

リレーションバッファー削除の最適化によるリカバリーの高速化 – PostgreSQL 14でコミットされた機能の先行紹介:技術者Blog
PostgreSQLインサイド


Kirk Jamison
FUJITSU Limited
Software Products Business Unit Data Management Division
はじめに
富士通のグローバルPostgreSQL開発チームは、PostgreSQLの次期バージョンで実装される最新機能についてのブログをシリーズで公開しています。私は富士通PostgreSQLチームのシニアディレクターであるAmit Kapilaが率いるコミュニティー活動に専念する、このチームのメンバーです。このブログでは、PostgreSQL 14で提供される予定の機能改善について紹介したいと思います。
関連情報
背景 - リレーションバッファーの削除とバッファー・プールのスキャン
Kirk
近年のデータ大量化に伴い、大きな共有バッファー(shared_buffers)が設定されたシステムは、より一般的になってきています。大きな共有バッファーが設定されている場合、VACUUMやTRUNCATEのようなリレーションバッファーを削除するコマンドのフェイルオーバーやWALの再実行には、バッファー・プール全体をスキャンしなければならないため、非常に長い時間がかかることがあります。
特に、プライマリーサーバー上でVACUUM / TRUNCATEのトランザクションが複数(例えば数千件)実行されている場合に、性能が低下する可能性があります。ここからは専門的な話になりますが、この場合、各トランザクションはテーブルを切り捨て(VACUUMは、テーブルごとに新しいトランザクションを内部的に開始します)、バッファー・プール全体がトランザクションごとにスキャンされます。フェイルオーバーのテストとしてPostgreSQL 13を使用すると、更新がスタンバイサーバーに反映されるまでに数十秒かかります。特定のテストケースの例は、後のセクションで示します。性能はサーバーの仕様によって異なりますが、調査の結果、PostgreSQL 13における性能の低下は共有バッファーのサイズとトランザクション数の増加に直接関係していることが分かりました。
私は、FUJITSU Software Enterprise Postgresでお客様の要件を満たすため、この問題に対する解決策を提示しなければなりませんでした。並行して、私はオープン・ソース・ソフトウェア(以下、OSS)コミュニティーに設計を提案し、特にリレーションのバッファーを削除する際における上記の性能問題について、PostgreSQL(ターゲットはPostgreSQL 14)の信頼性を向上させることに関心を持ってもらうようにしました。
機能概要 - リレーションサイズの判定とバッファーの検索
Kirk
