

PostgreSQL 16とその後:技術者Blog
PostgreSQLインサイド


Amit Kapila
FUJITSU Limited
Software Products Business Unit Data Management Division
Senior Director
今年の初め、私はカナダで開催されたPGConf 2023に参加し、PostgreSQLがバークレー校の研究プロジェクトから最も先進的なオープンソースデータベースとしての地位を確立するまでの進化について話し、PostgreSQL 16で導入された様々な改善点、特に論理レプリケーションについて論じました。
私の講演では、バージョン16で導入された魅力的な新機能にフォーカスしましたが、PostgreSQLの過去、つまり過去のバージョンにおける主要な機能の年表や、PostgreSQL 17での実装に向けてコミュニティが議論してきた内容など、将来についても触れました。
目次
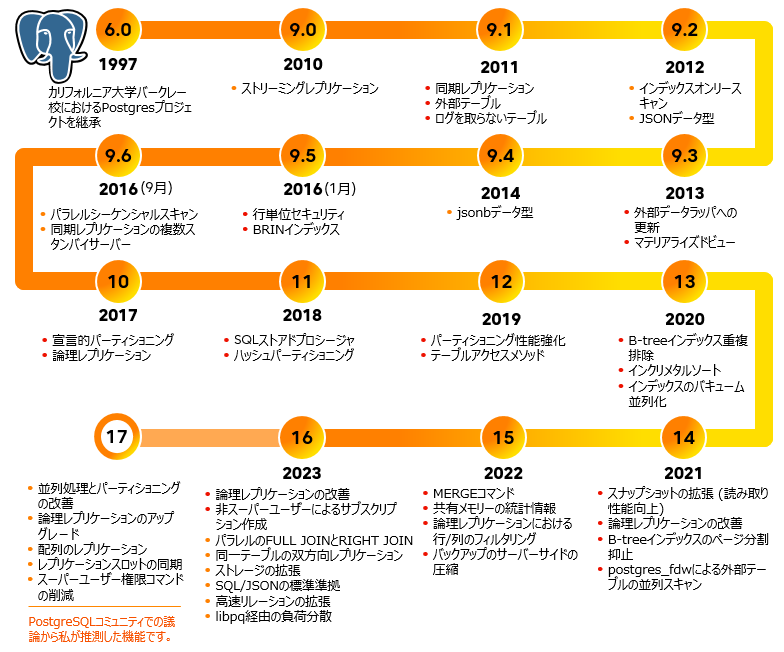
PostgreSQLの進化- バージョンと主なマイルストーン
PostgreSQLがその初期から歩んできた長い道のりをより深く理解するためには、PostgreSQLの進歩と、その過程で蓄積された素晴らしい機能の一覧を再確認することが重要だと思います。これは、献身的で熱心なコミュニティの活動のおかげです。

図1:PostgreSQLのバージョンごとの進化
PostgreSQLの開発プロジェクトは1997年にスタートしています。本プロジェクトは、1986年から稼働していたカリフォルニア大学バークレー校のプロジェクトがもとになっています。以来、毎年主要な機能を追加した新しいバージョンがリリースされています。
興味深いのはPostgreSQLは当初から大量のデータを扱うことを目的としており、以降もその方向に進化してきたということです。
例えば、バージョン9.0ではフェイルオーバーに有効な機能であるストリーミングレプリケーションが導入されました。これにより、あるノードがダウンした場合に、別のノードが引き継ぐことができます。バージョン9.1では、外部テーブルとログを取らないテーブル、さらに信頼性を向上し価値をさらに高めるのに役立つ同期レプリケーションの機能が導入されました。
バージョン9.2では、JSONデータ型のサポートが追加され、ドキュメントとその関連データは、このデータ型を使って格納できるようになりました。このバージョンでは、インデックスオンリースキャンも導入され、様々な種類のクエリの処理速度が向上しました。翌年のバージョン9.3では、外部データラッパへの更新とマテリアライズドビューが追加されました。さらにバージョン9.4ではJSONの改良版であるjsonbデータ型が導入され、そのデータ型に対する高速な処理とインデックスを付けることが可能となりました。
バージョン9.5では、行単位セキュリティとBRINインデックスが追加され、特定のタイプのクエリを劇的に高速化できるようになりました。 バージョン9.6では、パラレルシーケンシャルスキャンとパラレルジョインが追加され、OLAPアプリケーションで活用できるようになりました。 また、さらに信頼性を高めるために、ストリーミングレプリケーションにおいて複数のスタンバイサーバーと同期レプリケーションができるようになりました。
バージョン10では、論理レプリケーションと宣言的パーティショニングが導入され、PostgreSQLに新しい展望が開かれました。バージョン11では、ハッシュパーティショニングとSQLストアドプロシージャが導入され、他のデータベースからの移行を検討している組織にとって魅力が広がりました。バージョン12では、パーティショニングの性能を強化し、PostgreSQLと統合できる専用のストレージエンジンが作成可能となるテーブルアクセスメソッドを導入しました。バージョン13の主な機能には、B-treeインデックス重複排除、インクリメンタルソート、インデックスのバキューム並列化があります。
バージョン14では、多くの重要な機能追加と機能強化が行われました。スナップショット機構を拡張することで、より優れた読み取りスケーラビリティを実現し、進行中のトランザクションの論理レプリケーションを許可することで、大規模トランザクションを適用する際の適用遅延を軽減しました。また、B-treeインデックス更新の肥大化の抑制や、postgres_fdwによる外部テーブルの並列スキャンを可能にしました。
バージョン15では、MERGEコマンドを導入しました。これは数年前からコミュニティで議論されていたもので、ようやく実装できました。また、以前の統計メカニズムよりも改善された共有メモリーの統計情報を導入し、さらに、行と列のフィルタリングを導入することで論理レプリケーションを改善しました。最後に、より高速でより容量の少ないバックアップのためにサーバー側でバックアップを圧縮する機能を追加しました。
PostgreSQL 16の機能強化と新機能
バージョン16では多くの新機能が導入され、論理レプリケーションの機構もいくつか改善されています。私が考える最も重要なものの1つは、スタンバイノードから論理レプリケーションを実行できる機能で、これについては後述します。
