

PostgreSQLのアーキテクチャー概要
PostgreSQLインサイド
PostgreSQLには、用途や環境に応じて様々な構成を組み、最適なパフォーマンスで動作させられるよう、設定ファイルpostgresql.confに多くのパラメーターが存在します。そのパラメーターを正しく設定し調整を行うためには、PostgreSQLのアーキテクチャーを理解する必要があります。ここでは、押さえておきたい、PostgreSQLの基本的なアーキテクチャーについて説明します。なお、この記事で対象にしているPostgreSQLのバージョンは9.5以降です。
1. PostgreSQLの基本構成
PostgreSQLの基本的な構成について説明します。はじめに、主なプロセス、メモリー、および、ファイルについての構成図を示します。
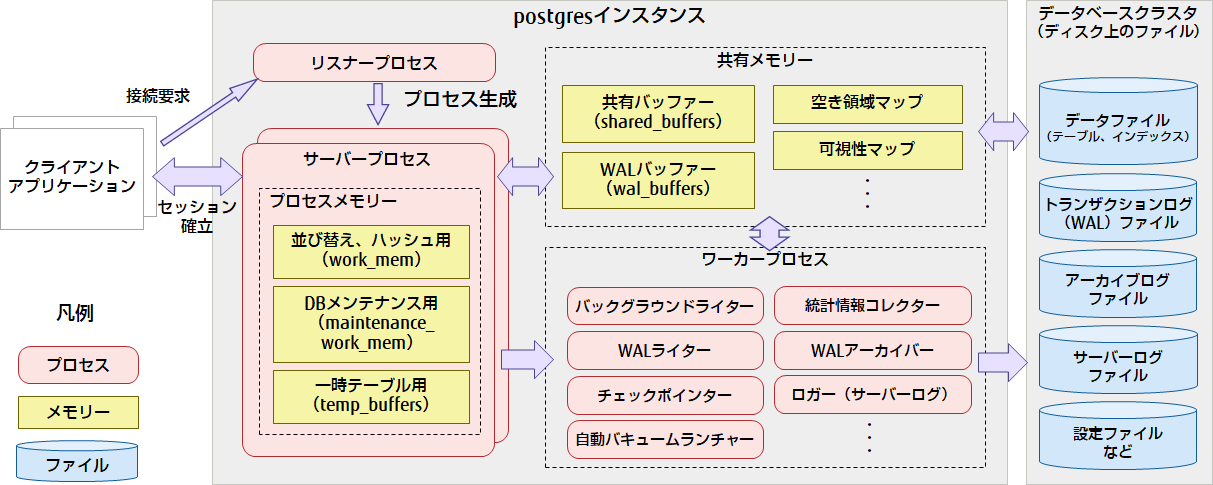
図1 PostgreSQLの基本構成
PostgreSQLを構成する主なプロセス、メモリー、ファイルについて、その用語と概要を説明します。
リスナープロセス
クライアントからリスナープロセスへ接続要求が行われると、リスナープロセスがサーバープロセスを生成し、クライアントとのセッションを確立します。PostgreSQLではマスターサーバープロセスとも呼ばれます。
サーバープロセス
サーバープロセスは、クライアントとのセッションごとに作成されます。PostgreSQLではバックエンドプロセスとも呼ばれます。サーバープロセスは、発行されたSQLの解析と実行を行います。その際の処理用のワークバッファーとして、サーバープロセスごとに確保されたプロセスメモリーを使います。プロセスメモリーは、セッション単位に確保されるため、接続数分のメモリーを消費します。なお、テーブルやインデックスのデータ更新は、データファイルから読み込まれてキャッシュされた共有メモリー上で行います。
共有メモリー
共有メモリーには、「共有バッファー」、「WALバッファー」などの領域があります。共有バッファーには、「空き領域マップ」と「可視性マップ」も含まれます。それぞれの概要を以下に示します。
共有バッファー(shared_buffers)
