
Amazon Bedrockの特徴と社内活用事例について紹介します
2025年2月21日 富士通株式会社 ジャパン・グローバルゲートウェイ 上田 裕之
富士通株式会社 ジャパン・グローバルゲートウェイ 大西 智博
はじめに
AWSでは2024年6月に行われたAWS Summit Japan[1]にて、生成AIがキーテクノロジーとして掲げられており、2023年9月にリリースされたAmazon Bedrockは、AWSが提供するフルマネージドの生成AIサービスとして特に注目を浴びています。
本記事では、現在急速に利用が拡大している生成AIサービス Amazon Bedrock(以下Bedrockと表記)について、サービスの特徴と活用事例を紹介します。
Amazon Bedrockについて
Bedrockは2023年9月に一般提供が開始された生成AIのフルマネージドサービスです。
Claudeを提供するAnthropic社やLlamaを提供するMeta社など、様々な大手AI企業が提供する基盤モデル(Foundation Model、以下FMと表記)を単一のAPI経由で使用できるサービスです。
利用可能なFMのラインナップについても拡充を続けており、お客様の生成AIを通じた価値創出を支援します。
また、要件に応じてカスタマイズすることも可能です。
例えば社内のチャットボットとして利用する際に用いられることの多い検索拡張生成(以下RAGと表記)システムを構築するための機能である「Knowledge Bases for Amazon Bedrock」や、悪質なプロンプト(LLMに与える命令文)を拒否するように応答に制限を設ける機能である「Guardrails for Amazon Bedrock」が提供されています。
生成AIアプリケーションを利用する際に注意すべきポイントとして、データ保護の観点が挙げられます。与えたデータやプロンプトから、外部に知られてはいけない秘密情報が学習ソースとして利用され、情報漏洩に繋がる危険性があるということです。
Bedrockでは、RAGシステムを構築した際やファインチューニングを利用してFMをカスタマイズした際など、いずれにおいてもベースモデルの改善等にユーザからのインプット情報が利用されることはありません。ユーザがデータをフルコントロールすることが可能なため、開発者は生成AIアプリケーションの機能開発に集中することができます。
現在、米国東部(us-east-1)リージョンおよび米国西部(us-west-2)リージョンでは7社から合計40種類以上のFMを選択することができ、豊富な選択肢の中から、システムの特性に合わせて柔軟にFMを選択することが可能です。