論理レプリケーションの改善
-
レプリケーション中に、originオプションに基づいてデータをフィルタリング(除外)できるようになりました。
CREATE PUBLICATION mypub FOR ALL TABLES; CREATE SUBSCRIPTION mysub CONNECTION 'dbname=postgres' PUBLICATION mypub WITH (origin = none);Postgres 15以前では、テーブルに対してレプリケーションを設定すると無限ループになる場合があり、ノード間で双方向レプリケーションや論理レプリケーションを設定することは困難でした。originに基づいて、つまりパブリケーションから受け取ったレプリケーションデータと該当サーバーでクエリにて変更されたデータを区別できるようになり、これらのデータをフィルタリングする機能を追加します。 これにより、n-way論理レプリケーションを設定でき、双方向レプリケーションを実行する際のループを防止できます。
-
ロジカルデコーディングがスタンバイサーバーから実行できるようになりました。
これには、プライマリーとスタンバイの両方で wal_level = logical を設定する必要があります。
この機能は、プライマリーがビジー状態のときにサブスクライバーがスタンバイからサブスクライブできるようにすることで、負荷を分散させることができます。 -
適用プロセスは、サブスクリプション所有者の権限ではなく、テーブル所有者の権限で実行するよう設定できるようになりました。
CREATE SUBSCRIPTION mysub CONNECTION ... PUBLICATION mypub WITH (run_as_owner = false); -
非スーパーユーザーがサブスクリプションを作成できるようになりました。
非スーパーユーザーはpg_create_subscriptionロールを付与されていなければならず、認証のためにパスワードを指定する必要があります。
スーパーユーザーは、サブスクリプションを所有する非スーパーユーザーに対してpassword_required = falseを設定できます。 -
サブスクライバーで大きなトランザクションが並列に適用できるようになりました。
CREATE SUBSCRIPTION mysub CONNECTION ... PUBLICATION mypub WITH (streaming = parallel);25~40% の性能向上が確認されています(詳細は「Re: Perform streaming logical transactions by background workers and parallel apply」(pgsql-hackersのメーリングリストへ)。
各々の大きなトランザクションは、利用可能なワーカーの1つに割り当てられます。これは、トランザクション全体がサブスクライバーに受信されるまで待つのではなく、即座に適用することで遅延を改善します。 ワーカーはトランザクションが完了するまで割り当てられたままです。
参考までに、サブスクリプションあたりの並列適用ワーカーの最大数は、max_parallel_apply_workers_per_subscriptionで設定します。 -
論理レプリケーションで初期テーブルを同期する際にテーブルをバイナリ形式でコピーできるようになりました。
CREATE SUBSCRIPTION mysub CONNECTION ... PUBLICATION mypub WITH (binary = true);バイナリ形式でテーブルをコピーすると、カラムの種類によっては時間短縮される場合があります。
-
PRIMARY KEY と REPLICA IDENTITY 以外のインデックスをサブスクライバーで使用できるようになりました。
REPLICA IDENTITYまたはPRIMARY KEYインデックスが使用できない場合に、パブリッシャーでREPLICA IDENTITY FULLを使用すると、サブスクライバーでタプル(レコード)の変更ごとにテーブルをフルスキャンすることになります。
使用できるインデックスはB-Treeインデックスです。部分インデックスは利用できません。また、左端のフィールドは、リモートのリレーションの列を参照する列(式ではありません) でなければなりません。
テーブル内のデータ量に比例して性能は向上します。
ストレージの拡張
-
リレーション拡張のパフォーマンスが向上しました。
バージョン16では、1つのリレーションへの同時COPYが大幅に改善されました(16クライアントで3倍)。
リレーション拡張のロックについて、以前はシステムが以下の処理を実行する間も保持されましたが、バージョン16ではリレーション拡張時のみロックするようになりました。- 新しいページのために書き出されるバッファの捕捉(WALをフラッシュする必要があるなど、古いページの内容をさらに書き出す必要があるかもしれません)。
- 拡張中の0ページの書き込みと実ページの内容の書き出し(これは書き込み速度が約2倍になります)。
