

論理レプリケーションにおける行フィルターと列リストのパフォーマンスへの影響 - PostgreSQL 15でコミットされた機能の紹介:技術者Blog
PostgreSQLインサイド


Yu Shi
南京富士通南大軟件技術有限公司
開発事業本部デジタルソリューション事業部
はじめに
PostgreSQLにおけるストリーミングレプリケーションと論理レプリケーションの違いの1つは、ストリーミングレプリケーションはインスタンス全体をレプリケートするのに対し、論理レプリケーションでは特定のテーブルと操作のみをレプリケートできることです。
PostgreSQL 14以前では、テーブルがパブリッシュされると、そのすべての行と列がレプリケートされました。しかし、PostgreSQL 15では、パブリケーションに対して行フィルターと列リストを指定して、指定した条件に一致する行と列のみをレプリケートできます。これらの2つの新機能について詳しく知りたい方は、以下のブログ記事をお読みください。
これらの2つの新機能は、ユーザーの機能的なニーズを満たすだけでなく、論理レプリケーションのパフォーマンスにも影響を与えます。フィルターを使用する場合、データは送信前にフィルタリングされるため、オーバーヘッドが生じます。一方、送信されるデータが少なくなるため、データ転送に費やされる帯域幅と時間が節約されます。また、サブスクライバーがトランザクションの再実行に費やす時間が短縮されます。
それでは、いくつかのテストにより、それら全体のパフォーマンス上の影響を見てみましょう。
目次
パフォーマンステストの概要
2つの異なる方法によって、フィルター機能(行フィルターと列リスト)が論理レプリケーションのパフォーマンスに与える影響を確認しました。
テスト方法
以下の2つの方法を使用して、異なる側面からテストを行いました。
テスト方法1) パブリケーションとサブスクリプションを作成する
論理レプリケーションでのデータ転送は、2つのパートで構成されます。レプリケーション開始時にテーブルデータを初期同期するパートと、その後の増分を同期するパートです。行フィルターと列リストはそれら両方ともに機能するので、両方をテストしました。増分の同期は同期論理レプリケーションを用い、パブリッシャー側のSQLの実行時間を比較しました。
テスト方法2)パブリケーションを作成し、データの受信にpg_recvlogicalを使用する
pg_recvlogicalの実行時間を比較しました。
最初の方法は、現実のシナリオに近いものです。2番目の方法では、論理レプリケーションスロットで変更を受信し、指定したパブリケーションでの変更をファイルにリダイレクトします。これはデコード、フィルタリング、データ転送以外の影響を受けることはありません。
このテストでは、フィルター機能を使用するレプリケーションと、フィルター機能を使用しないレプリケーションを比較します。行フィルターについては、さまざまな量の行のフィルタリングをテストしました。
テスト手順
各テスト方法について、次の手順を実行しました。
- パブリケーションとサブスクリプションを作成する方法
- 初期同期
-
パブリッシャーとサブスクライバーとして2つのインスタンスを作成します。
-
パブリッシャー側に200万行のデータを挿入し、パブリケーションを作成します。
-
サブスクライバー側でサブスクリプションを作成します。
-
