

パーティショニングにおける性能向上のしくみ
PostgreSQLインサイド
PostgreSQLでは、宣言的パーティショニング(以降、「パーティショニング」と呼びます)を利用することで性能の向上が期待できます。しかし、性能向上のしくみを理解した上で適切に使用しないと、逆に性能が劣化してしまうこともあります。ここでは、パーティショニングにおける性能向上のしくみをPostgreSQL 11.1をベースに解説します。なお、パーティショニングの概要については、「パーティショニングの概要」を参照してください。
パーティショニングにおける性能向上は、以下の機能を利用することで実現できます。
- パーティション・プルーニング(パーティション除去)
- パーティション・ワイズ結合(パーティション同士の結合)
- パーティション・ワイズ集約(パーティション同士の集約)
1. パーティション・プルーニング(パーティション除去)
パーティション・プルーニングは、SQLからアクセスするパーティションを絞り込む機能です。「パーティショニングの概要」で、「検索条件にパーティションキーを指定すると検索範囲の絞り込みが行われる」ことを紹介しました。これは、「パーティション・プルーニング」が機能していたためです。
例えば、以下の図では、s_date列がパーティションキーとなっています。SELECT文のWHERE句にパーティションキーを指定することで、アクセスするパーティションが絞り込まれます。絞り込んだパーティション内で検索が行われるので、効率的な検索処理が可能です。
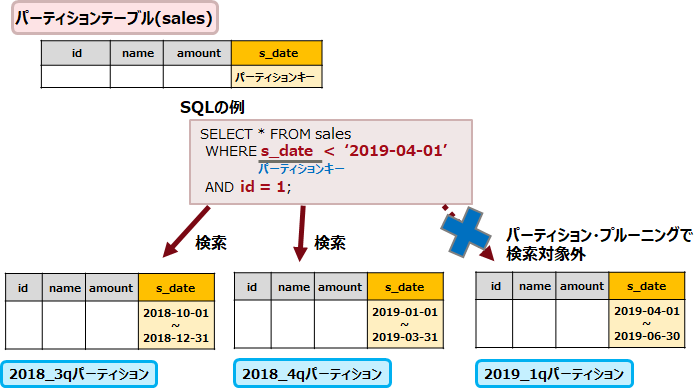
パーティション・プルーニングを利用するためには、postgresql.confのenable_partition_pruningパラメーターがon(デフォルト値:on)に設定されている必要があります。