以上のように、Bedrockは企業が生成AIを導入する際に必要とする機能要件やセキュリティ要件を満たせるように提供されています。
次に、2024年10月時点で利用できるFMや代表的な機能を次に挙げていきます。
(1)Bedrockから基盤モデルを利用できるプロバイダー一覧
Bedrockには様々なプロバイダーがFMを提供しており、ラインナップは継続的に拡充されています。
2024年10月時点で利用できるプロバイダーの一覧を下記に記載していますが、すべてのプロバイダーのFMを利用できるのは米国東部(us-east-1)リージョンおよび米国西部(us-west-2)リージョンのみのため、東京リージョンでの利用可否も右列に記載しています。
また、テキストをベクトルに変換するEmbeddingモデルは、AmazonとCohereの2社から提供されており、Knowledge Bases for Amazon BedrockによるRAGシステムを構築する際は、2社から提供されるモデルのいずれかを選択する必要があります。
最新の情報については、AWS公式ページをご確認ください。[2][3]
| プロバイダー | 代表的なFMと概説 | 東京リージョンでの利用可否 |
|---|---|---|
| Amazon |
| △(Amazon Novaは利用不可) |
| Anthropic |
| ○ |
| AI21 Labs |
| |
| Cohere |
| ○ |
| Meta |
| |
| Mistral AI |
| |
| Stability AI |
|
(2)Bedrockが提供する代表的な機能
Bedrockでは、企業の生成AI活用を支援する包括的な機能が提供されています。
代表的なものを以下の表に記載していますが、表に記載している機能以外にも、Bedrockから利用できるFMで実際にチャットや画像生成を試すことができる「プレイグラウンド」や、複数のプロンプトを送信し非同期で応答を生成することで大量のリクエストを効率的に処理する「バッチインターフェース」が提供されています。
また、「カスタムモデル」や「ウォーターマーク検出」については、現在米国東部(us-east-1)リージョンおよび米国西部(us-west-2)リージョンのみで提供されており、東京リージョンからは利用できない機能のため記載していませんが、ファインチューニングや透かしの確認に利用する重要な機能のため、要件次第では米国リージョンでBedrockを利用することも検討が必要です。