ディスク上にあるテーブルやインデックスのデータを、ブロック単位で共有メモリー上にキャッシュするための領域です。データファイルは、複数の8,192バイトのブロックで構成されおり、この単位でキャッシュします(OSのシステムキャッシュを経由します)。PostgreSQLのサーバープロセスは、共有バッファー上のテーブルやインデックスのデータにアクセスすることで、ディスクI/Oを削減しパフォーマンスを向上させます。共有バッファーに読み込まれたブロックは、「ページ」と呼びます。なお、各種技術文書では、「ページ」のことを「ブロック」や「バッファー」と表現されることもあります。
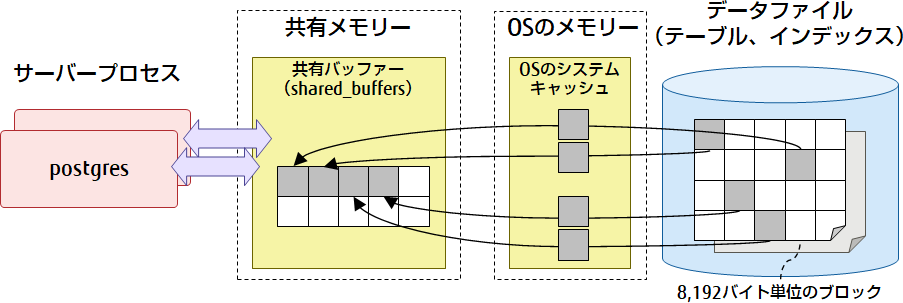
図2 共有バッファー(shared_buffers)
WALバッファー(wal_buffers)
PostgreSQLに更新要求があると、トランザクションの更新ログである先行書き込みログ(WAL:Write Ahead Logging)をWALバッファーに書き込みます。その後、トランザクションがコミットされたとき、あるいは、書き込むべきWALの量がWALバッファーのサイズを超えたときに、WALバッファー内のレコードをトランザクションログ(WAL)ファイルに書き出します。
空き領域マップ
テーブルデータのブロック単位に、レコード(タプル、行とも言います)の空き領域情報を管理します。INSERTやUPDATE時に、空き領域マップが参照され、利用可能な領域を見つけて新しいレコードを挿入します。共有メモリー上の空き領域マップは、VACUUMごとに更新してファイルに書き出し、PostgreSQLの再起動時に読み込まれます。テーブルの1ブロック(ページ)ごとに1バイトの領域を使用します。データファイル上は、“テーブルのファイル名_fsm”というファイル名でテーブルファイルと同じディレクトリー内に格納されます。
可視性マップ(ビジビリティマップ)
テーブルデータのブロック単位に、全レコードが可視(不要なレコードが1つも存在しない、かつ、どのトランザクションからも更新されていない状態)か、否かを管理します。VACUUMの高速化、および、高速なIndex Only Scan(注1)を処理するために利用されます。可視性マップの利用により、直接テーブルデータを参照する処理を不要とすることで、処理の高速化を実現します。共有メモリー上の可視性マップは、SQLの更新処理やVACUUMごとに更新してファイルに書き出し、PostgreSQLの再起動時に読み込まれます。テーブルデータの1ブロック(ページ)ごとに2ビットの領域を使用します。データファイル上は、“テーブルのファイル名_vm”というファイル名でテーブルファイルと同じディレクトリー内に格納されます。
-