1.1 パーティション・プルーニングの例
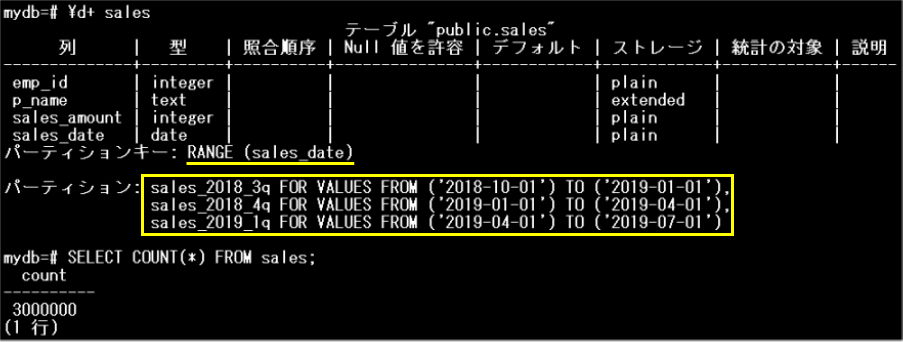
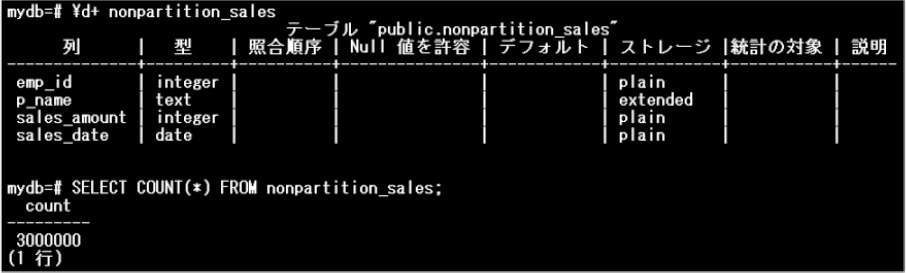
サンプルを使用し、パーティションテーブルとパーティションテーブルでないテーブルに対する検索を比較することで、パーティション・プルーニングの効果を確認してみましょう。サンプルで使用するsalesテーブルは、sale_date列をパーティションキーとするレンジパーティションです。3つのパーティションに分割されています。また、nonpartition_salesテーブルはパーティションテーブルではありません。
salesテーブル
nonpartition_salesテーブル
-
nonpartition_salesテーブルに対し、salesテーブルのパーティションキーであるsales_dateを検索条件に指定したSQLを実行し、実行計画を参照します。
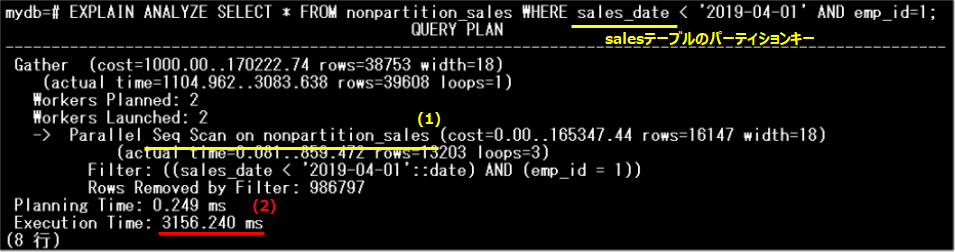
テーブル全体に対する「Seq Scan」が実行されており(1)、実行時間は、3156.240ms(2)となっています。
-
salesテーブルに対し、手順1と同じSQLを実行し、実行計画を参照します。
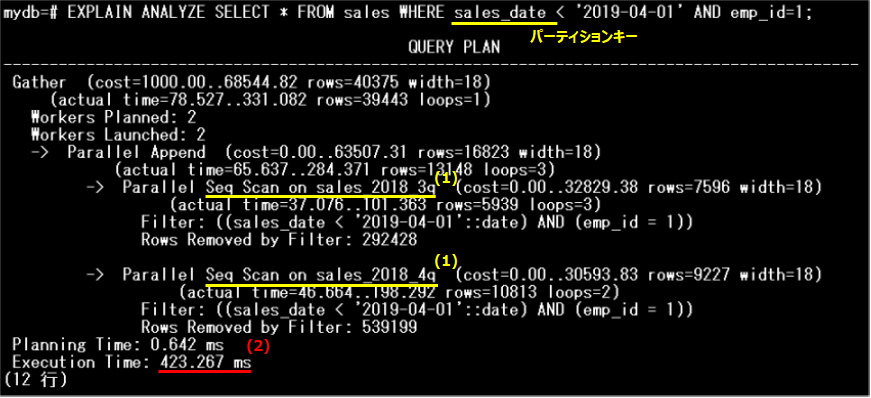
パーティション・プルーニングにより、スキャンの対象がsales_2018_3qパーティションとsales_2019_4qパーティションに絞り込まれ、絞り込まれた各パーティション対して「Seq Scan」が実行されています(1)。手順1と比較すると、以下のように実行時間(2)は約1/8に短縮されており、パーティション・プルーニングの効果が確認できます。
