ここ数年、Deep Learning(ディープラーニング)をはじめとする機械学習技術の急速な進化により、様々なビジネスにAI(人工知能)を活用しようという機運が高まっています。しかし、ディープラーニングによって学習したAIには、「AIがどうしてそのような“答え”を導き出したのか人間には分からない。説明できない」という、いわゆるAIのブラックボックス問題があり、重要分野でのAI活用の妨げになっています。こうした課題の解決を目指し、富士通研究所が開発した独自の新しい機械学習技術が「Wide Learning™」です。
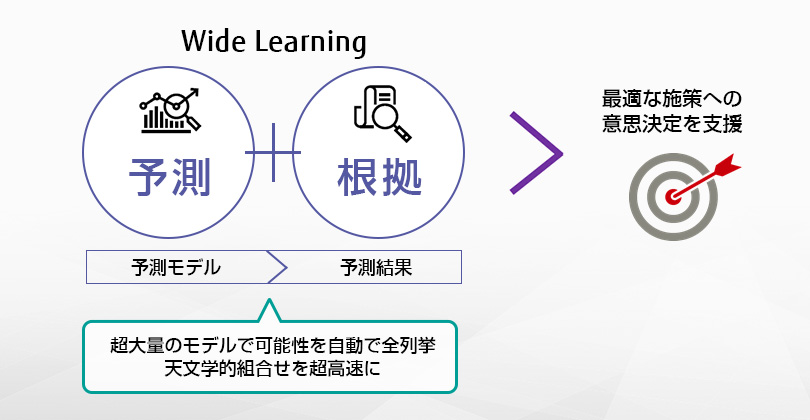
Wide Learning™は、学習するデータの中から項目の組合せをもれなく抽出し、人間にも分かりやすい『判断の根拠となる有用な仮説』を提示する機械学習技術であり、『説明可能なAI(Explainable AI)』の一つです。説明可能なAIは 2010年代中頃からその必要性が広く認識されるようになり、米国をはじめとする様々な国で研究開発が進められています。日本政府が主導してまとめられた、2019年 6月の G20 貿易・デジタル経済大臣会合での閣僚声明にも「AI原則」が盛り込まれており、同原則では、「人間中心のAI」を追求するため、「人間中心の価値観および公平性」、「透明性及び説明可能性」、「アカウンタビリティ」などを求めています。
「ディープラーニングによる典型的なAIは、判断プロセスがブラックボックスになっているために『なぜそういう判断をしたのか』を人間が伺い知ることができません。そうしたAIが出した判断結果を採用すべきかどうかが問題になりつつあります。一方、Wide Learning™のナレッジチャンクは人が見て理解しやすい形式であるため、AIが下した判断の根拠を人間が理解できるというわけです」
「説明可能性を実現するための手法はいくつかあります。その一つにディープラーニングのような複雑なモデルを人が理解しやすいように局所的に近似するというやり方もあります。私たちはそうした手法ではなく、最初から人が理解しやすいモデルを構築するというアプローチをとっています」
ここで着目したのが、膨大なデータの組合せを「列挙する」というアプローチです。
「Wide Learning™は、ありとあらゆるデータ項目の組合せを列挙したうえで根拠となるナレッジチャンクを見つけて予測しますが、データ項目が増えるとその組合せ数は指数的に増加します。この膨大な組合せから有用なものを高速に列挙するためのアルゴリズムは学術界において長年研究され、かつ進化を続けてきた分野でもあります。富士通研究所では、無駄なものを取り除き、必要なものだけを高速に列挙するという技術の研究開発に取り組み、Wide Learning™を誕生させました」(高木)
この技術は、1990年代に九州大学の有川節夫名誉教授が提唱した「ディスカバリーサイエンス(発見科学)」をベースに、富士通研究所と大学との共同研究によって発展させてきたものです。富士通研究所では2015年に前総長である有川名誉教授を招聘し、「有川ディスカバリーサイエンスセンター」を設置。同センターを拠点に人が理解できる機械学習の確立に取り組み、その成果として誕生したのがWide Learning™です。これによって、人が理解できる仮説を使用した透明性の高いAIが実現され、少ない手持ちのデータだけでAIの適用を可能にし、仮説の列挙によってさらなる知識発見に導くことが可能になりました。
このように知識発見と説明可能性を両立するWide Learning™は、すでに様々なビジネス領域での実証が進められています。とりわけWide Learning™が強みを発揮するのは、AIの透明性・説明性が求められる業務、例えば、生産現場での不良品検知、広告出稿などのマーケティング、融資のための与信・審査、新薬開発等のための疾病要因分析などのビジネス領域です。
現在、人工知能研究所 オートノマス機械学習プロジェクト内の13名でWide Learning研究グループを作り、研究開発を進めています。