注1SQLを実行する際に内部で実行される、テーブルデータの検索方式の1つです。
ワーカープロセス
主なワーカープロセスについて説明します。これらのワーカープロセスは、postgresインスタンス内に1つずつ起動されるプロセスです。PostgreSQLではバックグラウンドワーカープロセスとも呼ばれます。それぞれの概要を以下に示します。なお、PostgreSQLのプロセスとしては、「自動バキュームワーカー」や「パラレルワーカー」のように、必要に応じて、必要な数だけ起動されるプロセスもあります。
バックグラウンドライター
共有バッファー内の空き領域を空けるため、共有バッファー内で更新されたダーティページ(注2)を、少しずつデータファイルに書き出します。
WALライター
WALバッファー(wal_buffers)内のWALレコードをWALファイルに書き出します。
チェックポインター
PostgreSQLではクラッシュした場合のリカバリー開始位置をチェックポイントとして記録するため、共有バッファー内のすべてのダーティページ(注2)をデータファイルに書き出します。その後、特殊なチェックポイントレコードをトランザクションログ(WAL)に書き出すことで、クラッシュ時に復旧開始位置を見つけられるようにします。この処理は、定期的に実行されます。なお、大量の更新SQLが実行されダーティページが多い場合には、多くのI/Oが発生することが予想されます。
自動バキュームランチャー
自動バキュームワーカーを起動し、自動バキューム(autovacuum)を実行させるプロセスです。自動バキュームワーカーは、データの更新や削除で発生した不要領域を再利用できるようにし、さらに、クエリ実行時に使用する統計情報を更新します。
統計情報コレクター
データベースの活動状況に関する情報を統計情報として定期的に収集します。収集した結果は、システムビュー(pg_stat_***)を参照することで確認できます。
WALアーカイバー
ポイントインタイムリカバリー(PITR:Point In Time Recovery)時のリカバリーや、ストリーミングレプリケーション時のWALの受け渡しに利用できるよう、WALファイルをアーカイブログファイルに書き出します。利用する場合は、設定ファイルのパラメーターでWALアーカイブに関する設定を行う必要があります。
ロガー
PostgreSQLのサーバーログを、サーバーログファイルへ書き出します。
-
注2共有バッファー内でデータの更新が行われ、ファイルへの書き出しが必要になったページです。
