
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
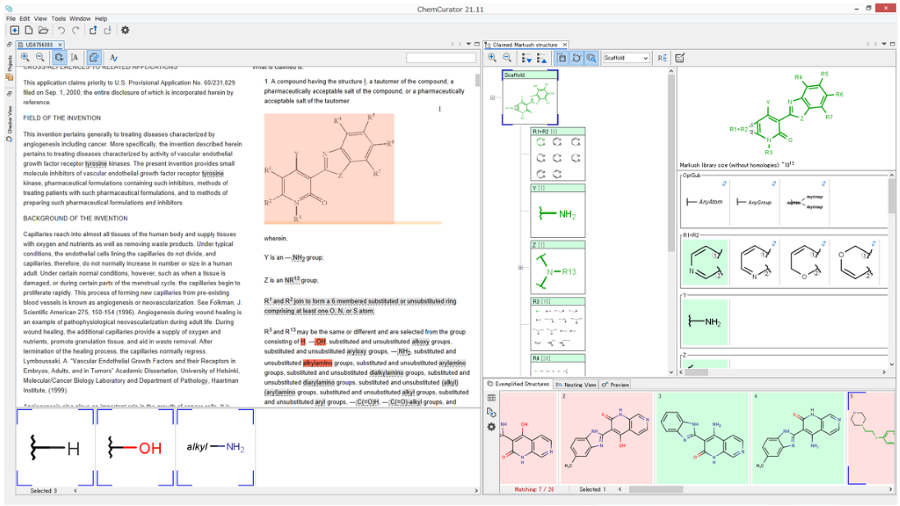
Document to Structure
|
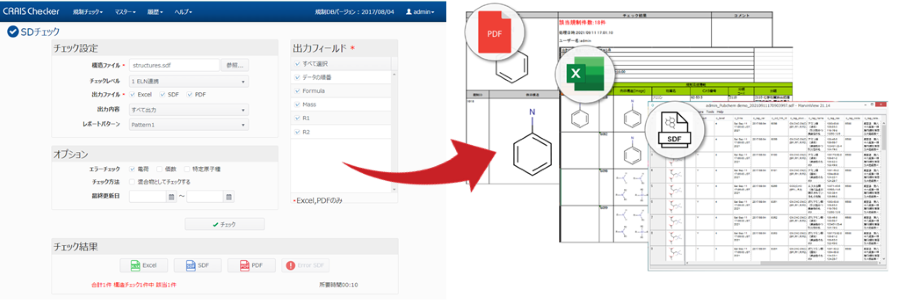
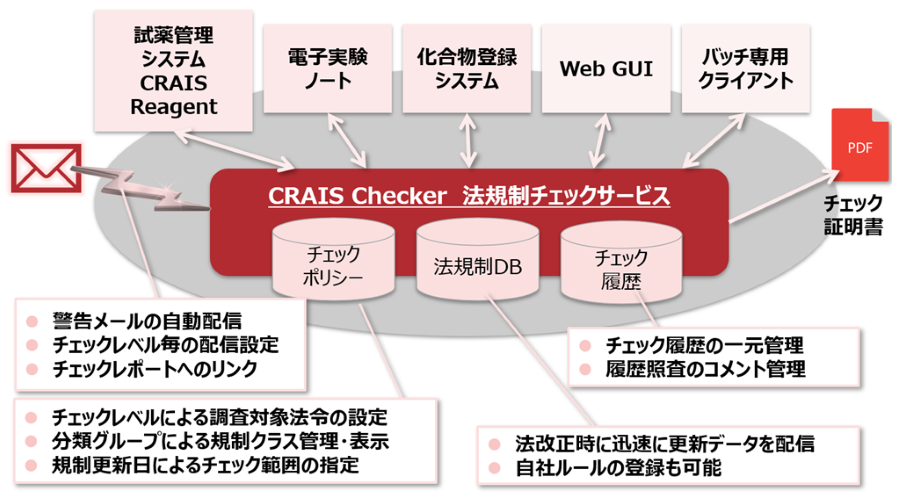
製品概要
PDFなどの文書から構造情報を高速に抽出し、論文・特許解析を加速
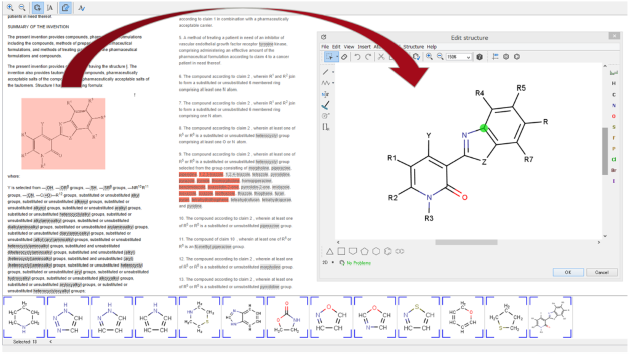
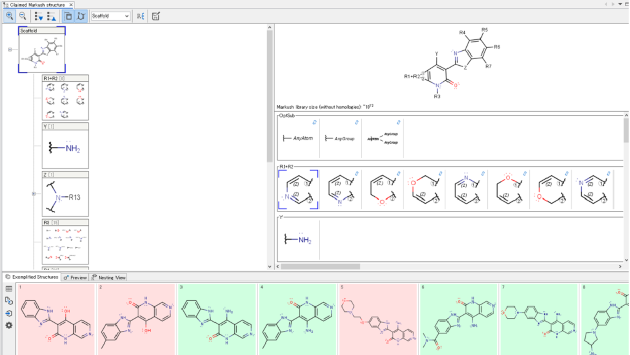
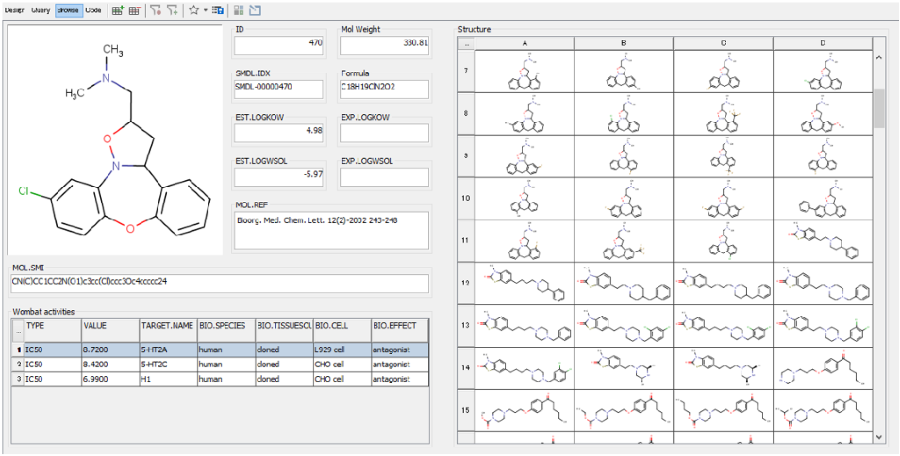
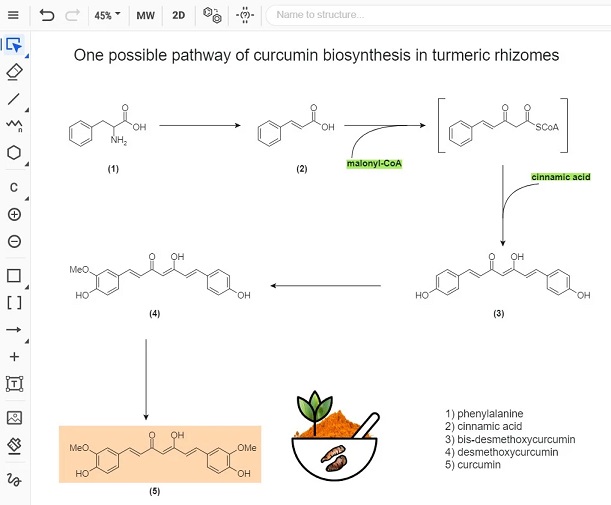