テーブルの同期が完了してから、初期同期の時間を取得します。
- 増分の同期
-
パブリッシャーとサブスクライバーとして2つのインスタンスを作成します。
-
パブリケーションとサブスクリプションを作成します。
-
同期論理レプリケーションをセットアップします。
-
パブリッシャー側でSQLを実行し、実行時間またはtpsを取得します。
テーブル同期の開始時刻と終了時刻は、サブスクライバーのログから取得しました。テストは10回行い、平均時間を取りました。
2つのシナリオをテストしました:一括挿入を行うトランザクションの実行(1つのトランザクション内で200万行のデータを挿入)と、更新量の少ないトランザクションの実行(テーブル内に200万行のデータがあり、1行が更新される)です。pgbenchを使用して、前者はSQL実行時間を、後者はtpsを取得しました。どちらもテスト時間は10分でした。
- pg_recvlogicalを使用する方法
-
パブリッシャーとしてインスタンスを作成します。
-
パブリケーションを作成します。
-
論理レプリケーションスロットを作成します。
-
SQLを実行します。
-
pg_recvlogicalを使用してパブリッシャーからデータを受け取り、実行時間を取得します。
ここでも、2つのシナリオをテストしました:一括挿入を行うトランザクションの実行(1つのトランザクション内で200万行のデータを挿入)と、更新量の少ないトランザクションの実行(1つのトランザクション内で1行を更新し、合計2万トランザクション)です。timeコマンドを使用して実行時間を記録し、10回実行して平均を取りました。
指定したGUCパラメーター
パフォーマンステストにおいて、他の要因による干渉を防ぐためにGUCパラメーターを以下のように指定しました。
shared_buffers = 8GB
checkpoint_timeout = 30min
max_wal_size = 20GB
min_wal_size = 10GB
autovacuum = offハードウェア環境
このテストでは2台のマシンを使用しました。1台はパブリッシャー用、もう1台はサブスクライバー用(サブスクリプションを作成、またはpg_recvlogicalを使用)です。2台のマシンはイントラネットにあり、ハードウェアのスペックは以下のとおりです。
| 項目 | パブリッシャー | サブスクライバー |
|---|---|---|
| CPU(s) | 16 | 16 |
| モデル名 | Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz | Intel(R) Xeon(R) Silver 4210 CPU @ 2.20GHz |
| メモリ | 50 GB | 50 GB |
両マシン間のネットワーク帯域幅は約20.0 Gbpsでした。
テーブルの構造
まず、以下の構造を持つテーブルを作成しました。
postgres=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+-----------------------------+-----------+----------+---------
id | integer | | not null |
kind | integer | | |
key | integer | | |
