマンドは、PostgreSQLデータベースサーバー上で実行してください。
ネットワーク帯域使用状況(sarコマンド)
ネットワーク帯域に関する情報は、OSの「sarコマンド」に「-n DEVオプション」を指定して確認します。伝送路の使用状況は、「rxpck/s」(1秒間に受信したパケット数)、「txpck/s」(1秒間に送信されたパケット数)、「rxkB/s」(1秒間に受信したパケットのキロバイト数)、「txkB/s」(1秒間に送信されたパケットのキロバイト数)で確認することができます。
sarコマンドは、PostgreSQLデータベースサーバー上で実行してください。

2. メッセージ監視
PostgreSQLは、インフォメーションやエラーなどのメッセージをサーバーログに出力しています。このログの内容を監視することで、エラーが発生した場合は、メッセージからエラー原因の分析を行い、対処することができます。
監視項目
メッセージには、発生した問題の深刻度ごとに「メッセージレベル」が設定されます。「PANIC」「FATAL」「ERROR」はデータベースの安定稼働に影響する可能性があるため、この3つの監視をお勧めします。性能に関する監視を行う場合は、「LOG」も監視対象としてください。メッセージレベルと、レベルごとの意味を以下に示します。postgresql.confの設定によりログの出力先をsyslogに変更した場合、メッセージレベルは表のsyslog欄のレベルに変換されます。
| メッセージレベル(深刻度) | 意味 | syslog |
|---|---|---|
| PANIC | すべてのデータベースセッションを中断させる原因となったエラーの情報 | CRIT |
| FATAL | 現在のセッションを中断させる原因となったエラーの情報 | ERR |
| LOG | チェックポイントの活動のような、管理者が把握すべき情報 | INFO |
| ERROR | 現在のコマンドを中断させる原因となったエラーの情報 | WARNING |
| WARNING | トランザクションブロック外でのCOMMITのようなユーザーへの警告情報 | NOTICE |
| NOTICE | 長い識別子の切り詰めに関する注意など、ユーザーの補助になる情報 | NOTICE |
| INFO | VACUUM VERBOSEの出力などの、ユーザーによって暗黙的に要求された情報 | INFO |
| DEBUG1からDEBUG5 | 開発者が使用する連続的で詳細な情報 | DEBUG |
以下にメッセージ例を示します。
例1
接続拒否(pg_hba.conf外からの接続に対してのメッセージ)

例2
ルールに反した接続(テーブルアクセス権限なし)

ポイント
エラーが発生した場合、ログに記録される「メッセージ」が、原因の特定や分析に役立ちます。また、PostgreSQLでは、エラーメッセージのほかにエラーの発生箇所やヒント情報をログに出力します。これらを利用して、エラーの分析や調査を行ってください。
| カテゴリー | 内容 |
|---|---|
| STATEMENT | エラー起因となった実際の処理内容 |
| LOCATION | エラーが発生したコード上の位置 |
| HINT | 発生したエラーの原因や回避策 |
| CONTEXT | エラーが発生したコンテキスト(関数など) |
ログ出力の設定
メッセージ監視をするためには、メッセージをログファイルに書き出すように設定しておく必要があります。以下にメッセージ監視に必要な主なpostgresql.confのパラメーターを示します。
ログの出力先
- log_destination(ログの出力先)
- logging_collector(ログメッセージの内容をファイルに保存するかどうか)
- log_directory(ログファイルを格納するディレクトリー)
- log_filename(ログファイル名)
いつログを取得するか
- log_min_messages(サーバーログに書き込むメッセージのレベル)
- log_min_error_statement(エラー原因のSQLをサーバーログに書き込むメッセージのレベル)