-
BRINインデックスが付けられた列のみが更新される場合、ヒープ専用タプル(Heap-Only Tuples、以降HOT)更新が許可されます。
対応する列が更新された場合でも、BRINインデックスを更新します。これは、インデックスの述部で参照される属性には適用されず、このような属性の更新は常にHOTを無効にします。 -
ダイレクトI/Oを使用可能とします。
これにより、リレーションデータとWALファイルのキャッシュ効果を最小化するようカーネルに要求できます。現在、この機能はシステム性能を低下させる上、エンドユーザー向けではない(開発者向けのオプション)ため、デフォルトでは無効になっています。 このオプションは、GUCパラメーターの debug_io_direct(有効な値は、data、wal、wal_init)により有効にできます。
今後の計画は、カーネルがこのオプションで無効にする機能を置き換えるために、先行読み込みなどのような独自のI/O機構を導入することです。ダイレクトI/Oでより良いパフォーマンスを得られるように、すべてのI/Oバッファを4096に揃えます。 -
バキューム中にページレベルでフリーズできるようにします。
これにより、WALの量を減らし、フリーズ処理のコストを削減します。 -
詳細なI/O統計を表示するpg_stat_ioビューを追加します。
このビューには、バックエンドの種別、ターゲットI/OオブジェクトおよびI/Oコンテキストの組合せが1行含まれており、クラスタ全体のI/O統計情報が表示されます。- バックエンドタイプの例:バックグラウンドワーカー、オートバキュームワーカー、チェックポインターなど
- ターゲットI/Oオブジェクトの可能なタイプ: 永続または一時のリレーション
- I/Oコンテキストの取りうる値:normal, vacuum, bulkread, bulkwrite
ビューは、reads、writes、extends、hits、evictions、reuses、fsyncsなど、さまざまなI/O操作を追跡します。evictionsの回数が多い場合は、共有バッファを増やす必要があることを示しています。 クライアントバックエンドによるfsyncsが多い場合は、共有バッファまたはチェックポインタの設定ミスを示している可能性があります。
この統計は、ディスクからフェッチしなければならなかったデータと、カーネルのページキャッシュにすでに存在していたデータを区別しません。 -
VACUUM/ANALYZEでバッファ使用量制限を指定できるようになりました。
VACUUMコマンドとANALYZEコマンドに新しいオプションBUFFER_USAGE_LIMITが追加され、共有バッファのサイズを制御できるようになりました。 より大きな値を指定することで、同時に実行される他の問合せの速度を低下させる代わりに、バキュームをより高速に実行できます。
本処理を制御する別の方法として、GUCパラメーターのvacuum_buffer_usage_limitがありますが、VACUUMコマンドとANALYZEコマンドのBUFFER_USAGE_LIMITの指定が優先されます。 GUCパラメーターは自動バキュームでも指定された制限値を使用することができます。
また、vacuumdbコマンドにbuffer-usage-limitオプションを追加しました。
SQLの新機能
新しいバージョンには、照合順序やJSONデータの操作などのオプションをユーザーに提供する多数の新機能が搭載されています。
-
テキストの照合順序(テキストをどのように並べ替えるかのルール)のサポートが改善されました。
CREATE COLLATION en_custom (provider = icu, locale = 'en', rules = '&a < g');上記のコマンドラインでは、gをaの後、bの前に置きます。
ルールを設定するための新しいオプションがCREATE COLLATION、CREATE DATABASE、createdb、およびinitdbに追加されました。 -
ICUをデフォルトの照合順序のプロバイダーに設定できるようにしました。
環境に応じてICUのデフォルトのロケールを決定します。 -
定義済の照合順序であるunicodeおよびucs_basicのサポートが追加されました。
-
SQL/JSON標準に準拠したJSON型用のコンストラクタが追加されました。
-
JSON_ARRAY()関数 - 一連のvalue_expressionパラメーターまたはquery_expressionの結果からJSON配列を構築します。
SELECT json_array(1,true,json '{"a":null}'); json_array ----------------------- [1, true, {"a":null}] -
JSON_ARRAYAGG()関数 – JSON_ARRAY関数と同じように動作しますが、集約関数なのでvalue_expressionパラメーターを1つだけ受け取ります。