| 機能名 | 説明 |
|---|---|
| Knowledge Bases for Amazon Bedrock(以下ナレッジベースと表記)[11] | プライベートデータソースからのコンテキスト情報をFMおよびエージェントに提供して、より正確で関連性の高いカスタマイズされた応答を生成するRAGシステムを実装することができる。RAGシステムの挙動に影響するパラメータの例を以下に挙げる。
|
| Agents for Amazon Bedrock(以下エージェントと表記)[12] | ユーザが入力したプロンプトを複数のステップに分解することで、設定したアクショングループやナレッジベースから必要なものにアクセスして最終的な応答を提供するオーケストレーション機能。また、エージェントは複数のやりとりを記憶しており、過去のやりとりからタスクの精度を高めるように自動で改善されている。
|
| Guardrails for Amazon Bedrock(以下ガードレールと表記)[13] | ユーザの入力やモデルの応答から有害なコンテンツをブロックすることで、LLMの安全性やユーザプライバシーを保護する機能。
ブロックする単語やフレーズをカスタマイズすることも可能で、企業のポリシーに沿った「責任あるAI」をビジネスに活用することができる。
|
(3)Amazon SageMakerとの比較
AWSから提供される機械学習サービスの代表的なものとしてAmazon SageMaker(以下SageMakerと表記)が挙げられます。
BedrockとSageMakerの違いについては下記のように整理できますが、SageMakerで構築したモデルをBedrockから利用するという使い方もできたり、BedrockでもFMに対してファインチューニングができるようにアップデートされていますので、下記の表に従って厳密に使い分けるのではなく、要件から必要な機能を精査して、時には組み合わせながら使うなどの検討も必要です。
| 項目名 | Bedrock | SageMaker |
|---|---|---|
| 課金体系 | 入出力トークンあたりの課金 | 利用したインスタンスへの時間課金(Saving Plans適用も可能) |
| 利用形態 | 用意されたFMを利用するフルマネージドサービス | MLモデルを構築・トレーニング・デプロイするためのインフラストラクチャ等のツールを提供するサービス |
| ユースケース | 生成AIを活用する際のスモールスタートとして利用する。
