

ストリーミングレプリケーション ~ 運用のための機能 ~
PostgreSQLインサイド
ストリーミングレプリケーションの仕組みと構成のポイントについては、「ストリーミングレプリケーション ~ 仕組み、構成のポイント ~」で説明しました。
ここでは、ストリーミングレプリケーションのフェイルオーバーとリカバリーのポイントについて説明します。なお、本資料では、PostgreSQL 11で設定可能なパラメーターおよび機能を使用して説明しています。
ポイント
PostgreSQL 12では、設定ファイルのrecovery.confに指定するパラメーターが、postgresql.confに統合されました。PostgreSQL 12を使用する場合、recovery.confが存在するとPostgreSQLサーバーが起動しないなどの仕様変更があります。本資料のrecovery.confに関する記事は、別途仕様を確認してください。仕様の詳細については、“PostgreSQL Documentation”の“Release Notes”の“Migration to Version 12”を参照してください。
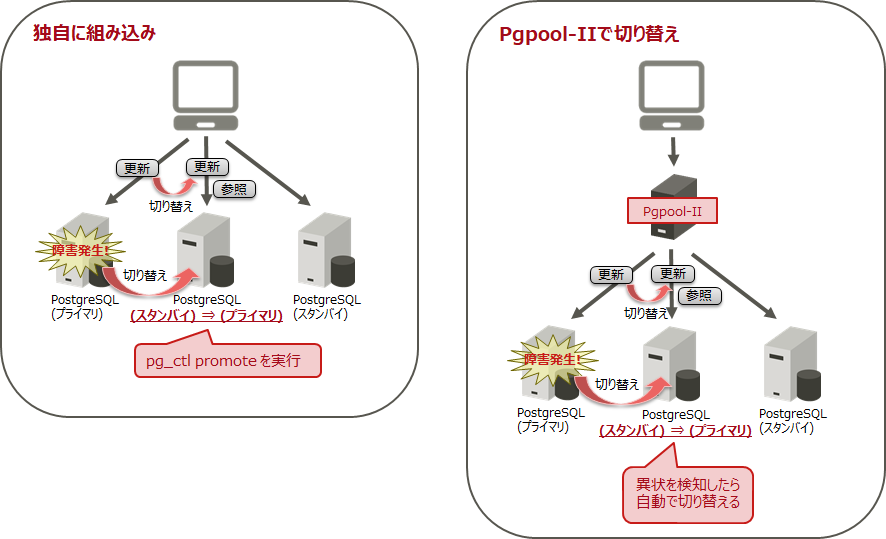
1. フェイルオーバー
プライマリーサーバーに障害が発生した場合、スタンバイサーバーに切り替えることで、業務を継続することができます。
PostgreSQLには異常を検知する機能や自動的な切り替え機能は存在しないため、異常を検知する仕組みを組み込み、さらに、スタンバイサーバーを昇格(pg_ctl promote)させるスクリプトを組み込んでおく必要があります。または、異常検知や自動切り替え機能を備えた、Pgpool-IIなどのクラスタソフトウェアを利用してください。
2. リカバリー
サーバーダウン後の対処は、プライマリーサーバーがダウンした場合と、スタンバイサーバーがダウンした場合で異なります。ここでは、同期レプリケーション構成の場合を例に、それぞれの対処方法について説明します。
2.1 プライマリーサーバーがダウンした場合
プライマリーサーバーがダウンした後、ダウンしたサーバー(旧プライマリーサーバー)をスタンバイサーバーとして再構築する必要があります。旧プライマリーサーバーを復旧する方法として様々ありますが、以下の代表的な2つの方法を紹介します。
2.1.1 ベースバックアップを利用する方法(pg_basebackupコマンド)
新プライマリーサーバーから最新のデータベースクラスタをコピー(pg_basebackupコマンド)し、スタンバイサーバーとして必要な設定を行った上で起動することで、ダウンした旧プライマリーサーバーを、新しいスタンバイサーバーとして構築することができます。データベースが大きい場合は、再構築までに時間がかかります。
リカバリーの概要
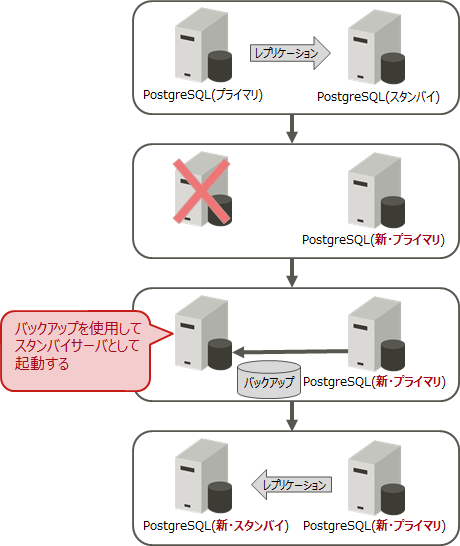
リカバリーの手順
-
障害原因の特定と対処を行い、 ダウンした旧プライマリーサーバーを復旧します。
-