データファイル(テーブル、インデックス)
テーブルやインデックスのデータを格納するファイルであり、基本的に1つのテーブルやインデックスごとに、1つのファイルが作成されます(注3)。また、1つのデータファイルは複数の8,192バイトのブロックで構成されます。テーブルファイルの場合、そのブロック内に実データのレコード(タプル、行とも言います)が配置されます。レコードを追加する際にブロックの容量がいっぱいになると、ファイルを拡張させて次のブロックを追加します。
-
注3ファイル容量に制限のあるプラットフォームに対応できるよう、データファイルが1ギガバイトを超えると、ギガバイト単位のセグメントに分割されます。分割されたデータファイル名は、“データファイル名.1”、“データファイル名.2”のように番号が付加されていきます。なお、セグメント容量はPostgreSQLをビルドする際の--with-segsizeオプション(デフォルトは1ギガバイト)を使用して調整することができます。
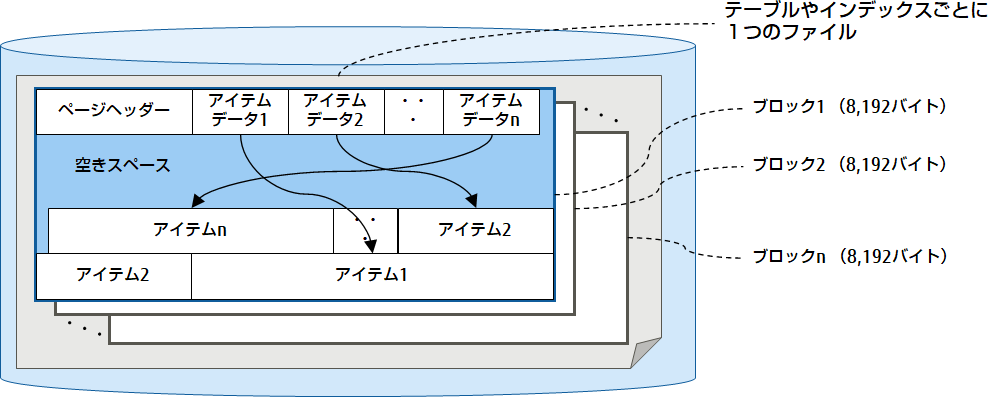
図3 データファイル(テーブル)
インデックスファイルの場合、B-treeインデックスを例に挙げると、共有バッファー上でルートページ、インターナルページ、リーフページがポインターでつながれ1つの木構造として構成されます。データファイル上では、先頭の制御用のメタページに続いて、各ページが8,192バイトのブロックとして格納されます。

図4 データファイル(B-treeインデックス)
トランザクションログ(WAL)ファイル
トランザクションの更新ログを格納するファイルです。WALバッファー上のデータは、複数のWALレコードをシーケンシャルに16メガバイト単位のファイルに分割し、WALファイルに書き出します。WALファイルは、リカバリーの際に利用されます。
アーカイブログファイル
WALファイルを別の領域へアーカイブしておくためのファイルです。
サーバーログファイル
PostgreSQLのサーバーログを書き出すためのファイルです。
2. PostgreSQLの主なアーキテクチャー
PostgreSQLの基本的なアーキテクチャーについて説明します。
追記型アーキテクチャー(テーブル、インデックス)