time | timestamp without time zone | | | now()
item1 | integer | | |
item2 | integer | | |
item3 | integer | | |
item4 | integer | | |
Indexes:
"tbl_pkey" PRIMARY KEY, btree (id)その後、行フィルターではkind列の値によってフィルタリングされるデータの比率を変えるようにしました。
(なお、行フィルター機能にはレプリカアイデンティティが設定されているカラムの指定が必要な場合があるため、本テストではレプリカアイデンティティ列としてidおよびkindを設定しました。)
列リストのテストでは、id、kind、key、およびtimeの4つの列のみをコピーするようにしました。
テスト結果
検証環境は上述したとおりです。では、結果を見てみましょう。
行フィルター
最初に、フィルタリングした行の比率を変えた場合と、フィルタリングしない場合で、初期同期にかかった時間を比較しました。フィルタリングされたデータの割合は、基本的に時間の割合と等しいことがわかります。
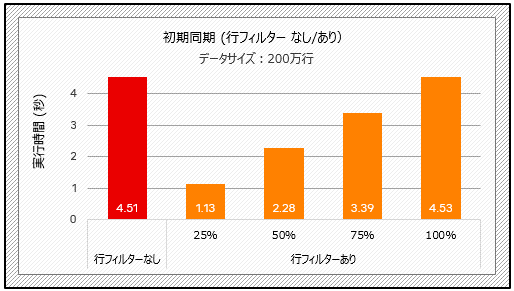
図1:行フィルターの性能比較(テスト1)
次の2つの図は、論理レプリケーションの増分同期のテスト結果です。一括挿入シナリオ(下記のテスト2)では、フィルタリング後にデータの25%が送信されると、フィルタリングなしの場合に比べて約33%の時間が短縮されます。また、更新量の少ないトランザクションを実行する場合(下記のテスト3)、データの25%が送信されるとtpsが約70%向上し、大幅な改善が見られます。
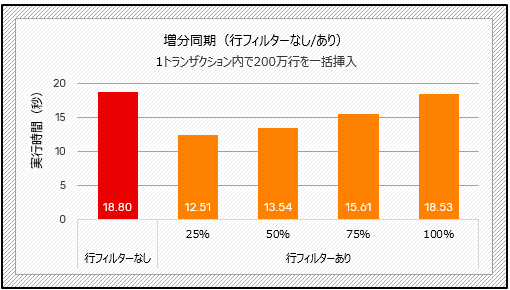
図2:行フィルターの性能比較(テスト2)
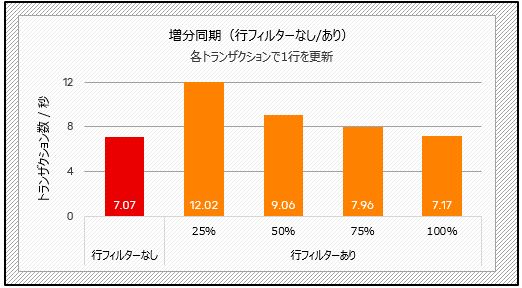
図3:行フィルターの性能比較(テスト3)
以下は、pg_recvlogicalを使用した結果です。フィルタリング後にデータの25%が送信される場合、一括挿入シナリオ(下記のテスト4)では、フィルタリングなしの場合と比較して約43%の時間が短縮され、更新量の少ないトランザクションのシナリオ(下記のテスト5)では、約59%の時間が短縮されます。後者のシナリオで、より顕著に改善されていることがわかります。
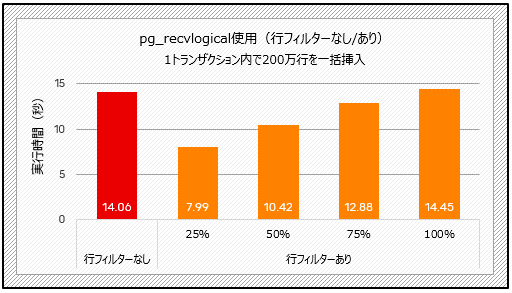
図4:行フィルターの性能比較(テスト4)
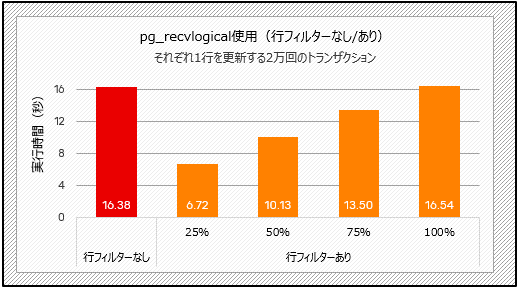
図5:行フィルターの性能比較(テスト5)
結論として、初期同期、一括挿入、および少数の更新はすべて、行フィルターを使用することで大幅に改善できます。フィルターによって送信されるデータが削減されない場合でも、劣化は顕著ではありません(3%未満)。
列リスト
次の図に示すように、初期同期シナリオでは、列リストを使用することでフィルターなしの場合と比較して約11%の時間が短縮されます。
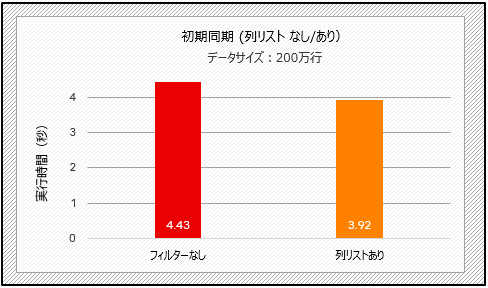
図6:列リストの性能比較(テスト1)