旧プライマリーサーバーで、旧プライマリーサーバーのデータベースクラスタを削除します。
-
旧プライマリーサーバーで、pg_basebackupコマンド(-Rオプション)を実行し、新プライマリーサーバーから物理バックアップを取得します。
-
旧プライマリーサーバーで、recovery.confを修正します。
- standby_mode=onを設定
- primary_conninfoにapplication_nameを追加
-
旧プライマリーサーバーで、postgresql.confを修正します。
- synchronous_standby_namesの無効化
-
旧プライマリーサーバーを起動し、新スタンバイサーバーにします。
-
新プライマリーサーバーで、postgresql.confを修正します。
- synchronous_standby_namesに同期レプリケーションを行うスタンバイサーバー名を設定し、リロードします。
2.1.2 ダウンしたクラスタファイルを利用する方法(pg_rewindコマンド)
旧プライマリーサーバーのデータベースにハードウェアを起因とする障害が発生しておらず、データベースを再起動することが可能な場合は、ダウンしたクラスタファイルを利用して復旧することができます。
旧プライマリーサーバーと新プライマリーサーバーの差分を同期(pg_rewindコマンド)させ、スタンバイサーバーとして必要な設定を行った上で起動することで、ダウンした旧プライマリーサーバーを新しいスタンバイサーバーとして構築することができます。pg_basebackupコマンドと比べ、pg_rewindコマンドは比較的短時間で再構築することができます。ただし、pg_rewindコマンドを使用するには、以下の条件があるので注意が必要です。
- 旧プライマリーサーバーが正常停止している
- postgresql.confのwal_log_hintsパラメーターが有効またはinitdbでデータベースクラスタを初期化する時にデータチェックサムが有効
リカバリーの概要
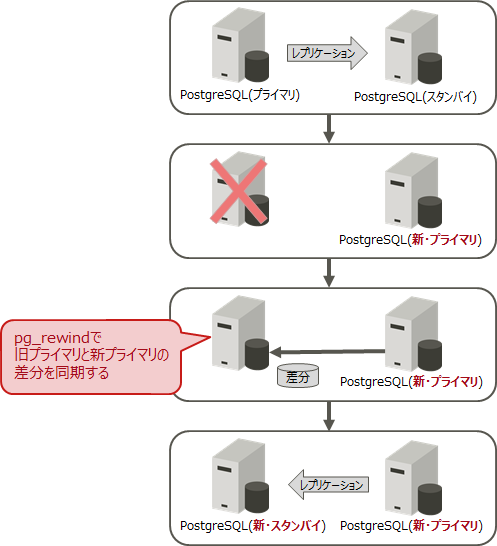
リカバリーの手順
-
障害原因の特定と対処を行い、 ダウンした旧プライマリーサーバーを復旧します。
-
旧プライマリーサーバーは正常停止している必要があるため、停止した旧プライマリーサーバーを一旦起動したあと、正常停止させます。
-
旧プライマリーサーバーで、pg_rewindコマンドを実行します。
-
旧プライマリーサーバーで、recovery.confを作成します。
- standby_mode=onを設定
- recovery_target_timeline=latestを指定
- primary_conninfoにapplication_nameを設定
-
旧プライマリーサーバーで、postgresql.confを修正します。
- synchronous_standby_namesの無効化
-
旧プライマリーサーバーを起動し、新スタンバイサーバーにします。
-
新プライマリーサーバーで、postgresql.confを修正します。