ここでも専門的な話をします。私のパッチでは、リレーション内で削除されるバッファーの数が設定されたしきい値以下の場合にバッファー・プール全体のスキャンが回避されるよう、リレーションバッファーを削除するためのリカバリーパスが最適化されています。これは、削除されるリレーション以外に余分なものが残らないように、リレーションの正確なサイズを決定することによって行われます。キャッシュされたリレーションサイズがあると判断したら、バッファーマッピングハッシュテーブルで無効化されるバッファーを検索します。
VACUUMとTRUNCATEのパスは異なっており、少し異なる変更が必要です。VACUUM / autovacuumのパスは、単一のリレーション用にDropRelFileNodeBuffers()で最適化されます。TRUNCATEのパスは、複数のリレーションを削除できるDropRelFileNodesAllBuffers()で最適化されます。パフォーマンス改善の目的は同じですが、パッチを分離する必要があるため、2つのパッチをコミットしました。
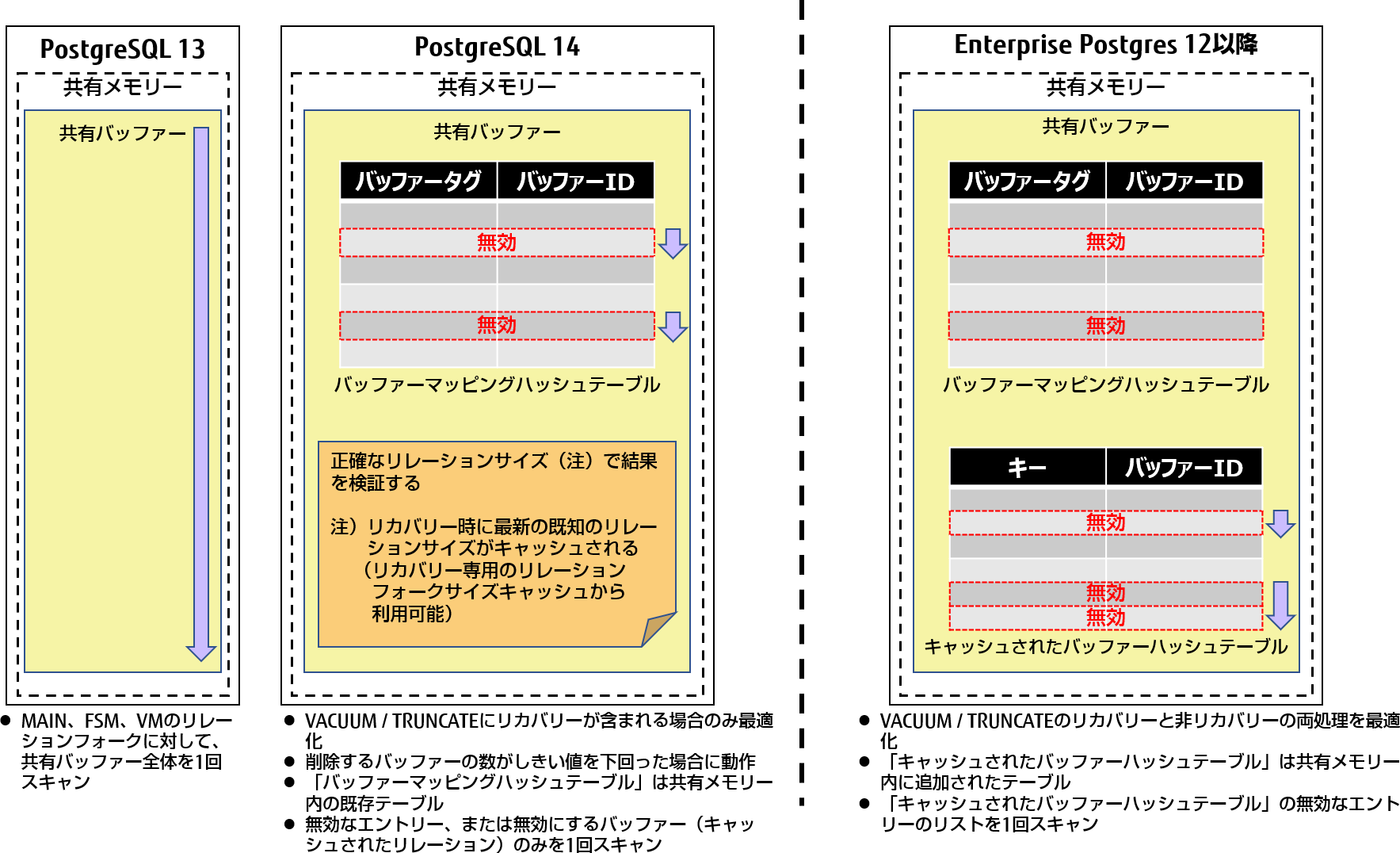
図1:VACUUMおよびTRUNCATEでのリレーションバッファーの無効化
前のセクションで述べたように、この改善は元々、FUJITSU Software Enterprise Postgres 12用に開発されました。これとPostgreSQLコアにコミットされたパッチの実装には違いがあることに注意してください。FUJITSU Software Enterprise Postgres 12の機能は、バッファーハッシュテーブルのキャッシュを使用し、共有メモリー内に無効化されるバッファーのリンクリストを2重に保持することで、VACUUMとTRUNCATEのリカバリーパスと非リカバリーパスの両方をカバーします。しかし、私がこの設計についてコミュニティーと話し合ったところ、バッファー割当てには余分なオーバーヘッド(コスト)があり、PostgreSQLの一般的なワークロードに影響を与える可能性があることがわかりました。そのため、コミュニティー内のコミッター(Andres Freund氏とAmit Kapila)の提案されたアイデアを使用して、別のアプローチをしなければなりませんでした。それは、最新の既知のリレーションサイズをキャッシュし、無効にするバッファーのハッシュテーブル検索を行うことで、バッファー割り当てのオーバーヘッドを回避し、リカバリーパスのみを最適化するというものです。
ユーザーのメリット
Kirk
コミットされた機能は、大きなバッファー・プールを使用する大規模なサーバー・システムにとって有益です。一般に、コミットされたリカバリーの最適化は次のユースケースに役立ちます。
以下のどちらかのケース:
- (a)VACUUMコマンドまたはautovacuumがリレーションの最後にある空のページを切り詰めた場合
- (b)リレーションが作成されたのと同じトランザクションで切り詰められている場合
かつ、
- (c)リレーションファイルを削除する必要がある操作、例えばTRUNCATE、DROP TABLE、ABORT、CREATE TABLEなどを実行する場合