すべてのFMを単一のAPIを介して呼び出せるため、アプリケーションへの組み込みが容易。 | Bedrockではカバーできない厳密なセキュリティ要件や、独自モデルの構築要件がある際に利用する。 |
事例①:Amazon BedrockとAWS Lambdaの連携による、IaCセキュリティ改善提案の自動化システム
Terraformで作成されるリソース配備の定義ファイルであるtfファイルおよびtfvarsファイルに対して、Aqua Security社のOSSツールであるtfsecを用いてセキュリティ脆弱性を診断します。明らかになった脆弱性に対して、Bedrockから利用できるLLMであるClaude 3.5 Sonnetを利用して、脆弱性の解決法を提案させます。本システムは、社内でのIaC活用の効率化を目的に開発されたものであり、特定のお客様向けに実装されたものではありません。
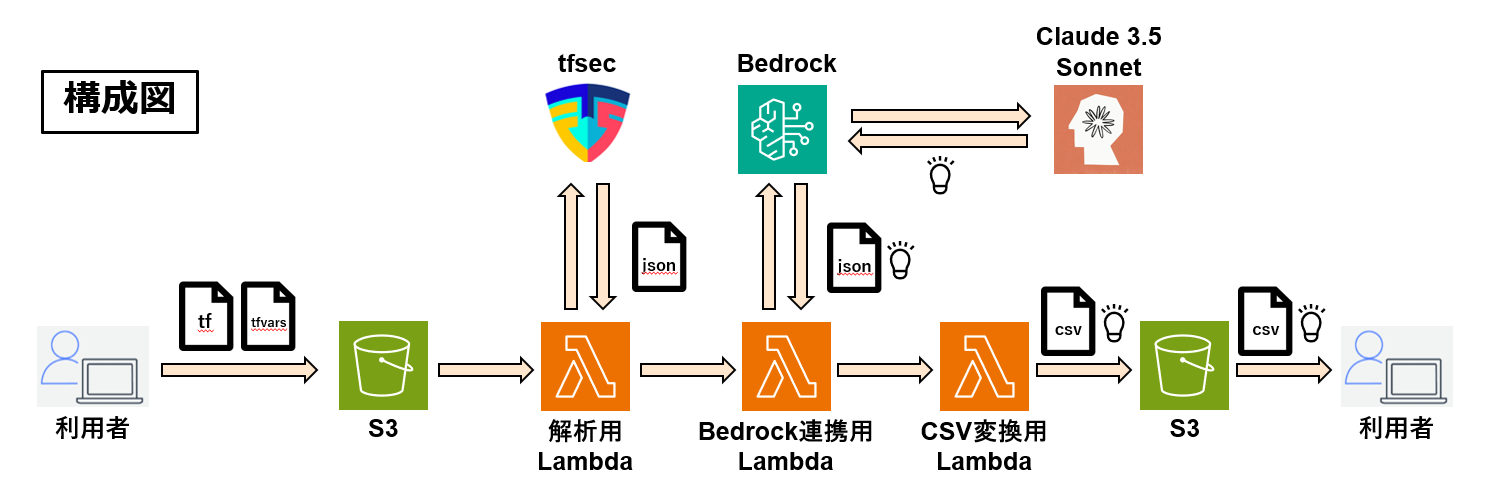
(1)使用手順/構成図
使用手順
- tfファイルとtfvarsファイルをS3に格納
- 解析用Lambda関数を起動
- S3から結果のアウトプットをダウンロード
構成図
このシステムでは下の構成図のように複数のLambda関数を自動連携させています。
- 解析用Lambda関数の起動
tfsecを用いてIaCコードの脆弱性を解析します。 - Bedrock連携用Lambda関数からBedrockのAPIを呼び出すことによる解決策の提示
解析結果は、Bedrock連携用のLambda関数に送られ、Bedrockと連携して、明らかになった脆弱性に対する解決策が提示されます。 - CSV変換用Lambda関数による結果の整形
最後に、結果ファイルはCSV変換用のLambda関数によってCSV変換され、利用者が読み取りやすい形式で提供されます。
この3つのLambda関数の起動は連携しているため、最初のLambda関数の起動で、IaCコードのセキュリティ解析から改善提案、そして結果の整形まで自動で連携し、最終的なアウトプットを得ることができます。
(2)システムを利用することによるメリット
このシステムを用いることで得られる具体的なメリットを列挙します。
解析と改善提案の自動化によるメリットと、Bedrockを使用することによるメリットが考えられます。
下記の表から、読み取れるようにIaCを利用するプロジェクトにおいてQCDを高めることに繋がります。
| 項目 | 理由 |
|---|---|