PostgreSQLでは、追記型アーキテクチャーを採用することで、MVCC(Multi Version Concurrency Control:多版型同時実行制御)というトランザクションの同時実行制御方式を実現しています。そのため、UPDATE文などでテーブルやインデックスのレコードを更新する際には、元のデータに削除マークを付けて残しておき、更新後のレコードを追記します。また、DELETE文でレコードを削除する場合も削除マークを付けて元のレコードを残しておきます。なお、削除マークが付けられたレコードは不要領域となり再利用ができません。そのため、データの更新が多い運用の場合にデータファイルのサイズが増加することから、データファイルのサイズを見積もる際には、更新量に応じて、実際に扱うデータの量よりも多めに見積もっておく必要があります。
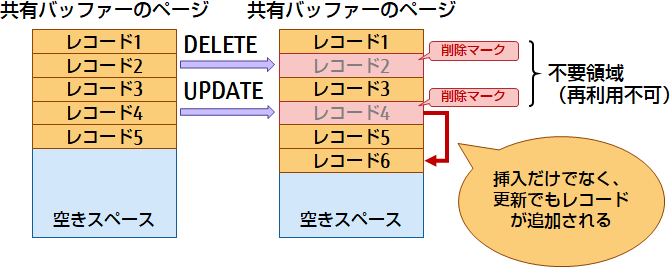
図5 追記型アーキテクチャー
VACUUM(バキューム処理)
VACUUMは、テーブルやインデックスのレコードの更新や削除によって発生した不要領域を再利用できるよう処理します。また、クエリ実行時に使用する統計情報の更新も同時に行います。なお、PostgreSQLではautovacuumという機構が、初期状態で自動で動作するよう設定されているため、通常は自動で不要領域の解消が行われます。ただし、更新頻度が高い場合には、不要領域の解消が間に合わず、データ量の肥大化につながることがあります。その場合、autovacuumの設定値の調整や、VACUUM FULLコマンドで不要領域を削除し、データ量の肥大化を抑えることを検討します。なお、VACUUM FULLコマンドは、テーブルに強いロックがかかる点と、処理に時間がかかる点を十分に考慮した上で利用する必要があります。
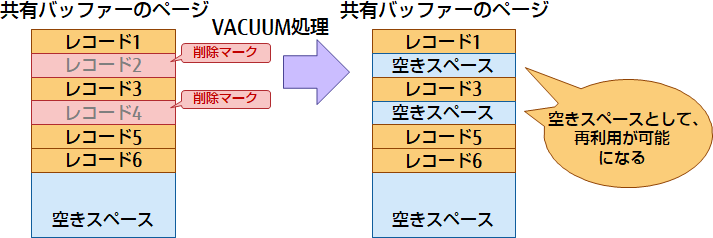
図6 VACUUMについて
データ更新とチェックポイント処理
PostgreSQLは、テーブルやインデックスなどのデータを更新する際、共有バッファー上にキャッシュされたデータにアクセスしますが、共有バッファー上で更新されたダーティページはすぐにデータファイルへ書き出されません。その代わりに、トランザクションの更新ログ(WAL)をWALバッファーに順次格納していき、COMMITのタイミングでWALファイルへ書き出されます。これは、データベースの更新処理の高速化と、障害発生時のデータ保証を両立するための機構です。しかし、このままでは共有バッファー上にダーティページが増え、WALファイルも大量に溜まってしまいます。そのために必要なのが、チェックポイント処理です。チェックポイント処理は、定期的に、共有バッファー上のすべてのダーティページをデータファイルへ書き出し、それによって不要になったWALファイルを削除します。これらの構成とデータの流れを図示すると図7のようになります。