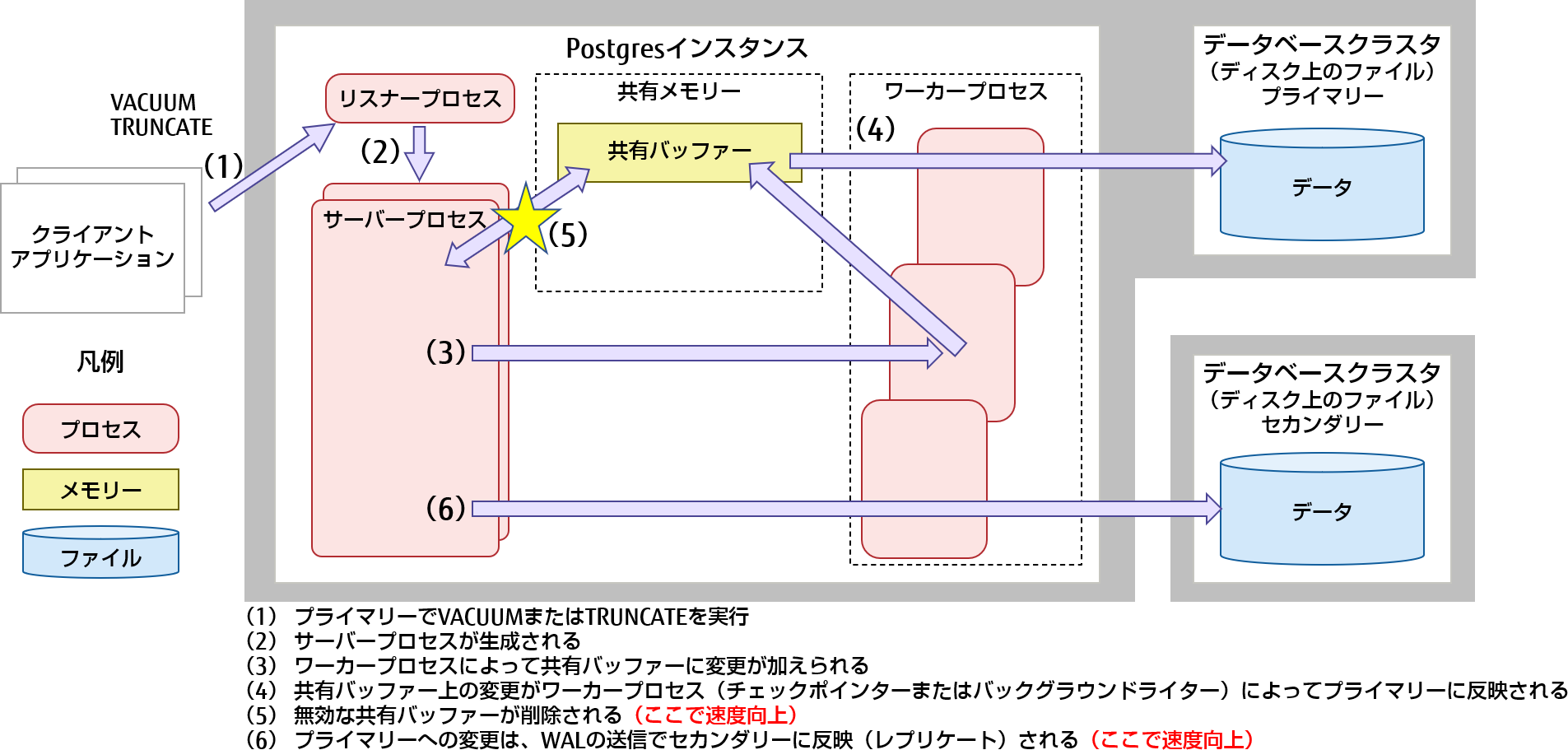
図2:最適化されたリカバリーパスのトランザクションプロセスの概要(レプリケーションの場合)
これにより、リカバリーのパフォーマンスが100倍以上向上するケースがあります。特に、小さなテーブル(1,000個のリレーションでテストしました)がいくつかトランケートされている場合や、サーバーに大きな値の共有バッファーが設定されている場合に顕著です。主なアピールポイントは、トランケートされたリレーションのキャッシュサイズがある場合、リカバリー中にバッファープール全体のスキャンをスキップできることです。これは、shared_buffersのサイズに関わらず、ユースケース(a)、(b)、(c)でのリカバリー時のWAL適用時間を短縮します。(128 メガバイトから100 ギガバイトまでテストしました)
テストの結果は以下の表のとおりです。なお、実行時間はテストを5回実行したときの平均値です。また、改善率(フェイルオーバー時間の削減率)は、下記の計算式で算出しました。
((PostgreSQL 13の時間 - PostgreSQL 14の時間)÷ PostgreSQL 13の時間) × 100
1,000個のリレーションに対するVACUUMフェイルオーバー / リカバリー性能の結果
| shared_buffersのサイズ | PostgreSQL 13 | PostgreSQL 14 | 改善率 |
|---|---|---|---|
| 128 メガバイト | 0.306秒 | 0.306秒 | 0% |
| 1 ギガバイト | 0.506秒 | 0.306秒 | 39.53% |
| 20 ギガバイト | 14.522秒 | 0.306秒 | 97.89% |
| 100 ギガバイト | 66.564秒 | 0.306秒 | 99.54% |
1,000個のリレーションに対するTRUNCATEフェイルオーバー / リカバリー性能の結果
| shared_buffersのサイズ | PostgreSQL 13 | PostgreSQL 14 | 改善率 |
|---|---|---|---|
| 128 メガバイト | 0.206秒 | 0.206秒 | 0% |
| 1 ギガバイト | 0.506秒 | 0.206秒 | 59.29% |
| 20 ギガバイト | 16.476秒 | 0.206秒 | 98.75% |
| 100 ギガバイト | 88.261秒 | 0.206秒 | 99.77% |
上記のベンチマークから、PostgreSQL 14での結果はTRUNCATEとVACUUMの両方共、すべてのshared_buffersの設定で一定であることがわかります。バッファーのスキャンと無効化は共有バッファーのサイズに依存しません。
このテストケースと仕様の詳細については、以下のコミュニティースレッドを参照してください。