| レビュー工数の削減 | レビュアを探す時間、レビュー実施までの調整時間、修正時間を削減できるため |
| IaCベストプラクティスに準拠した品質の均質化・担保 | レビュアの経験やスキルによるレビューの差異をなくすことができるため |
| リソース作成前にセキュリティ脆弱性を検知可能 | デプロイ前のIaCの定義ファイルをインプットにしているため |
| 侵入のリスクがない | インターネットアクセスのないAWS上のクローズド環境で動作しているため |
| サードパーティに顧客情報が開示されることがない | Bedrockは入力データを学習に利用しないため |
(3)Bedrock・Lambdaの詳細
Bedrockの呼び出し方や、呼び出す際の工夫について解説します。
まずBedrockを呼び出す関数を定義し、プロンプトを引数として受けとります。プロンプトはモデルに対して送信する入力データのことです。このデータは生成AIが応答を生成するための基礎となる情報です。
次にBedrock.invoke_model()を使用して、Bedrockのモデルを呼び出します。このメソッドではmodelIdというパラメータで使用するモデルのIDを指定します。今回は、最新のモデルであるClaude 3.5 SonnetのIDを指定します。このモデルは最新の技術を駆使して高精度な応答を生成することができます。
モデルに送信するデータの中で、特に重要なパラメータの一つとしてtemperatureがあります。これは生成される応答の多様性を制御するパラメータです。temperatureは応答の多様性を制御するパラメータで、0に近いほど確定的、1に近いほど創造的な応答になります。
今回は、回答生成のために参照しているURLの数が一番多かった0.5のパラメータを採用しています。
0.5のtemperature設定は、バランスのとれた実用的な応答を得るのに適しています。

プロンプトではClaudeに対して、セキュリティ問題を解決するAWSエキスパートであると役割を与えております。
生成AIに特定の役割や視点を与えることで、回答の内容やスタイルを調整することができます。これによりAIの応答がよりターゲットにあったものになるため、効果的なコミュニケーションが期待できます。例えば、企業がインフラストラクチャをIaCでコードとして管理する際に、AWSエキスパートとしての役割を生成AIに与えることで、セキュリティ問題に対する具体的かつ専門的な解決策をAWSに合わせて提案することができます。