| テーブルの種類 | 実行時間 |
|---|---|
| パーティションテーブルでない場合 | 3156.240ms |
| パーティションテーブルの場合 | 423.267ms |
2. パーティション・ワイズ結合(パーティション同士の結合)
パーティション・ワイズ結合は、パーティショニングされたテーブルに対する結合処理において、パーティション同士を結合する機能です。同じ範囲や値を持つパーティション同士を結合することで無駄な結合処理が省略され、効率的な結合処理を行うことができます。パーティション・ワイズ結合は、PostgreSQL 11以降で利用可能です。
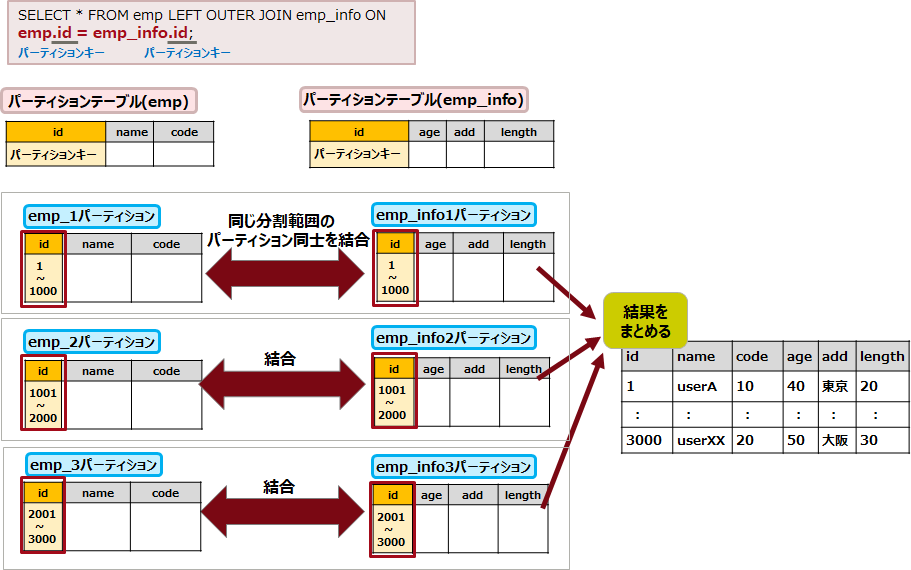
例えば、以下の図では、empテーブルとemp_infoテーブルは、id列をパーティションキーとするパーティションテーブルで、それぞれid列の値が「1から1000」、「1001から2000」、「2001から3000」の範囲でパーティションが作成されています。「emp.id=emp_info.id」の条件で結合する際、emp_1パーティションとemp_info1パーティションは、ともにid列が「1から1000」の値を取りうるため結合条件に合致し、パーティション同士の結合を行います。しかし、emp_1パーティションとemp_info2パーティションでは、id列が取りうる値の範囲が異なり結合条件には合致しないため、パーティション同士の結合を行いません。
パーティション・ワイズ結合を利用するためには、postgresql.confのenable_partitionwise_joinパラメーターをon(デフォルト値:off)に設定する必要があります。