SELECT json_arrayagg(v NULL ON NULL) FROM (VALUES(2),(1),(3),(NULL)) t(v); json_arrayagg ----------------- [2, 1, 3, null] -
JSON_OBJECT()関数 - 指定されたすべてのキーと値のペアのJSONオブジェクトを作成します。何も指定されていない場合は空のオブジェクトを作成します。
SELECT json_object('code' VALUE 'P123', 'title': 'Jaws', 'title1' : NULL ABSENT ON NULL); json_object ------------------------------------- {"code" : "P123", "title" : "Jaws"} -
JSON_OBJECTAGG()関数 – JSON_OBJECT関数と同じように動作しますが、集約関数なので1つのkey_expressionと1つのvalue_expressionパラメーターだけ受け取ります。
SELECT json_objectagg(k:v) FROM (VALUES ('a'::text,current_date),('b',current_date + 1)) AS t(k,v); json_objectagg -------------------------------------------- { "a" : "2023-05-19", "b" : "2023-05-20" }
-
-
SQL標準のIS JSON述語を実装しました。
IS JSON [VALUE], IS JSON ARRAY, IS JSON OBJECT, IS JSON SCALARSELECT js, js IS JSON "json?", js IS JSON SCALAR "scalar?", js IS JSON OBJECT "object?", js IS JSON ARRAY "array?" FROM (VALUES ('123'), ('"abc"'), ('{"a": "b"}'), ('[1,2]')) foo(js); js | json? | scalar? | object? | array? -----------+-------+---------+---------+-------- 123 | t | t | f | f "abc" | t | t | f | f {"a": "b"} | t | f | t | f [1,2] | t | f | f | t -
パラレルのハッシュ結合においてfull joinをサポートしました。
EXPLAIN (COSTS OFF) SELECT COUNT(*) FROM simple r FULL OUTER JOIN simple s USING (id); QUERY PLAN ------------------------------------------------------------- Finalize Aggregate -> Gather Workers Planned: 2 -> Partial Aggregate -> Parallel Hash Full Join Hash Cond: (r.id = s.id) -> Parallel Seq Scan on simple r -> Parallel Hash -> Parallel Seq Scan on simple s -
集約関数string_aggとarray_aggはパラレル集約できるようになりました。
EXPLAIN (COSTS OFF) SELECT y, string_agg(x::text, ‘,’) AS t, array_agg(x) AS a FROM pagg_TEST GROUP BY y; QUERY PLAN -------------------------------------------------- Finalize HashAggregate Group Key: y -> Gather Workers Planned: 2 -> Partial HashAggregate Group Key: y -> Parallel Seq Scan on pagg_test -
ORDER BYまたはDISTINCTを持つ集約は、ソート済のデータが使用できるようになりました。
これまでは、集約を行う前にタプルをソートする必要がありました。
PostgreSQL 16では、インデックスによって事前にソートされた入力データが提供され、それが集約に直接使用されます。EXPLAIN (COSTS OFF) SELECT SUM(c1 ORDER BY c1), MAX(c2 ORDER BY c2) FROM presort_test; QUERY PLAN ------------------------------------------------------------ Aggregate -> Index Scan using presort_test_c1_idx on presort_test SET enable_presorted_aggregate=off; EXPLAIN (COSTS OFF) SELECT SUM(c1 ORDER BY c1), MAX(c2 ORDER By c2) FROM presort_test; QUERY PLAN -------------------------------- Aggregate -> Seq Scan on presort_test -