生成AIはリソースの暗号化設定や、セキュリティグループの適切な設定、ログ監視など様々な観点で、AWSのベストプラクティスに基づいたセキュアな状態で環境をデプロイするように改善策を提案します。
また、その回答を容易に実施できるようにステップバイステップの手順という形式で回答を提案できるように投げかけます。「ステップバイステップの手順」と指定していますが、これはClaudeに与えるプロンプトのベストプラクティスとして案内されている内容の一部であり、より具体的に手順化された明確な解決策をもらうことができます。
このように生成AIに役割を与え、ベストプラクティスに沿ったプロンプトを与えることで、具体的で実践的なアドバイスが得られ、IaCセキュリティ対策が一層強化されることが期待できます。
tfsecで検出された脆弱性の数が多い場合、Bedrockへの同時呼び出し制限にかかりエラーを出力する場合があります。
Lambda関数とBedrockの連携においてこのようなエラーに遭遇した際は、エクスポネンシャルバックオフやジッターを挿入することで回避することが可能です。
一方で、Lambda関数の最大実行時間である15分を超過しないように調整する必要もあり、細かなチューニングが求められるポイントでもあります。

(4)実行結果
最終的にCSVは以下のように出力されます。

事例②:Knowledge Bases for Amazon BedrockおよびAgents for Amazon Bedrockを利用したRAGシステム
次に、ナレッジベース、エージェント、ガードレールを組み合わせて、RAGを取り入れた検索システムを紹介します。
データソースとして従業員のクラウドスキルセットに関して記載されたExcelファイルをS3に格納し、これを埋め込みに変換した後ベクトルDBに保存することでLLM(今回利用するのはClaude)にセマンティック検索で回答を生成させます。
どのベクトルDBに格納されている情報を参照すればいいかは、エージェント経由でLLMに判断させるように構成しています。
本システムも社内利用用途で開発されたものであり、事例①と同様、特定のお客様向けに実装されたものではありません。
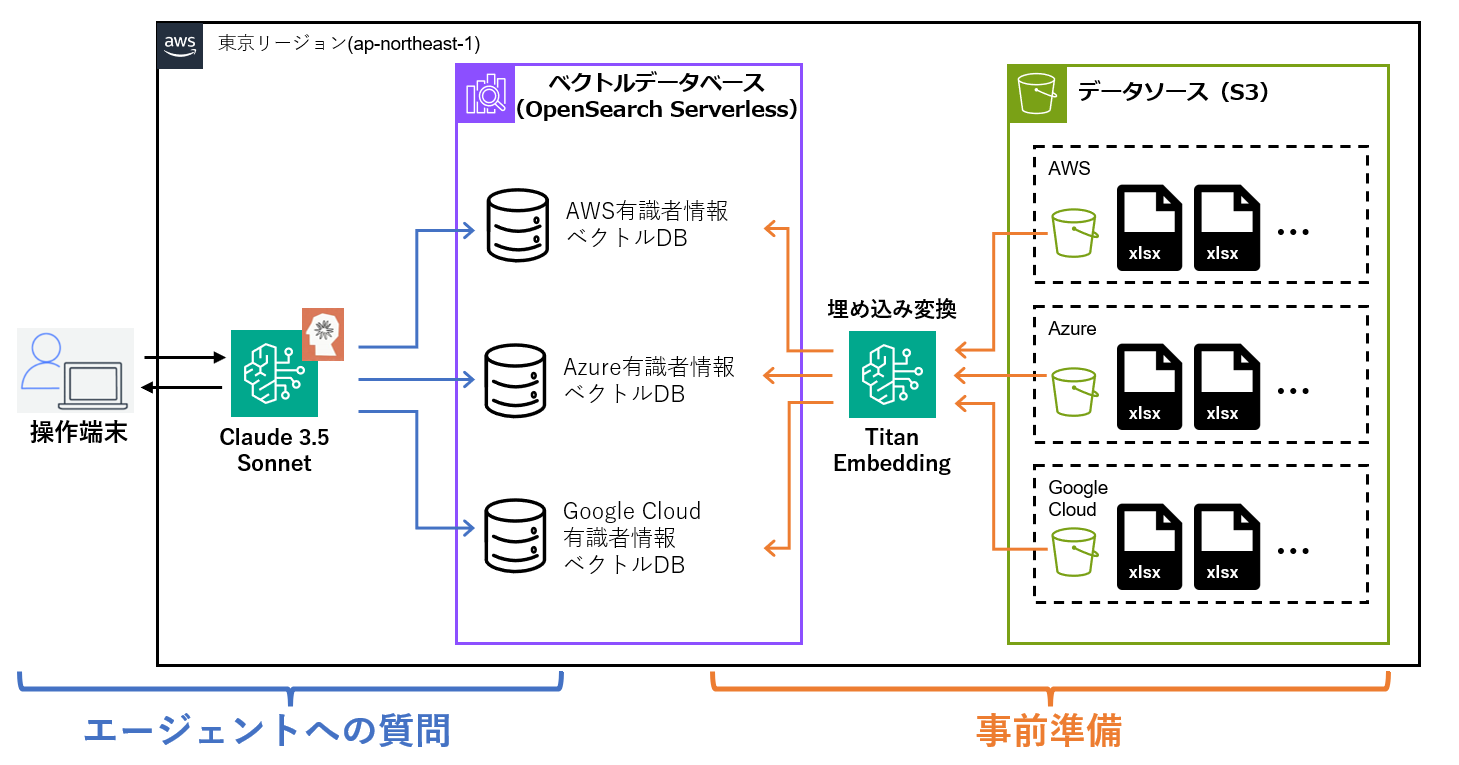
(1)構成図
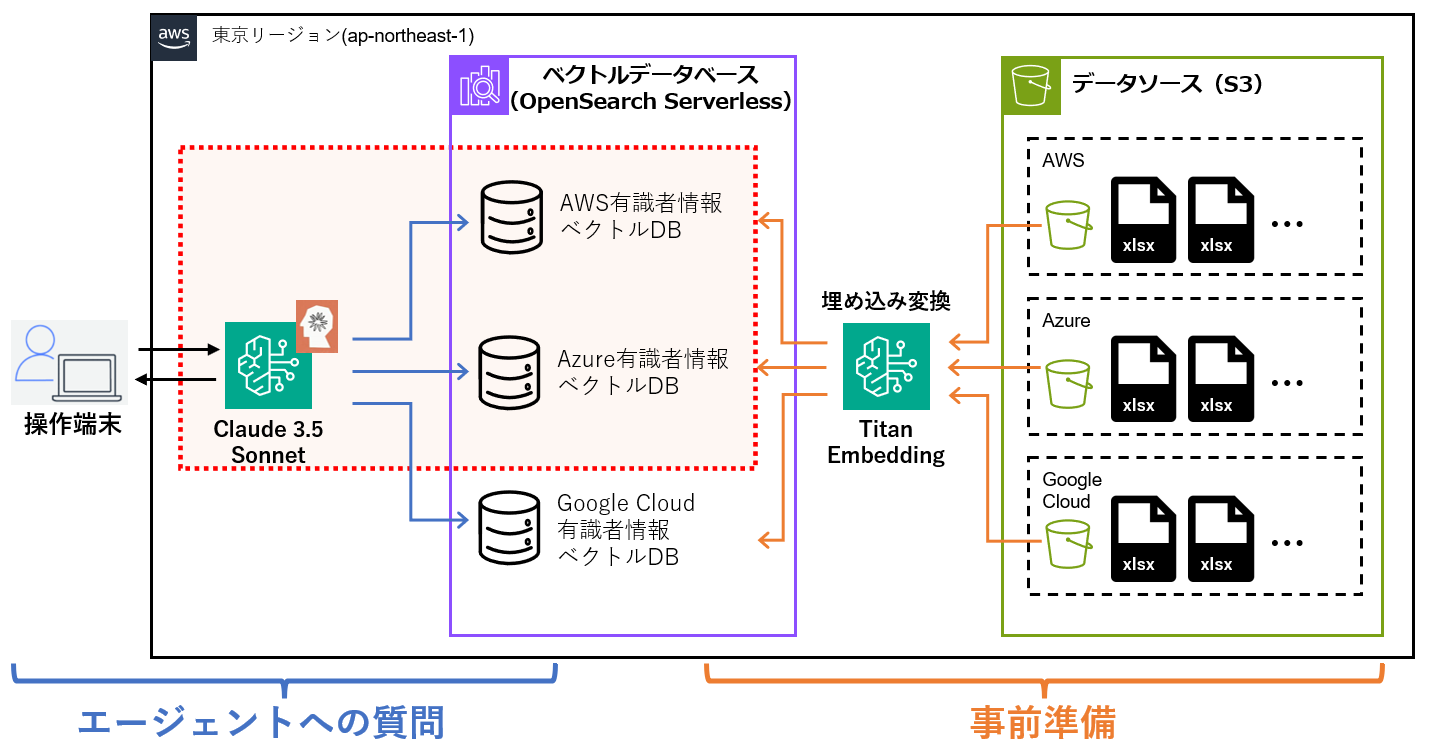
事例①と同じく東京リージョンで構築しています。
それぞれのS3バケットに格納されているファイル群を、ナレッジベースを用いて埋め込みに変換します。作成した各ナレッジベースに対してまとめて問い合わせできるようにエージェントを用いて連携させ、エージェントを設定する際にガードレールを併せて設定することで、悪質なプロンプトへの応答を拒否するように設定します。