化学ドキュメントまたはデータはさまざまな形で、さまざまな場所に存在します。 またそれらの化学文献、内部レポート、特許情報などは、名称、構造形式、画像形式など複数のフォーマットで表現され、情報の抽出をより困難にします。 Chemaxonの化学テキストマイニング技術は、さまざまな非構造リソースから全ての化学データを抽出・統合され、構造化されたナレッジベースを構築するためのソリューションを提供します。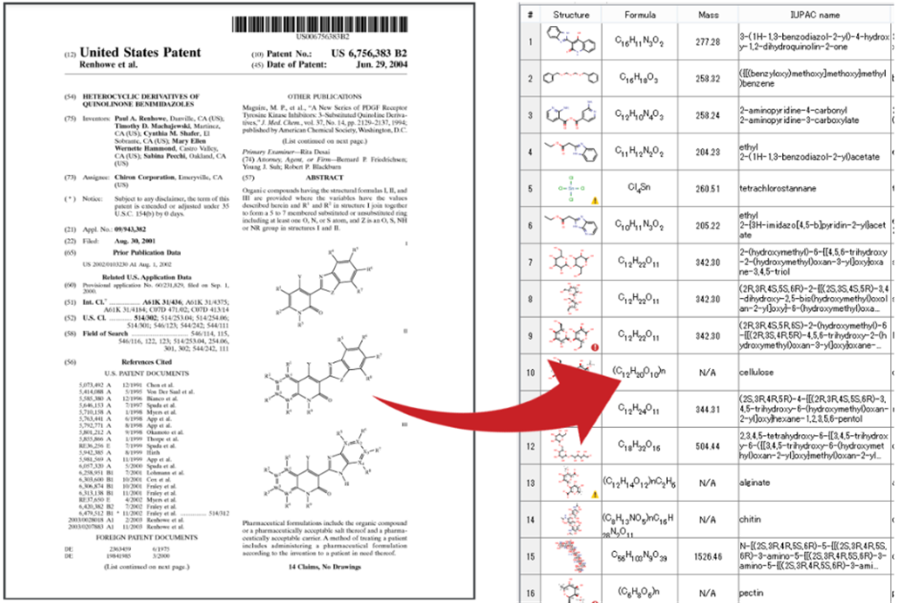
特長
ドキュメントから化学情報を自動抽出
- Chemaxon独自の技術による高い構造変換率と正確性で化学ドキュメントの自動的なマイニングを実現します。
- 抽出位置情報(ページ、コンテキスト)も含めて取得され、文献の管理など、効率的な情報の検索を可能とします。
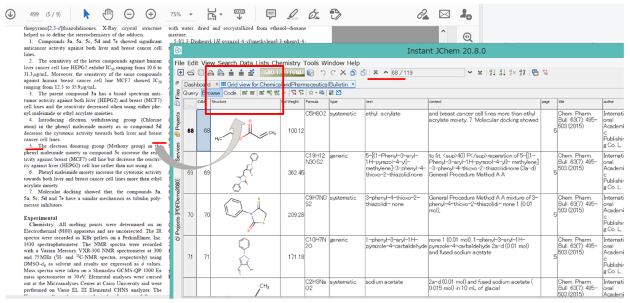
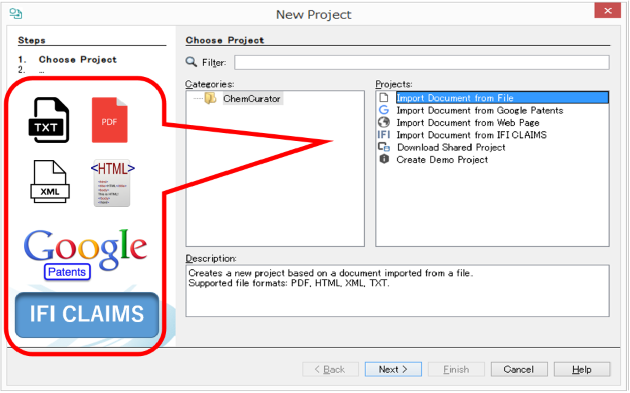