RANGEパーティションおよびLISTパーティションの検索で最後に見つかったパーティションがキャッシュされます。
これにより、多くの連続したタプルが同じパーティションに属するパーティションテーブルへのバルクロードのオーバーヘッドが削減されます。 -
パーティション化テーブルでのLEFT JOINの削除と等価結合ができるようになりました。
CREATE TEMP TABLE a (id int PRIMARY KEY, b_id int); CREATE TEMP TABLE parted_b (id int PRIMARY KEY) PARTITION BY RANGE(id); CREATE TEMP TABLE parted_b1 PARTITION OF parted_b FOR VALUES FROM (0) TO (10); EXPLAIN (COSTS OFF) SELECT a.* FROM a LEFT JOIN parted_b pb ON a.b_id = pb.id; QUERY PLAN --------------- Seq Scan on a
セキュリティ/権限の追加
-
各種コマンドでスーパーユーザー権限を追加する必要がなくなりました。
- reserved_connectionsパラメーターは非スーパーユーザーによる接続スロットを予約する方法を提供します。
- 定義済のロールpg_use_reserved_connectionsはreserved_connectionsパラメーターで予約された接続スロットを使用します。
-
Kerberos資格情報の委任のサポートが追加されました。
これによりPostgreSQLサーバーはこれらの委任された資格情報を使用して、postgres_fdwやdblink、または理論的にはKerberosを使用して認証できる他のサービスなどの別のサービスに接続できるようになります。 -
許可される認証メソッドの一覧を指定する新しいlibpq接続オプションrequire_authが追加されました。
指定できるメソッドは、password、md5、gss、sspi、scram-sha-256、またはnoneです。
このオプションは、メソッドの先頭に!を付けることによって、特定の認証メソッドを許可しないようにすることもできます。
サーバーが必要な認証要求を使用しない場合、接続試行は失敗します。 -
libpqが証明書の検証にシステム証明書プールを使用できるようになりました。
これはsslrootcert=systemで有効になります。設定値systemは、同じ名前のローカル証明書ファイルよりも優先されます。 -
GRANT ... SETオプションが追加されました。
SETオプションをTRUEに設定すると、メンバはSET ROLEコマンドを使用して付与されたロールに変更できます。別のロールが所有するオブジェクトを作成したり、既存のオブジェクトの所有権を別のロールに付与したりするには、そのロールにSET ROLEする権限が必要です。 それ以外の場合、ALTER ... OWNER TOまたはCREATE DATABASE ... OWNERなどのコマンドは失敗します。
その他のパフォーマンスの改善
-
pg_strtointnn関数のパフォーマンスが向上しました。
テストの結果、2つのINTカラムを含むテーブルへのCOPYで、約8%の高速化が確認されました。 -
ハッシュインデックス構築のパフォーマンスが向上しました。
最初のデータソートで、バケット番号が同じ場合は、次にハッシュ値でソートします。不要なバイナリ検索を省略することで、ビルドが高速化されます。ハッシュインデックスの作成速度が5~15%向上しました。 -
メモリ管理のパフォーマンスが向上し、オーバーヘッドが削減されました。
各割り当てのヘッダーサイズを16+から8バイトに削減し、ロジカルデコーディング中にメモリを割り当てるために使用されるスラブメモリアロケータの性能を向上させました。 -
x86アーキテクチャとARMアーキテクチャの両方で、SIMDを使用したCPUアクセラレーションのサポートが追加されました。
これにより、サブトランザクション検索とASCIIおよびJSON文字列の処理が最適化されます。 -
libpqの接続ロードバランシングの性能が向上しました。
load_balance_hosts=randomを設定すると、ホストとアドレスをランダムな順序で接続できます。このパラメーターをtarget_session_attrsと組み合わせて使用すると、スタンバイサーバーでのみ負荷分散を行うことができます。
選択したノードが応答しない場合に他のノードが試行されるように、connect_timeoutにも適切な値を設定することをお勧めします。 -