Wide Learning研究グループは、大きく分けて「実践」と「技術開発」の2つのチームによって進められています。実践チームはWide Learning™の事業化に向けた実践を推進する役割、技術開発チームはWide Learning™の基本技術、今後実用化を目指す先端技術を研究開発する役割を担っています。テーマによってはチーム横断的に連携して取り組んでいます。
「実践チームは富士通の営業やSEとも連携しながら、Wide Learning™によるお客様の課題解決を支援し、新しいビジネスの創出などに取り組んでいます。難しい課題がある場合には、Wide Learning™をどのように適用すれば要望に近いアウトプットが得られるか検討するため、研究員がお客様先に同行して、課題や手持ちのデータなどについて直接お伺いすることもあります。例えば、お客様のデータが少なくて精度が高まらない場合には、オープンデータを組み合わせて精度を高めるなど様々な工夫もしています」(吉田)
「私も技術開発チームに所属しており、Wide Learning™の基礎技術である「列挙」の更なる高速化や、理論的・実践的な技術革新などに学術界とも共同で取り組んでいます。また、Wide Learning™を社内外で利活用するためのツール開発も担当しています」(高木)
そして、AI/機械学習分野の最先端技術である、このWide Learning™の研究・実践には、様々な分野の知識やスキルを持った研究員が取り組んでいると言います。
「例えば自然言語処理や知識処理など、研究員一人ひとりが持つ様々な研究分野の知識を活かして、幅広いビジネス領域へのWide Learning™の適用と技術の向上を進めています。Wide Learning™の次の一手を生み出すべく、様々なバックグラウンドを持つ研究員たちが議論しながら、チームとして新たな研究開発に取り組んでいるところです」(小栁)
2018年9月に技術を発表して以来、様々なビジネス領域での実証が行われているWide Learning™ですが、さらに多くの期待に応えるべく、富士通研究所の今後の取り組みについて語ります。
「Wide Learning™の適用分野・適用実績をさらに増やし、Wide Learning™を最大限に活用するための知識やノウハウを蓄積していきたいと思います。また、Wide Learning™の適用を増やしていくとクリアすべき課題がいろいろと見つかると思いますので、適時、技術開発チームにフィードバックし、Wide Learning™の性能・機能向上に貢献したいと考えています。」(吉田)
また、データと結果の関係についての新たな知見を明らかにすることもAI分野において関心の高い課題の1つであり、Wide Learning™が目指すアプローチでもあります。
「これからのWide Learning™は、様々なデータセットの中から得られた結果・仮説を組み合わせ、データの意味関係や適用分野の知見などを考慮して説明することで、より良い知見の獲得や活用を目指していきます」(小栁)
さらに一歩進めて、「予測」から「アクション」へと展開するための新機能の実装も始まっています。Wide Learning™では、例えば、膨大な顧客情報の中から、「どの人が商品Aを購入する可能性があるか」という判断を可能にします。より実用性を高めるために、新たな機能では、例えば「ある人に商品Aを購入してもらうには、次にどのようなアクションを取れば購買率・契約率がアップするのか」を自動的に提示・提案することを実現します。
こうした新機能をどんどん追加しながらWide Learning™はさらに発展・進化していきます。すべての組合せの「列挙」による知識発見と説明可能性の両立によって人間の意思決定を支援し、多くのビジネス領域におけるAI活用の幅を広げていきます。














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}