

PostgreSQLのデータ圧縮を提案してきました!~PGConf.EU 2019参加レポート~
PostgreSQLインサイド


岩田 彩
富士通株式会社
ソフトウェア事業本部 データマネジメント事業部
専門分野
- データベース
2016年からPostgreSQLをベースとした「FUJITSU Software Enterprise Postgres」の開発業務に従事するとともに、PostgreSQLコミュニティー、Npgsqlコミュニティーでの活動にも参加。
2019年10月に、PostgreSQLの国際カンファレンスであるPostgreSQL Conference Europe(以降、PGConf.EUと略記、特定のPostgreSQL Conferenceに依存しない場合はPGConfと略記します)が開催されました。本特集では、当社から発表者として参加した「岩田 彩」が、参加のきっかけや、聴講したセッション内容、提案したデータ圧縮について紹介します。
PGConf.EU参加のきっかけ
はじめに、PGConfはどのようなイベントなのか教えてください。
岩田
PGConfは、PostgreSQLのイベントの一つとして世界各地で開催されています。例えば、アジア地域ではPGConf.ASIAが毎年開催されていて、2018年までは東京で、2019年はインドネシアのバリ島で開催されました。PGConfでは、新機能や議論中の機能に関する紹介、トレーニングなど、開発者だけでなく利用者にも有益な情報が紹介されています。今回、私はイタリアのミラノで開催されたPGConf.EU 2019に参加しました。
PostgreSQLに関するいろいろな情報が紹介されるイベントなのですね。参加しようと思ったきっかけは何でしょうか。
岩田
PostgreSQLにデータ圧縮機能を追加したいと考えており、まずこの提案を多くの方に知ってもらうためにPGConfでの発表を目指しました。PostgreSQLのコミュニティーに機能の追加を提案する場合、提案に対する賛同者を集めて、議論を立ち上げることから始めます。このため、少しでも多くの方にこの提案を知ってもらい、さまざまな角度からの意見やアドバイスをいただくことで、議論への第一歩に繋げたいと思いました。
PGConfは世界各地で開催されると伺いましたが、なぜPGConf.EUを発表の場に選ばれたのでしょうか。
岩田
より多くの意見や賛同をいただいて議論につなげるために、参加者が多いイベントで発表したいと思いました。その場所としてPGConf.EUを選びました。ヨーロッパは、PostgreSQLを利用する企業が多く、技術者もたくさんいらっしゃいます。PGConf.EUには、コミュニティーの参加者に限らず、利用者や企業関係者も多く参加されるため、コミュニティー内外からより多くの意見をいただけると思いました。2019年は、前年を上回る500名以上の登録者数で、実際に会場にも大勢いらっしゃって、大いに盛り上がっていました。
もう一つの理由として、コミッターやコントリビューターにはヨーロッパ在住の方が多く、PGConf.EUへの参加率も高いと聞いていたため、彼らと直接お話しして意見を交わせる機会を持ちたいとも思いました。
参加によりコミュニティー活動への意欲が高まる
実際にコミッターの方とお話しできたのですか。
岩田
はい。思っていた以上にコミッターの方と直接議論する機会がありました。今までの会話はメールだけでしたが、実際に顔を合わせることで人柄が感じられ、議論を交わしやすくなりました。言葉の壁はありますが、コミュニティーでもこれまで以上に積極的に議論に参加したいと思いました。
PGConf.EUに参加した甲斐がありましたね。
セッションにはどのようなものがあったのでしょうか。
岩田