ポイント
- パーティション・ワイズ結合は、実行計画の作成時にCPUやメモリーを多く消費することがあるため、デフォルトでは無効になっています。実際に運用を始める前に機能の利用が有効かどうか(性能向上が見込まれるか)を検証することをお勧めします。
- postgresql.confファイルを編集する、または、SET文を使用することでenable_partitionwise_joinパラメーターのon / offを切り替えることができます。SET文の使用については、「2.1 パーティション・ワイズ結合の例」の「手順3.」を参照してください。
- パラレルクエリを併用することで処理の高速化が期待できます。「【付録】パーティションテーブルに対するパラレルクエリについて」を参照してください。
2.1 パーティション・ワイズ結合の例
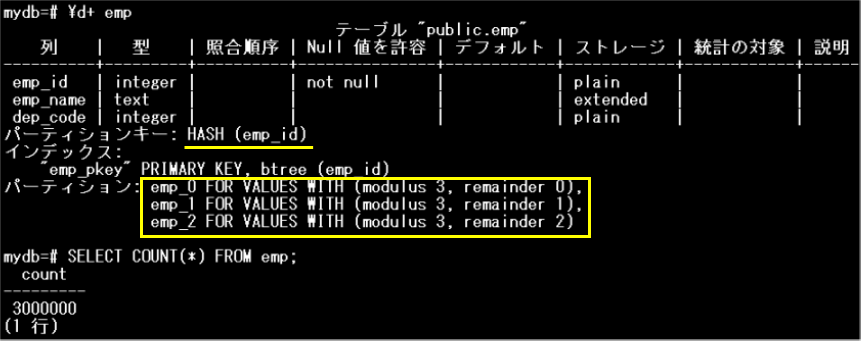
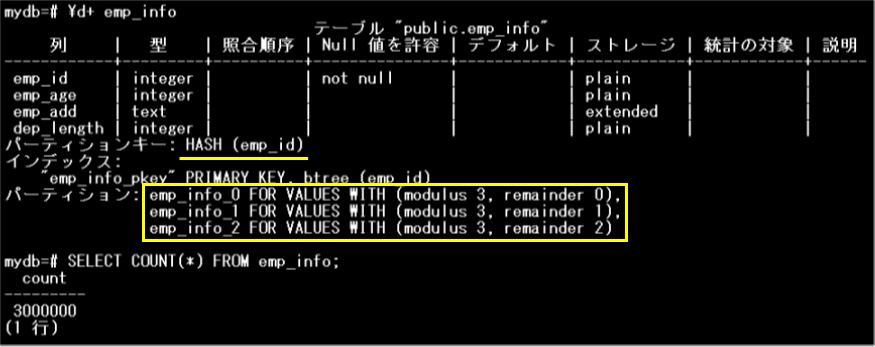
サンプルを使用し、パーティション・ワイズ結合が無効化されている場合と有効化されている場合を比較することで、その効果を確認してみましょう。サンプルで使用するempテーブルとemp_infoテーブルは、emp_id列をパーティションキーとするハッシュパーティションです。同じ条件でそれぞれ3つのパーティションに分割されています。
empテーブル
emp_infoテーブル
-
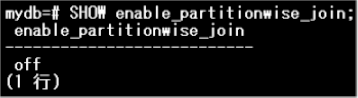
パーティション・ワイズ結合が無効化されている(enable_partitionwise_joinパラメーターがoff)ことを確認します。
-
emp_idを結合キーとしてテーブルを結合するSQLを実行し、実行計画を参照します。