D2Sで変換できる文章フォーマット
- PDF(Text PDF, Non-searchable PDF)、TXT、HTMLXML、Microsoft Officeドキュメント(DOC, DOCX, PPT, PPTX, XLS, XLSX)など、幅広いドキュメントファイル形式の読み込みをサポートします。
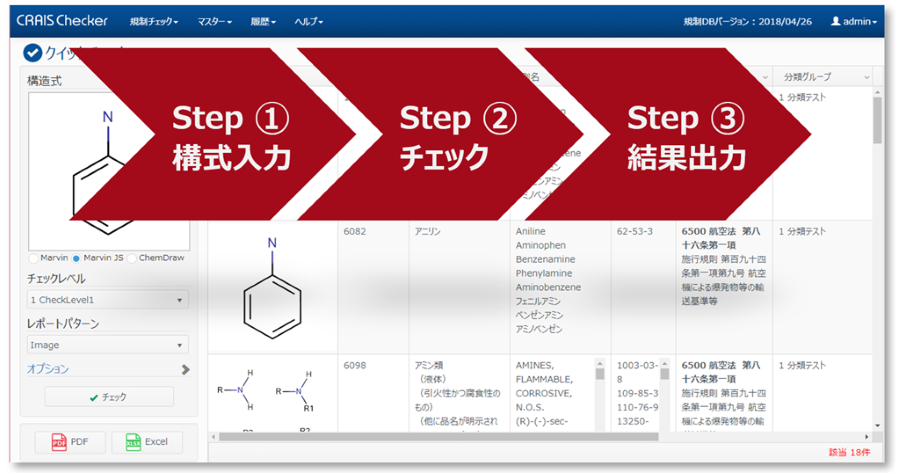
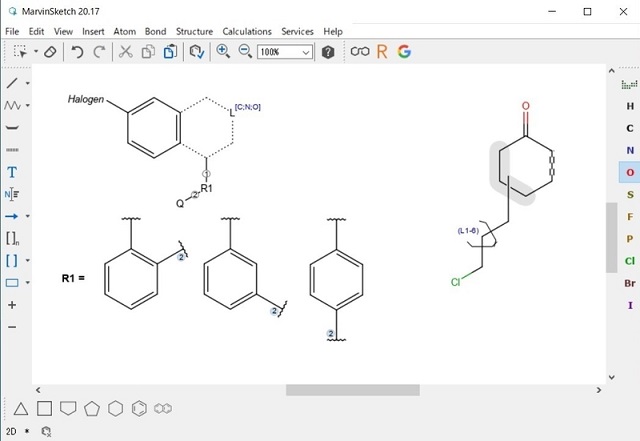
化学名を構造情報に変換 - Name to Structure
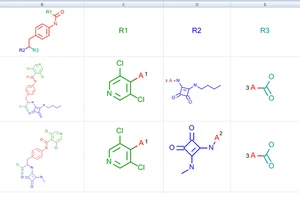
- 化学名(IUPAC名、一般名、商品名など)やCAS番号、SMILES、InChIなどの文字列から化学構造式に変換することができる機能です。
- 名称の他、辞書機能も搭載されており、自社化合物IDからの変換もサポートします。