今回はPostgreSQL 12がリリースされた直後ということもあり、PostgreSQL 12関連のセッションが多かったです。性能評価に関するセッションなどもありましたし、管理やチューニングなどのユーザー向けのセッションや、OracleやMySQLなどからの移行をテーマにしたセッションも多くありましたね。
PostgreSQL 12の情報もそうですが、皆さんやはり新機能など最新動向に興味があるようで、PostgreSQL 13以降で入る機能のセッションは人気がありました。特にコミュニティーで活躍している方々による新機能や内部構造のセッションは人気でした。
どのようなセッションを聴講されましたか。
岩田
興味深いものがたくさんありましたが、私が提案したデータ圧縮に関係するカラムナ格納(「ZedStore - Column store for PostgreSQL」)のセッションに参加しました。Zedstoreは現在コミュニティーでもホットな話題であるため、満席に近く、注目度の高さが伺えました。Zedstoreは、タイトルのとおりPostgreSQLにカラムナ(列指向)の格納を実現する取組みです。カラムナ格納に対応することで、分析や集計用途での利用も広がると思います。セッションでは、目標として、特定のクエリにおいてheapや他のカラムナ格納の製品よりも高速でありデータが十分に圧縮できること、現在のPostgreSQLの構造に合わせた作りでTable Access Method Interfaceにプラグインすることなどが掲げられていました。まだ他のカラムナ格納の製品には勝てていないものの、すでにheapよりは高速で、デモではその状況も紹介されました。データ圧縮のデモもあり、多少バラつきがあったものの概ね効果的な圧縮ができていることがわかりました。
-
heap:PostgreSQLの追記型構造のテーブルの呼び名。
カラムナへの関心が高いのですね。他にはどのようなものを聴講されましたか。
岩田
シャーディングのセッション(「Community roadmap to sharding」)や、障害原因を効率的に把握するためのアプローチをレクチャーしてくれるセッション(「What's wrong with Postgres」)などを聴講しました。
その他に興味深かったのは、Postgres Womenという団体のセッション(「Postgres Women: what is it, why does it matter and what can everyone do about it?」)で、女性や民族などのPostgreSQLコミュニティーにおけるマイノリティの参加/貢献を促進するアイディアなどが提案されていました。他のセッションとは異なる切り口のテーマが非常に興味深かったです。Postgres Womenの活動もあって、コミュニティーのマイノリティの比率や、EUのカンファレンスにおける女性の登壇率は上がってきているそうですが、私の印象では、日本で活動している女性はまだまだ少ないので、ぜひ増やしていきたいと思いました。
Postgres Womenですか。ぜひ頑張っていただきたいですね。
データ圧縮への強い思い
それでは、今回提案された内容について伺います。
データ圧縮を提案しようと思ったきっかけをお聞かせください。
岩田
はい。近年クラウド指向が急速に高まっていますが、当社のお客様からもシステムをクラウドに構築したいという要望が増えてきています。ただ、クラウドはディスク容量に応じて課金されるため、配置するデータ容量がコストに直結します。圧縮によってデータ容量を小さくできれば、その分コストを抑えることができると考えました。また、圧縮によってディスクI/Oを削減できれば性能向上も期待できます。

登壇の様子
企業にとってクラウド活用は欠かせなくなっていますからね。
現在のPostgreSQLには圧縮機能はないのでしょうか。
岩田