- log_min_duration_statement(設定時間以上かかったSQL文のみをサーバーログに書き込む)
何をログに出力するか
- log_checkpoints(チェックポイントおよびリスタートポイトに関する情報の出力の有無)
- log_connections(サーバーへの接続に関する情報の出力の有無)
- log_disconnections(サーバーの切断に関する情報の出力の有無)
- log_lock_waits(ロック獲得のために一定期間以上待たされたときの情報の出力の有無)
3. 容量監視
データベースクラスタ領域(PGDATA環境変数で指定したディレクトリー)、TABLESPACE領域、アーカイブしたトランザクションログ(WAL:Write-Ahead Log)を格納しておく領域のディスク容量が足りなくなると、以下のような支障をきたします。
- データの更新ができなくなる
- 新しいデータベースやテーブルが作成できなくなる
- WALのディスク容量不足になると強制終了する
- データやWALが破損する可能性がある
これらの問題を防ぐために、ディスクの使用率や空き容量を監視してください。そして、容量不足を起こす前に以下のような対処を行ってください。
- 不要なファイルの削除
- テーブル空間の機能を用いて、データベースや表などを複数のディスクに分散配置
- インデックスの肥大化が発生している場合は、REINDEXによるインデックスの再編成
- バックアップを実施することによって不要なアーカイブログの削除
- 新しいディスクを増設して、データを移動
例えば、他のツールと連携して「ディスクの空き容量が20%未満になったらアラームを挙げる」などの設定をしておくことで、容量不足を起こす前にディスクを増設するといった対処をすることができます。この「20%」という閾値は、対処する時間も考慮して、余裕をもった値に設定してください。
PostgreSQLが扱うファイルで監視すべきものを以下に示します。なお、表中の記号「N/A」は機能無しを意味しています。
| 監視データ | 監視対象(ディレクトリー名) | 監視方法 | |
|---|---|---|---|
| OS | PostgreSQL | ||
| 各テーブルやインデックス | $PGDATA/base | duコマンド lsコマンド |
pg_database_size関数 pg_total_relation_size関数 pg_table_size関数 pg_indexes_size関数 |
| テーブル空間(TABLESPACE)用に指定されたディレクトリー | pg_tablespace_size関数 | ||
| ディスクソートやハッシュ処理などの一時領域 | $PGDATA/base/pgsql_tmp | N/A | |
| サーバーログ | $PGDATA/log(注1) | ||
| syslog | /var/log(注2) | ||
| WAL | $PGDATA/pg_wal | ||
| WALアーカイブ | WALアーカイブ用に指定されたディレクトリー | ||
-
備考$PGDATA:データベースクラスタのディレクトリーです。
-
(注1)postgresql.confのlog_directoryパラメーターで変更できます。
-
(注2)/etc/syslog.confまたは/etc/rsyslog.confで変更できます。
運用時のポイント
例えば、以下のSQLコマンドを実行する場合は、ディスクの空き容量に注意が必要です。
- VACCUMを実行
WALが大量に出力されるため、「$PGDATA/pg_wal」の監視が必要です。 - REINDEXやALTER TABLEを実行
対象のテーブルやインデックスがあるディレクトリーを圧迫するため、「$PGDATA/base」の監視が必要です。また、WALが大量に出力されるため、「$PGDATA/pg_wal」の監視が必要です。
ここでは、「duコマンド」と「pg_database_size関数」を例にとって説明します。
duコマンド