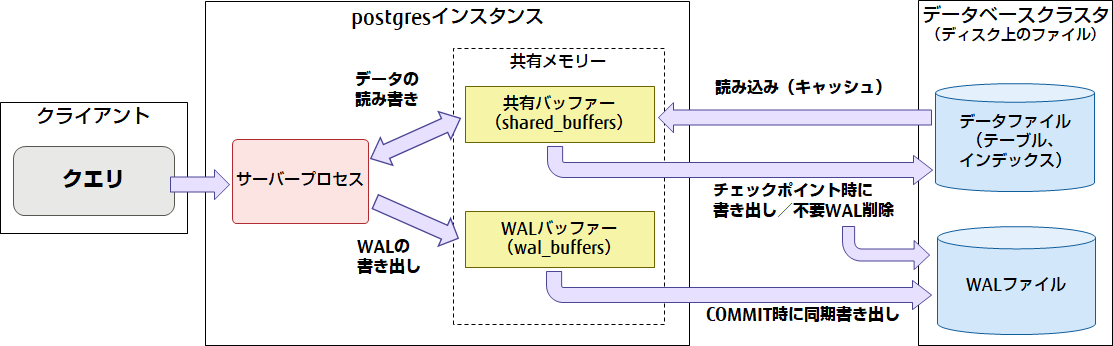
図7 PostgreSQLのデータ更新の流れ
SQLが実行される仕組み
クライアントからPostgreSQLに対してSQLが発行されると、「パーサー」がそのSQL文が正しい構文になっているかをチェックします。次に、データベースにルール(SQLを置き換える規則)が定義されている場合、「リライター」がその規則に従って他のSQLに書き換えます。そして、「プランナー(オプティマイザー)」が、対象のテーブルやインデックスのデータ量やばらつきなどの統計的な情報が保持されている『統計情報』を参照しながら、取り得る処理パターンをすべて比較して最適で高速に実行できる手順を決定し、その手順を『実行計画』として作成します。最後に、「エグゼキューター」がその『実行計画』に沿ってSQLを実行し、処理結果をクライアントに返します。
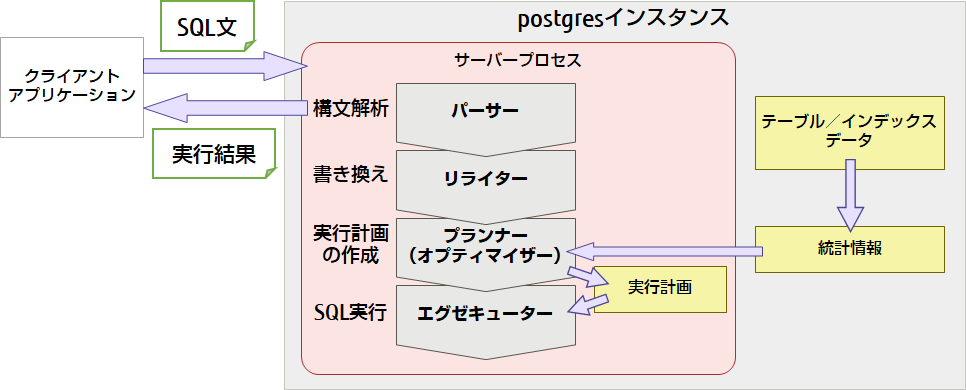
図8 SQLの実行処理
3. 参考情報
PostgreSQLのアーキテクチャーと、設定ファイルpostgresql.confの重要なパラメーターとの関係や注意点を示します。なお、図9の赤字のキーワードは、postgresql.confの実際のパラメーター名です。
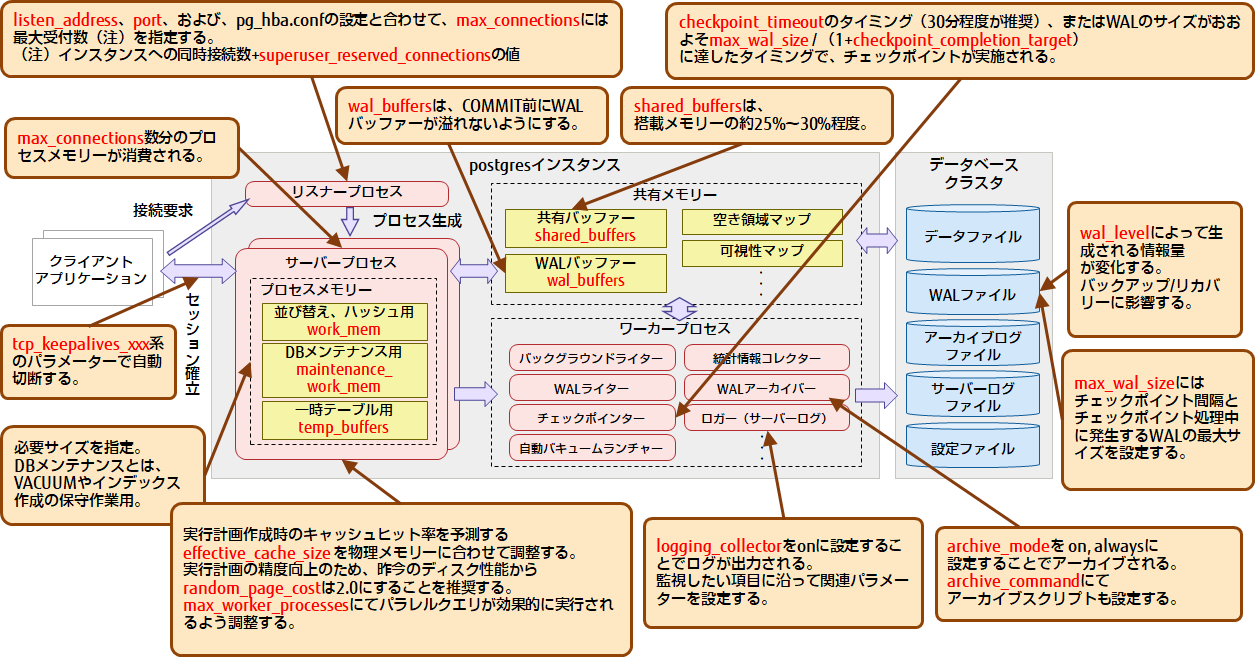
図9 アーキテクチャーと重要パラメーターとの関係
以上、PostgreSQLの主なアーキテクチャーについて説明しました。機能、および、設定ファイルのパラメーターの詳細については、PostgreSQLのマニュアルを参照してください。
2021年3月12日公開
こちらもおすすめ
富士通のソフトウェア公式チャンネル(YouTube)
-
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
- 富士通のミドルウェア製品のご紹介や各種イベント・セミナーの講演内容、デモンストレーションなどの動画をご覧いただけます。
PostgreSQLについてより深く知る
PostgreSQLに興味をお持ちのお客様はこちらのコンテンツもお勧めです。ぜひご覧ください。