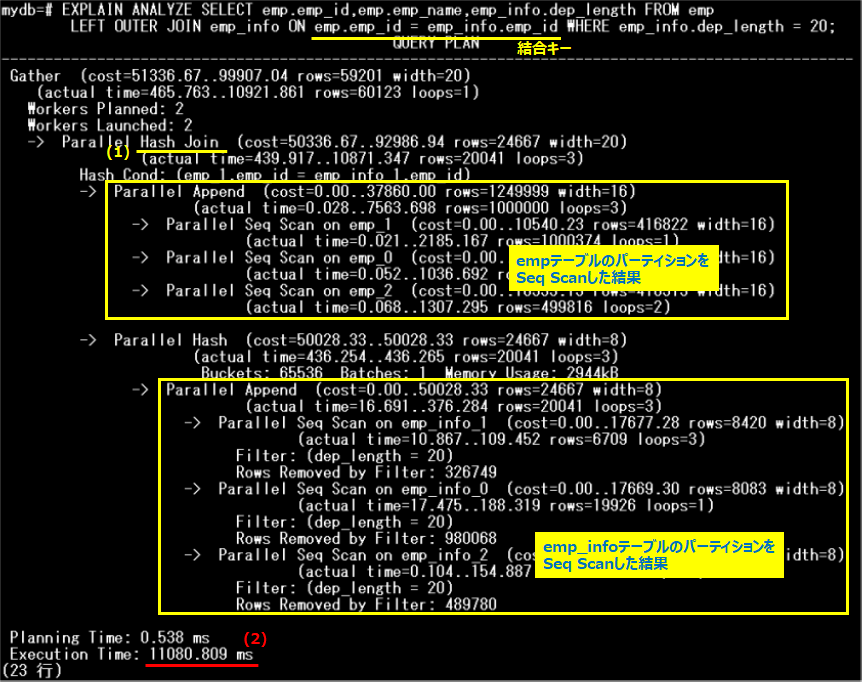
empテーブルのパーティションをスキャンした結果とemp_infoテーブルのパーティションをスキャンした結果を別々に取得し、最後に結合処理が行われています(1)。また、実行時間は、11080.809ms(2)となっています。次に、パーティション・ワイズ結合を有効化して、処理を比較してみましょう。
-
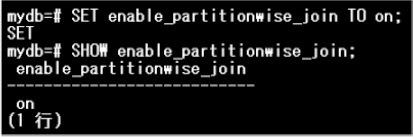
パーティション・ワイズ結合を有効化するため、enable_partitionwise_joinパラメーターをonに設定します。
-
手順2と同じSQLを実行し、実行計画を参照します。
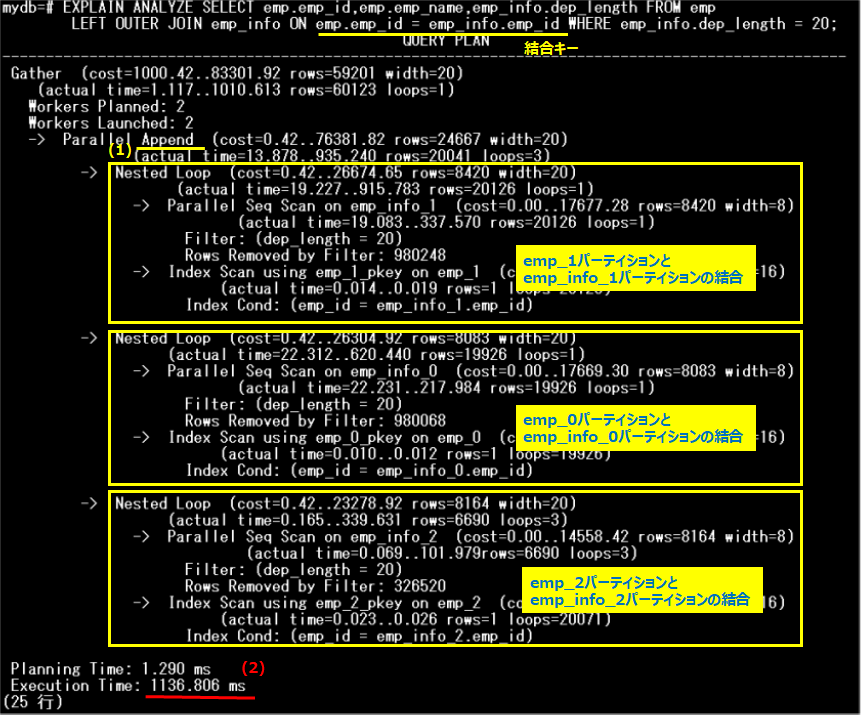
emp_1パーティションとemp_info1パーティションのようにパーティション同士が「Nested Loop」で結合され、最後にそれらの結果をまとめています(1)。手順2のパーティション・ワイズ結合が無効化されている場合と比較すると、以下のように実行時間(2)は約10分の1に短縮されています。
| パーティション・ワイズ結合 | 実行時間 |
|---|---|
| 無効化 | 11080.809ms |
| 有効化 | 1136.806ms |
これは、パーティション同士の結合において、データの絞り込みの処理が変化し、高速な処理が実現できているためです。
ポイント
パーティション・ワイズ結合の有効化/無効化により、実行計画が変更されます。この機能により、最適な絞り込みに合わせ、結合方式も最適化されることがあります。
3. パーティション・ワイズ集約(パーティション同士の集約)