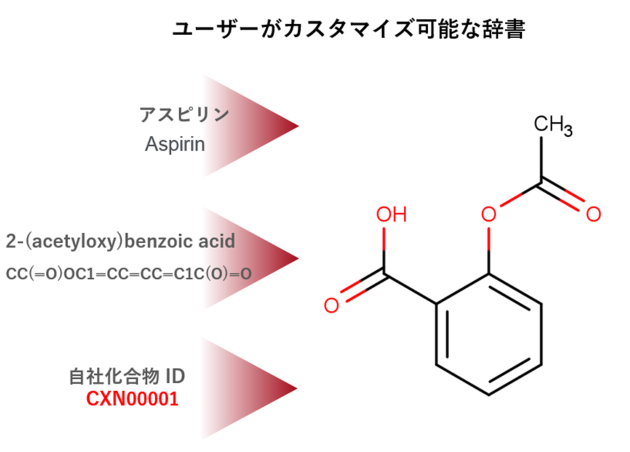
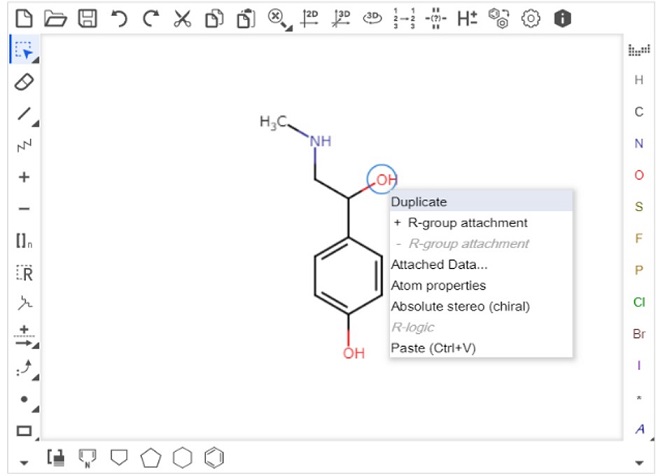
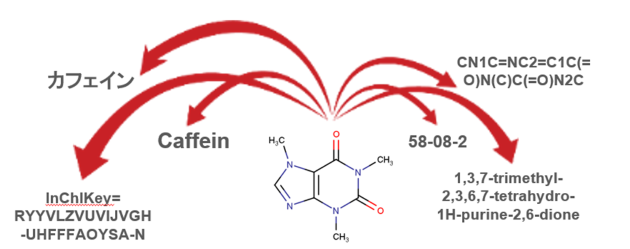
構造情報から化学名称に変換 - Structure to Name
- 構造情報から各種化学情報への変換もサポートします。
- さまざまなソフトウェアを介して、化学情報の読み込み・閲覧・解析・加工などが行えます
研究者のこのような悩みを解決
|
|
膨大な量のファイルからの目的の情報を探すには多大な労力がかかる |
|---|---|
|
|
ファイルを指定するだけで、自動解析し位置を特定することが可能です |
|
|
テキスト化されていないPDFに対しては、文字列による検索が行えない |
|---|---|
|
|
"Non Text PDF"にも対応しているので、解析業務を一気に効率化します |
|
|
描画ツールを用いても、化合物を一から作画するのが大変である |
|---|---|
|
|
テキストから構造式を呼び出し、瞬時に構造を描画可能です |
|
|
様々なファイル形式が存在し、種類によって情報の特定方法が異なる |
|---|---|
|
|
幅広いファイル形式に対応しており、抽出後にデータの一元管理が可能です |
動画
Overview: Document to Structure

Overview: Japanese Name to Structure
価格・動作環境
詳細はお問合せください
Patcore に関するお問い合わせ
-
Webでのお問い合わせ
入力フォーム当社はセキュリティ保護の観点からSSL技術を使用しております。
-
お電話でのお問い合わせ
【富士通コンタクトライン総合窓口】
0120-933-200(通話無料)受付時間:9時~12時および13時~17時30分(土曜・日曜・祝日・当社指定の休業日を除く)