開発の舞台裏:コミュニティーメンバーとの協働
Kirk
OSSコミュニティーでは、コミッターであるTom Lane氏、Robert Haas氏、Andres Freund氏、Thomas Munro氏、Amit Kapilaが、このソリューションに関する議論に重要なポイントを提供してくれました。また、レビュアーである堀口 恭太郎氏や当社シニアプロエンジニアの綱川 貴之が、よりシンプルで高品質なコードになるようにパッチの完成を手伝ってくれました。
私はレビュー担当者のコメントに返信したり、テストケースとテスト結果を使用してパフォーマンス改善の証拠を投稿したりするために多くの時間を費やしました。この機能は大きく変更されたため、実装するのに約1年かかりました。私が提出したパッチが高品質であることを証明するために、テストを使用してコミュニティーを説得しなければなりませんでした。
フィードバックのいくつかが私の最初のコードに大きな変更をもたらしたので、この経験にはやりがいと充実がありました。コミュニティー活動の醍醐味は、最初は相反するアイデアやレビューがあることが多いのですが、最終的には合意に達することです。批判的なフィードバックと、レビュアーやコミッターの継続的なサポートがなければ、私はプロジェクトを成功させることはできなかったでしょう。
富士通のグローバルPostgreSQL開発チームのロードマップの一部として、特にシステム停止やフェイルオーバーの発生に対するPostgreSQLの信頼性向上を目指しています。今回のプロジェクトでは、Amit Kapilaと綱川 貴之の指導のもと、パッチのコミットに成功しました。私のテストが有効であることを確認するために、私のチームの他のメンバーも私のテストを再実行し、その結果をコミュニティーのメーリング・リストのスレッドに投稿しました。
今回コミットされたパッチは、私にとっての2回目と3回目の主要機能になります。私のコードがPostgreSQLのコアコードに反映されているのを見ると、非常に満足しています。このコミュニティーに貢献し続ける自信を深めました。
将来を見据えて - リレーションサイズのキャッシングにおけるさらなる改善
Kirk
リレーションサイズの共有キャッシュを提供することについて、別のコミッターであるThomas Munro氏による議論と開発が進行中です。
開発がうまくいけば、VACUUMとTRUNCATEの非リカバリーパスや通常の操作をカバーするように機能を拡張することができるでしょう。
富士通のグローバルPostgreSQL開発チームは、PostgreSQLコアへの統合を目的とした開発項目を挙げ、コミットの目標時期を決めて取り組んでいます。これらの開発項目は、富士通の顧客ニーズに対応し、PostgreSQLコミュニティーに貢献します。近い将来、私たちの開発作業についてさらに情報を共有できることを楽しみにしています。
2021年4月23日公開
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