- synchronous_standby_namesに同期レプリケーションを行うスタンバイサーバー名を設定し、リロードします。
-
新スタンバイサーバーと新プライマリーサーバーのタイムラインIDが揃っていることを確認します。タイムラインIDは、pg_controldataコマンドで取得できます。
参考
PostgreSQL 14以降では、pg_rewindコマンド実行時のソースとしてスタンバイサーバーが指定可能になりました。これによりスタンバイサーバーから旧プライマリーサーバーに差分を同期できるようになるため、3台以上の構成でのリカバリーに役立ちます。
2.2 スタンバイサーバーがダウンした場合
スタンバイサーバーがダウンした場合の対処は、スタンバイサーバーが同期レプリケーションなのか、非同期レプリケーションなのかで異なります。それぞれの対処方法について説明します。
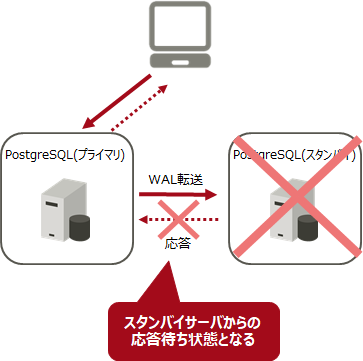
2.2.1 同期レプリケーションの場合
同期レプリケーションとして動作中のスタンバイサーバーがダウンすると、プライマリーサーバーは、スタンバイサーバーからの応答待ちの状態となり、クライアントにCOMMITの応答を返すことができなくなります。そのため、異常があった同期レプリケーションのスタンバイサーバーを切り離す(非同期レプリケーションにする)必要があります。プライマリーサーバーのpostgresql.confのsynchronous_standby_namesパラメーターから異常のあったスタンバイサーバー名を削除し、ファイルの再読み込み(pg_ctl reload)を行ってください。すべてのスタンバイサーバーが停止した場合は、synchronous_standby_namesパラメーターを空にしてから再読み込みを行ってください。
スタンバイサーバーの復旧は、「プライマリーサーバーがダウンした場合」と同様の手順です。
2.2.2 非同期レプリケーションの場合
非同期レプリケーションであるため、スタンバイサーバーがダウンした際に、postgresql.confの編集やファイルの再読み込みを行う必要はありません。
スタンバイサーバーの復旧は、「プライマリーサーバーがダウンした場合」と同様の手順です。
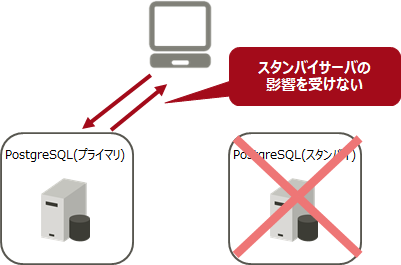
PostgreSQLのストリーミングレプリケーションの運用について解説しました。ストリーミングレプリケーション機能を活用し、データベースの高可用化にお役立てください。
FUJITSU Software Enterprise Postgresでは、異常検知や自動フェイルオーバーなど、実際の業務に必要な機能を備えた「データベース多重化機能」があります。
ぜひ、FUJITSU Software Enterprise Postgresのご利用もご検討ください。
2022年3月25日更新
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