WALを圧縮する機能や、PostgreSQLにおける固定長のページサイズである8キロバイトを超える大きなデータを格納するためのTOAST(The Oversized-Attribute Storage Technique)という圧縮機能などがあります。TOASTは、現在も改良中で、データの種類に合わせて圧縮アルゴリズムを選択できる機能や、データを取り出す際に、部分的に解凍して高速に抽出する機能などが開発されています。
PostgreSQLに実装済みもしくは開発中の圧縮機能と、今回提案した圧縮機能では、何が違うのでしょうか。
岩田
WALの圧縮や、TOASTのように大きな1つのデータを圧縮格納することは重要ですが、データベース全体で見ると部分的な圧縮に留まります。これに対して、先ほど開発中の機能としてご紹介したZedstoreのデータ圧縮は、テーブルデータ全体を圧縮し、データ容量を小さくできる機能です。今回の提案も、Zedstoreのようにテーブルデータ全体を圧縮する機能です。Zedstoreがカラムナ格納であるのに対して、現在のPostgreSQLの行指向の格納構造に対するデータ圧縮になります。クラウド利用以外にも、処理するデータの数が多い場合に効果が得られることになると思います。
行指向のテーブルデータの圧縮とはどのような機能になるのでしょうか。
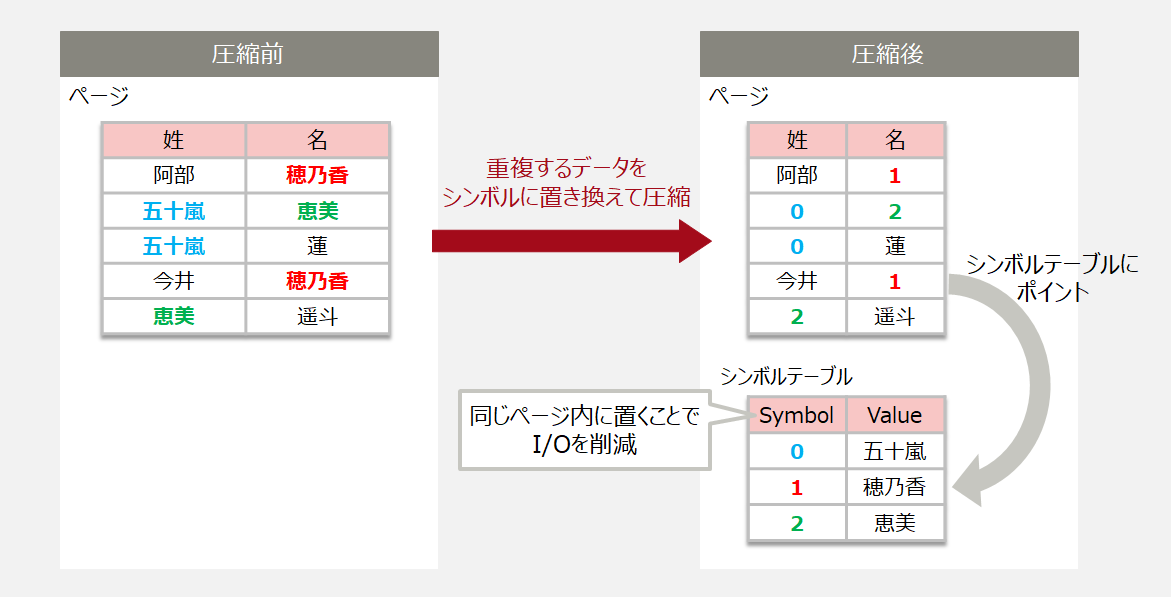
岩田
テーブル内の複数の列にまたがって重複するデータをシンボルに置き換えて、データのサイズを小さくすることを考えています。シンボルに置き換えたデータはシンボルテーブルにポイントしておきます。このシンボルテーブルと圧縮データを同じページに保存しておくことで、シンボルを検索するための余分なI/Oを無くすようにして、圧縮による性能の劣化を防ぎます。使い方もシンプルで、テーブルスペース単位やテーブル単位で、CREATE文やALTER文で設定できるようにします。実際にベンチマーク用のJpetStoreというWebショッピングのアプリケーションで検証してみたところ、受注の一時データが格納されている受注テーブルで、21KBのデータが12KBと約50%に圧縮できました。提案の詳細は、PGConf.EUのウェブサイトで公開していますので、ご興味があれば資料をご覧ください。
効果が見込めそうですね。
ところでメモリー上のデータも圧縮されたままなのでしょうか。
岩田
はい、メモリーにも圧縮したまま載せます。ですので、これまでよりもメモリー量を削減できますし、メモリー量はそのままにして、たくさんのデータを載せることもできるようになります。さらにいま、富士通からコミュニティーに対して、PostgreSQLのメモリー領域を効率的に使用するための機能「Shared system catalog cache(システムカタログのキャッシュの共有)」を提案中です。このShared system catalog cacheとデータ圧縮の両方が実現できれば、その効果はかなり大きなものになると思います。
ディスク領域だけでなく、メモリー領域の効率的な活用も期待できるのですね。
発表後の反応はいかがでしたか。
岩田
多くの方から「作ってください」とか「いつ使えますか?」という連絡をいただきました。当社のお客様だけでなく、PostgreSQLを利用する皆さんの要望が見えたというか、求められている機能だとわかり、PostgreSQLに早く実装して、ユーザーの方が使えるようにしたいという気持ちが強くなりました。
それは大きな励みになりますね。
岩田
はい。実装に向けて、今後さらにいろいろなご意見をいただくことで使いやすい機能に成長させて、いち早く皆さんにお届けしたいです。
ますますのご活躍を期待しています。本日はありがとうございました。
PGConf.EU 2019 オフィシャルウェブサイト
岩田より提案した内容の詳細は、PGConf.EUのウェブサイトで公開していますのでご覧ください。
2020年2月28日公開
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