パーティション・ワイズ集約は、パーティショニングされたテーブルに対する集約処理において、パーティションごとに集約処理を行い、最後にその結果を統合する機能です。パーティション単位に集約処理を行うことで処理時間が短縮できます。パーティション・ワイズ集約は、PostgreSQL 11以降で利用可能です。
例えば、以下の図では、各パーティションにおいて集約処理が実行され、最後に結果が統合されます。
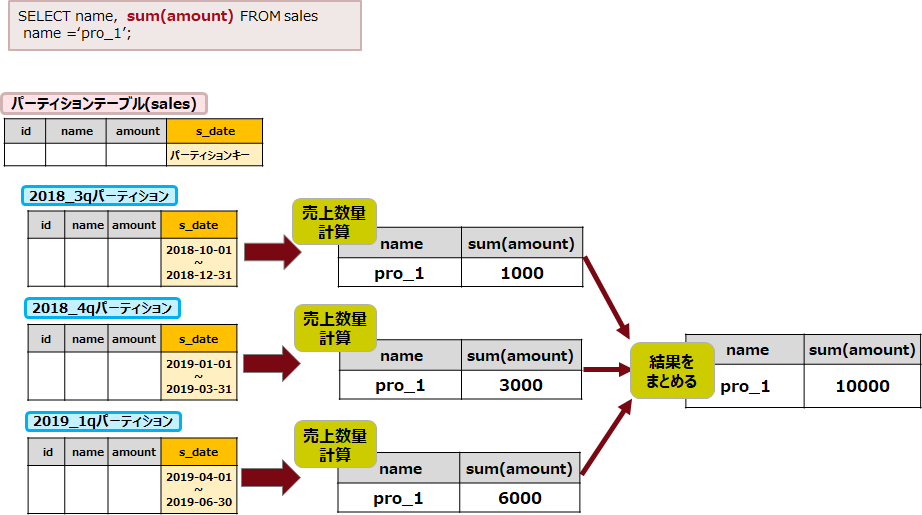
パーティション・ワイズ集約を利用するためには、postgresql.confのenable_partitionwise_aggregateパラメーターをon(デフォルト値:off)に設定する必要があります。
ポイント
- パーティション・ワイズ集約は、実行計画の作成時にCPUやメモリーを多く消費することがあるため、デフォルトでは無効になっています。実際に運用を始める前に機能の利用が有効かどうか(性能向上が見込まれるか)を検証することをお勧めします。
- postgresql.confファイルを編集する、または、SET文を使用することで、enable_partitionwise_aggregateパラメーターのon / offを切り替えることができます。SET文の使用については、「3.1 パーティション・ワイズ集約の例」の「手順3.」を参照してください。
- パラレルクエリを併用することで処理の高速化が期待できます。「【付録】パーティションテーブルに対するパラレルクエリについて」を参照してください。
3.1 パーティション・ワイズ集約の例
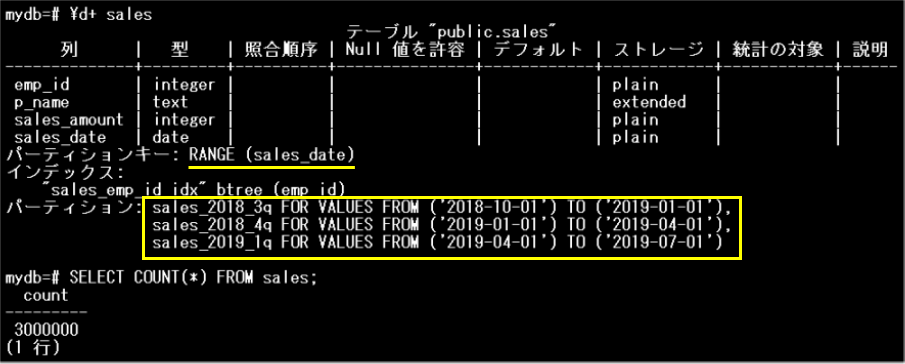