ディスクの使用量は、OSの「duコマンド」を使用して確認します。すべてのシンボリックを辿れるように「-Lオプション」を指定します。また、サイズの表示単位を、「-k」(キロバイト単位)または「-m」(メガバイト単位)で指定します。以下のように指定することで、$PGDATA配下のディスク使用量を、メガバイト単位で表示することができます。

pg_database_size関数
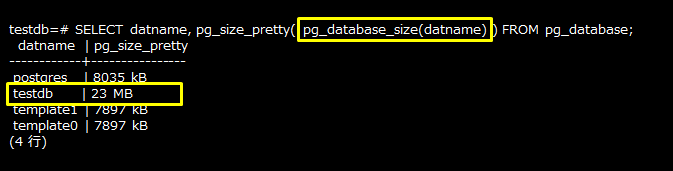
データベースで使用されるディスク容量は、PostgreSQLの「pg_database_size関数」を使用して確認します。データベースの情報が格納されているシステムカタログ(pg_database)から、データベースで使用されるディスク容量を取得し、サイズの単位をつけた書式に変換して表示します。
参考
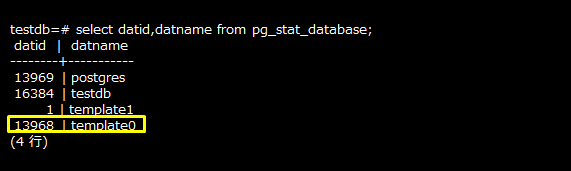
データベースで使用されるディスク容量をduコマンドで確認する場合は、ディスクの使用量を確認する前にどのデータベースがどのoidかを調べ、その値を元に確認します。以下の例では、「testdb」のoidは「16384」とわかります。先に説明したduコマンドの結果を見ると、「./$PGDATA/base/16384」のディスクの使用量は「23」となっており、pg_database_size関数の結果と一致します。
4. 性能監視
性能に関する情報は、差分を見ることができるよう定期的に取得してください。最低でも1日1回の情報取得をお勧めします。監視の間隔については、「データベースシステムの監視 ~監視の概要~」の「3.2 監視間隔、異常とみなす値(閾値)」を参照してください。
PostgreSQLの「統計情報ビュー」には、稼働状況に関するさまざまな情報を収集し蓄積しています。「統計情報ビュー」を監視することで、性能に関する情報が取得できます。
| 監視対象 | 監視方法 |
|---|---|
| 遅いクエリの有無 | pg_stat_statementsビュー |
| 長時間放置されているトランザクション有無 | pg_stat_activityビュー |
| ロック待ち時間の長いクエリ有無 | pg_locksビュー pg_stat_activityビュー pg_classカタログ |
| 同時接続数 | pg_stat_activiryビュー |
| スループット(commit/rollback回数) | pg_stat_databaseビュー |
| レプリケーションの遅延状況(レプリケーション構成の場合) | pg_stat_replicationビュー pg_stat_wal_receiverビュー |
| 不要領域(データの挿入や削除によって発生した空き領域) | pg_stat_all_tablesビュー |
| インデックスのばらつき(インデックスの並び順とテーブルの並び順が揃っているか) | pg_statsビュー |
ポイント
統計情報ビューを表示する場合、表示形式のデフォルトは横長な状態のため、列数が多いと1行が折り返されて見づらくなってしまいます。メタコマンドで拡張テーブル形式モード(¥x)を有効にすることで、縦表示に変更することができ、見やすくなります。元に戻すときは、再度「¥x」を実行してください。

ここでは、「pg_stat_statementsビュー」、「pg_stat_activityビュー」、「pg_stat_databaseビュー」を例にとって説明します。
pg_stat_statementsビュー
「pg_stat_statementsビュー」を使用することで、遅いクエリの有無を確認することができます。「userid」(SQL文を実行したユーザーのOID)、「query」(実行されたSQL文)、「calls」(SQL文の実行回数)、「total_time(注1)」(SQL文の実行に費やした総時間)を確認することができます。
pg_stat_statementsビューを利用した例は、「チューニング ~ SQLチューニングの概要 ~」の「3.1 統計情報ビューを利用して検出する方法」および「チューニング ~ SQLチューニングを実施する ~」の「2. 処理が遅いSQLを検出」を参照してください。