pg_dumpにLZ4とZstandard圧縮オプションが追加されました。
-
バッチで行を追加するための外部テーブルへのCOPYがサポートされました。
これはpostgres_fdwのbatch_sizeオプションで制御されます。
互換性
-
Windowsインストールにおいて、Windows 10の最小バージョンをサポートしました。
-
スタンバイサーバーの昇格を有効にするpromote_trigger_fileオプションを削除します。
スタンバイを昇格させるにはpg_ctl promoteコマンドまたはpg_promote() 関数を使用しなければなりません。 -
サーバー変数vacuum_defer_cleanup_ageが削除されました。
hot_standby_feedbackとレプリケーションスロットが追加されたので、これは不要になりました。 -
libpqによるSCM資格証明認証のサポートが削除されました。
-
最終的にAutoconfに取って代わるMesonビルドシステムを導入しました。
すべての機能一覧
新機能や強化された機能、およびその他の変更に関するすべての機能一覧はここにあります。
- PostgreSQL:Documentation: 16: E.1. Release 16(PostgreSQLオフィシャルのページへ)
PostgreSQL 17とその後
最後に、PostgreSQL 17以降のようなPostgreSQLの将来のバージョンについてPostgreSQLコミュニティが現在議論している変更点をいくつか紹介したいと思います。 このリストは確定したものではなく、これらすべての機能が最終候補に入る保証はないことに注意してください。これはPostgreSQLコミュニティ内で行われている議論から得た私自身の見解に基づいています。
- 論理レプリケーションにおける様々な改善
- DDLコマンドのレプリケーション
- シーケンスのレプリケーション
- フェイルオーバーを可能にするレプリケーションスロットの同期化
- 論理レプリケーションノードのアップグレード
- テーブル同期ワーカの再利用
- スーパーユーザー権限を必要とするコマンドの数の削減
- 標準規格への準拠性を向上させるためのSQL/JSONの改善
- 増分バックアップ
- クライアント内の特定の列の透過的な列暗号化と復号化
- 非同期I/Oによりデータのプリフェッチを可能にし、システムのパフォーマンスを向上
- 大量のファイルデイスクリプタのopen/closeを削減するための大規模リレーションファイル
- テーブルアクセスメソッドAPIのエンハンス
- amcheckモジュールによるGiSTインデックスおよびGINインデックスの検査
- ロックの改善によるスケーラビリティの向上
- パフォーマンスデータ構造の使用によるバキューム技術の改善
- パーティショニング技術の改善
- 統計/監視の改善
- 多くの組織におけるセキュリティ・コンプライアンスへの対応に役立つ透過的データ暗号化
- 64ビットのトランザクションID(XID)により凍結を発生しにくくし、自動バキュームの必要性を削減
- 並列処理
- InitPlanが付加されたプランノードのパラレル安全化
- 相関するサブクエリの並列化
- WALのヘッダーを小さくすることでWAL全体のサイズを削減
- SLRUをメインバッファプールへ移動
- TOASTの改善:カスタム形式と辞書の圧縮
- CIおよびビルドシステムの改善
参考
富士通のウェブサイト「PostgreSQLインサイド」では、富士通の技術者による最新動向を紹介するブログや、PostgreSQLを利用するうえで知っておきたい技術情報・豆知識、およびFujitsu Enterprise Postgresに関する記事を掲載しています。
Fujitsu Enterprise Postgres(エンタープライズ ポストグレス)は、OSS(オープン・ソース・ソフトウェア)のPostgreSQLをエンジンとし、富士通のデータベース技術とノウハウで導入・運用のしやすさを向上し、「セキュリティ」「性能」「信頼性」を強化したデータベースです。
「Fujitsu Enterprise Postgresの製品サイト」では、製品の概要、無料体験版、サービス、技術資料、お客様の導入事例に関する情報を掲載しています。
2023年10月6日公開
オンデマンド(動画)セミナー
-
- PostgreSQLに関連するセミナー動画を公開中。いつでもセミナーをご覧いただけます。
- 【事例解説】運送業務改革をもたらす次世代の運送業界向けDXプラットフォームの構築
- ハイブリッドクラウドに最適なOSSベースのデータベースご紹介
- PostgreSQLに関連するセミナー動画を公開中。いつでもセミナーをご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。




{kind=link}
本コンテンツに関するお問い合わせ
お電話でのお問い合わせ
-
富士通コンタクトライン(総合窓口)
0120-933-200受付時間:9時~12時および13時~17時30分(土曜日・日曜日・祝日・当社指定の休業日を除く)