サンプルを使用し、パーティション・ワイズ集約が無効化されている場合と有効化されている場合を比較することで、その効果を確認してみましょう。サンプルで使用するsalesテーブルは、sale_dateをパーティションキーとするレンジパーティションです。3つのパーティションに分割されています。
salesテーブル
-
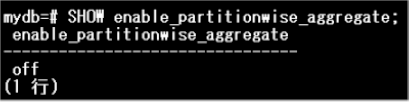
パーティション・ワイズ集約が無効化されている(enable_partitionwise_aggregateパラメーターがoff)になっていることを確認します。
-
集約処理を行うSQLを実行し、実行計画を参照します。
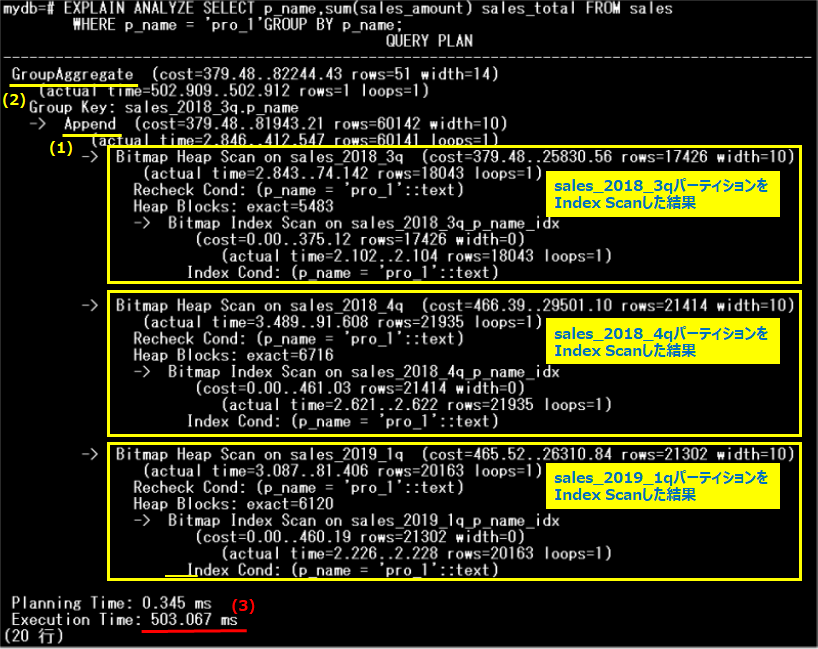
各パーティションに対して「Index Scan」した処理をまとめて(1)、最後に集約処理(2)が実行されています。また、実行時間は、503.067ms(3)となっています。次に、パーティション・ワイズ集約を有効化して、処理を比較してみましょう。
-
enable_partitionwise_aggregateパラメーターをonに設定します。
-
手順2と同じSQLを実行し、実行計画を参照します。
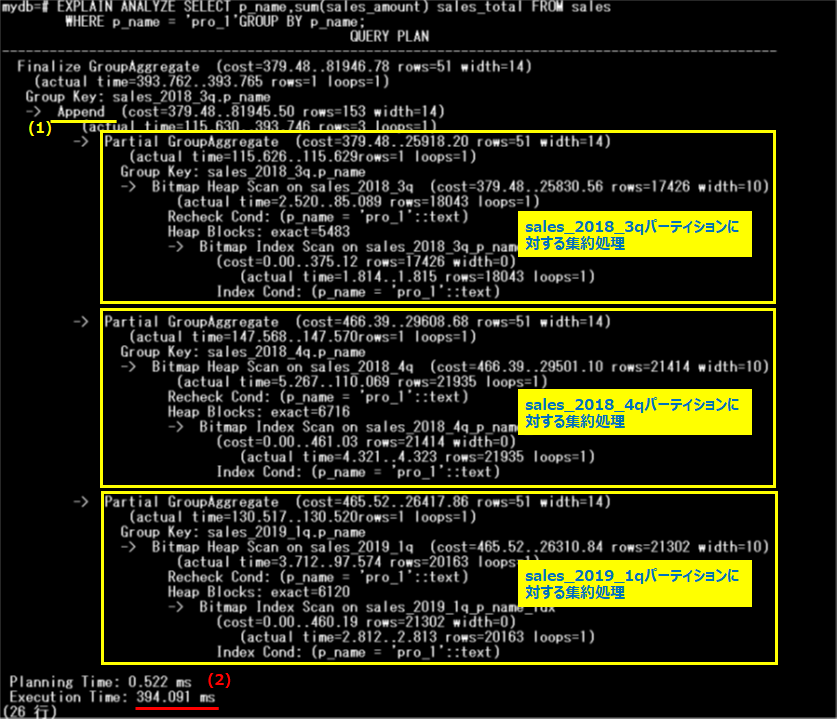
各パーティションで集約処理が実行され、最後に結果をまとめています(1)。手順2のパーティション・ワイズ集約が無効化されている場合と比較すると、以下のように実行時間(2)が短縮されています。
| パーティション・ワイズ集約 | 実行時間 |
|---|---|
| 無効化 | 503.067ms |
| 有効化 | 394.091ms |
これは、各パーティションで集約処理が実行されることで、「Append」(1)の対象行数が少なくなり、Append処理の高速化が実現できているためです。