増分のレプリケーションのテストでは、一括挿入のシナリオで列リストを使用すると、約14%の時間が短縮されます(下記のテスト2)。更新量の少ないトランザクションを実行すると、tpsが2.5%増加しますが(下記のテスト3)、この場合は顕著な改善とは言えません。
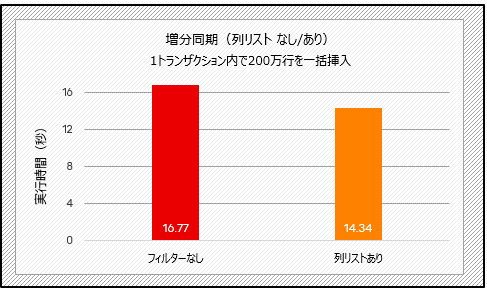
図7:列リストの性能比較(テスト2)
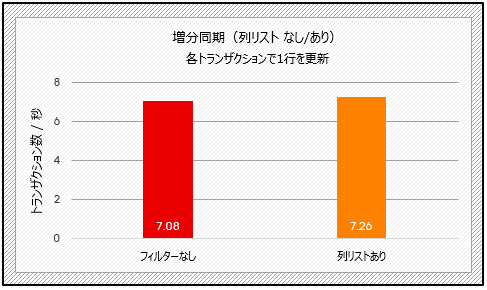
図8:列リストの性能比較(テスト3)
pg_recvlogicalのテスト結果は増分のレプリケーションと同様で、一括挿入のシナリオ(以下のテスト4)では約12%、更新量の少ないシナリオ(下記のテスト5)では2.7%改善されました。
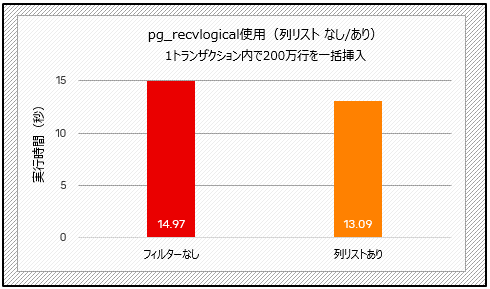
図9:列リストの性能比較(テスト4)
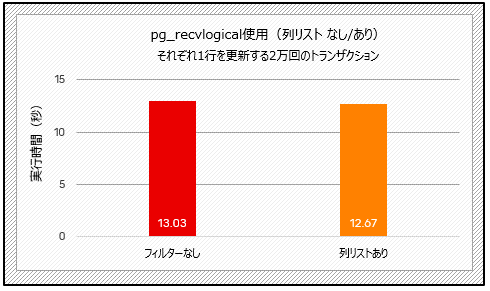
図10:列リストの性能比較(テスト5)
全体として、列フィルターを使用すると、初期のテーブルレプリケーションと一括挿入のパフォーマンスが向上しますが、更新量の少ないトランザクションでは、パフォーマンスの向上は明らかではありません。ただし、フィルタリングされた列に格納されるデータサイズが大きい(たとえば、写真や記事のコンテンツを格納する列)場合、改善がより明白になる可能性があります。
効果
上記のテスト結果から、論理レプリケーションの行フィルターと列リストによってパフォーマンスが向上することがわかります。これら2つの機能を使用することで、パブリッシャーが送信しサブスクライバーが処理するデータの量を削減でき、ネットワーク使用量とCPUのオーバーヘッドを削減できます。同時に、サブスクライバー側のディスク容量も節約することができます。もしユーザーがサブスクライバー側にテーブルの行または列のサブセットのみを必要とする場合は、フィルターの使用を検討し、パフォーマンスを向上させることができます。
今後に向けて
論理レプリケーションの行フィルターと列リストの使用によりパフォーマンスを向上させることができます。今後のPostgreSQLのバージョンアップで、論理レプリケーションに関連する、さらなる新機能とパフォーマンスの向上に期待しましょう。
詳細情報
本ブログに関連する情報の詳細については、PostgreSQL文書をご覧ください。
-
ストリーミングレプリケーションについて
- PostgreSQL: Documentation: 15: 27.2.5. Streaming Replication(PostgreSQLオフィシャルのページへ)
-
論理レプリケーションについて
- PostgreSQL: Documentation: 15: Chapter 31. Logical replication(PostgreSQLオフィシャルのページへ)
-
同期レプリケーションについて
- PostgreSQL: Documentation: 15: 27.2.8. Synchronous Replication(PostgreSQLオフィシャルのページへ)
-
pg_recvlogicalについて
- PostgreSQL: Documentation: 15: pg_recvlogical(PostgreSQLオフィシャルのページへ)
2023年3月6日公開
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