-
注1PostgreSQL 13から、パラメーター名がtotal_exec_timeに変更されました。
pg_stat_activityビュー
「pg_stat_activityビュー」を使用することで、長時間放置されているトランザクションの有無や、同時接続数などを確認することができます。長時間放置されているトランザクションの有無は、「xact_start」(トランザクションが開始した時刻)を確認してください。トランザクション実行中でなければ値は入りません。何か値が入っていて長時間経過していれば、長時間放置されているということになります。同時接続数の確認は、pg_stat_activityビューの行数([RECORD x]の数)を確認してください。
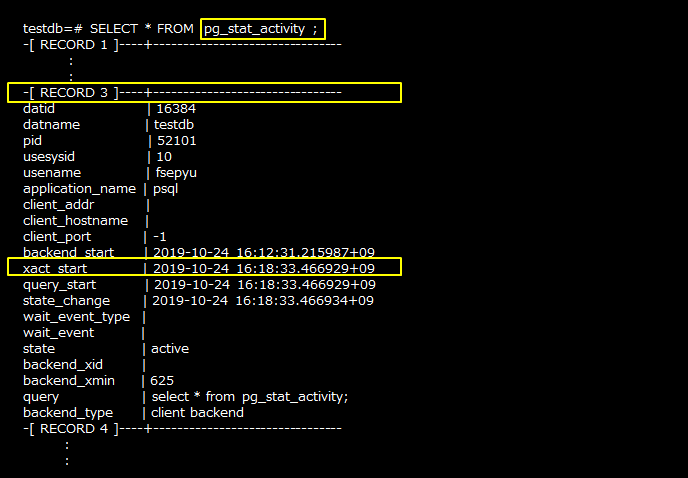
pg_stat_activityには他にも、「backend_start」(プロセスが開始した時刻)、「query_start」(クエリが開始した時刻)、「wait_event_type」(待機の状態)、「wait_event」(待機イベント名)、「state」(プロセスの状態)、「query」(最後に実行したクエリ)、「backend_type」(バックエンドの種別)のような、確認しておくべき項目がたくさんあります。これらも併せて確認してください。
ポイント
「state」(プロセスの状態)に表示される値と状態を以下に示します。
| 値 | 状態 |
|---|---|
| active | 問い合わせを実行中です。 |
| idle | 新しいクライアントからのコマンドを待機しています。 |
| idle in transaction | トランザクションブロック内にいますが、現在実行中の問い合わせがありません。 |
| idle in transaction(aborted) | idle in transactionと似ていますが、トランザクション内のある文がエラーになっています。 |
| fastpath function call | 近道関数(近道インターフェイスを利用する関数)を実行中です。 |
| disabled | track_activitiesが無効(off)になっています。 |
pg_stat_databaseビュー
「pg_stat_databaseビュー」を使用することで、コミットやロールバック回数を確認することができるため、スループットを算出することができます。「xact_commit」(コミットされたトランザクション数)、「xact_rollback」(ロールバックされたトランザクション数)を定期的に取得してください。この情報を元に、「((今回取得時のxact_commit)-(前回取得時のxact_commit))÷ 情報取得間隔の時間」の計算をすることで、「単位時間あたりのコミット数」を確認することができます。同様に、「単位時間あたりのロールバック数」も計算し、確認してください。
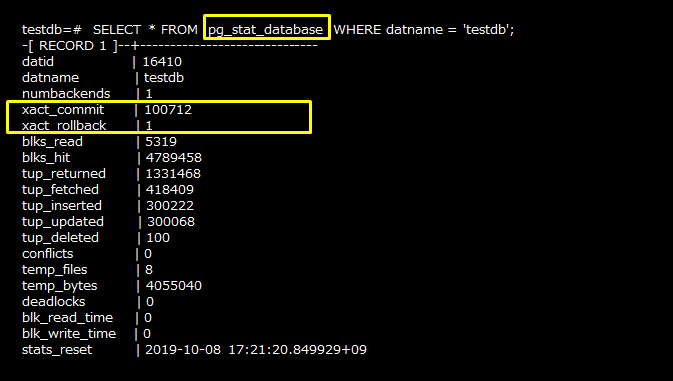
また、「blks_read」(共用メモリーに無かったブロックの読み込み回数)と、「blks_hit」(共用メモリーにあったブロックの読み込み回数)を利用することで、キャッシュヒット率を算出することができます。メモリーチューニングでは、これを100に近づけることを目標とします。

データベースシステムのどのような情報を、どのように監視すれば良いのか、「監視対象」と「監視方法」に着目して説明しました。データベースシステムの要件に応じて様々な観点で監視を行うことで、異常やその兆候をより早く検出することができます。
可用性の高いシステムを実現するには、データベースシステムが安定稼動している状態を知り、その状態が維持されていることを監視し、異常時の対策を十分に行っておくことが重要です。
2021年1月22日更新
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