ここでは、サンプルを使用し、パーティショニングの性能向上のしくみを解説しました。性能向上のしくみを正しく理解した上で、パーティショニングのテーブル設計や運用設計を実施してください。
【付録】 パーティションテーブルに対するパラレルクエリについて
パラレルクエリは、1つのSQLを複数のプロセスで並列に実行する機能です。複数のCPUに処理を分散させて並列に実行することで性能向上を実現します。パラレルクエリについての詳細は、“PostgreSQL 11.1 文書”の“パラレルクエリ”を参照してください。
PostgreSQL 11で、パーティションテーブルに対するパラレルクエリが実行可能となりました。パーティション単位に並列に処理を実行し、最後に結果をまとめることで処理時間が短縮できます。パーティションテーブルに対するパラレルクエリを使用するためには、postgresql.confのenable_parallel_appendパラメーターがon(デフォルト値:on)に設定されている必要があります。以下は、パーティションテーブルに対するパラレルクエリの実行計画の例です。
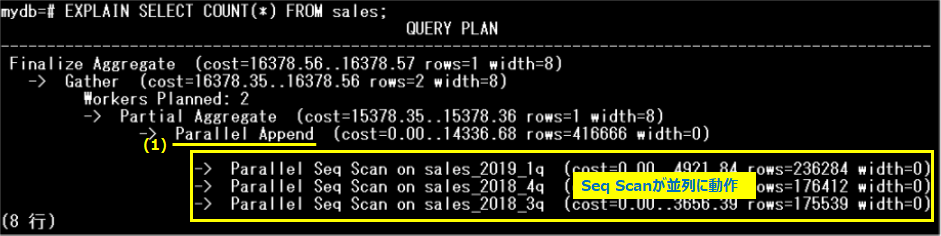
各パーティションに対する「Seq Scan」が並列に動作し、最後に「Parallel Append」(1)で結果をまとめています。
本記事で解説したパーティション・ワイズ結合やパーティション・ワイズ集約は、パラレルクエリと併用することでパーティション単位での結合処理や集約処理の並列実行が可能となるため、更なる性能向上が期待できます。
2019年10月25日公開
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