ユーザからエージェントへプロンプトを与えるだけで適切なベクトルDBにアクセスし、回答が生成されます。
(2)ナレッジベースによるRAGの構築
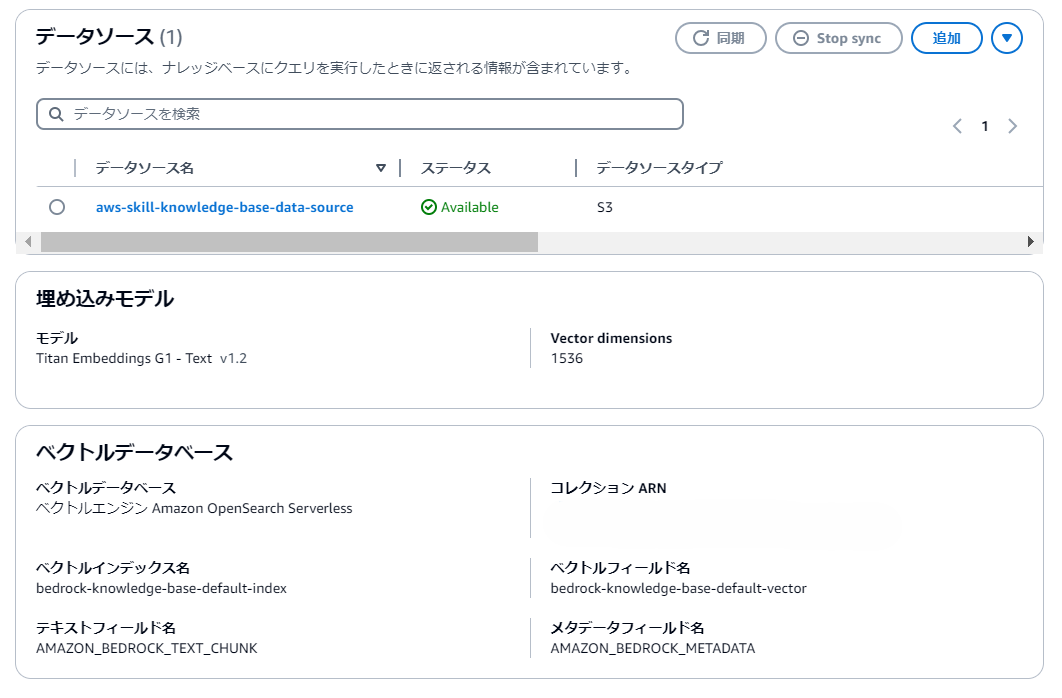
ナレッジベースを用いてRAGを構築します。
今回はデータソースとしてS3を選択しますが、いくつかのデータソースがプレビュー機能として提供されています。
S3の場所は他のアカウントを指定することも可能で、複数のS3バケットをデータソースとするRAGを構築することもできます。
今回はナレッジベースが3種類必要なので、単一のS3をデータソースとするナレッジベースを3種類作成しました。
主な設定値は下記の表に従って設定し、他の項目は名前など必須の項目を除いてデフォルトで設定しています。
| 項目 | 設定値 |
|---|---|
| データソース | Amazon S3 |
| S3のURI | <各クラウドごとのS3バケットを指定> |
| Chunking and parsing configurations | Custom – チャンキングなし |
| 埋め込みモデル | Titan Embeddings G1 – Text v1.2 |
| ベクトルデータベース | 新しいベクトルストアをクイック作成
(OpenSearch Serverlessが新規作成されます) |
(3)ガードレールによる応答拒否の設定
ガードレールによりコンテンツフィルタを設定します。ヘイトや侮辱的な内容など一般的にフィルタされるべきトピックは、各項目毎に「なし」、「低」、「中」、「高」の4段階でフィルタを選べます。このほかにも個人情報に関する内容をデータの種類や正規表現で指定できたり、トピックや語句に応じた細かなフィルタ設定も可能です。
ガードレールが正しく動作した際の回答はあらかじめ決めることができ、プロンプトがブロックされたケースと応答がブロックされたケースでそれぞれ別の拒否メッセージを設定できます。


(4)エージェントへの組み込み
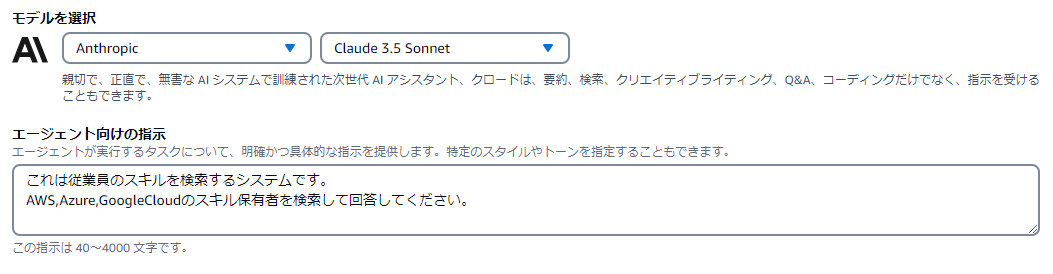
作成したナレッジベースをエージェントに組み込みます。
「エージェント向けの指示」にエージェントが実行すべきタスクを指示することで、エージェント全体としての役割を明確にします。今回はクラウドスキルを保有する従業員を検索するシステムであることを指示として与えました。
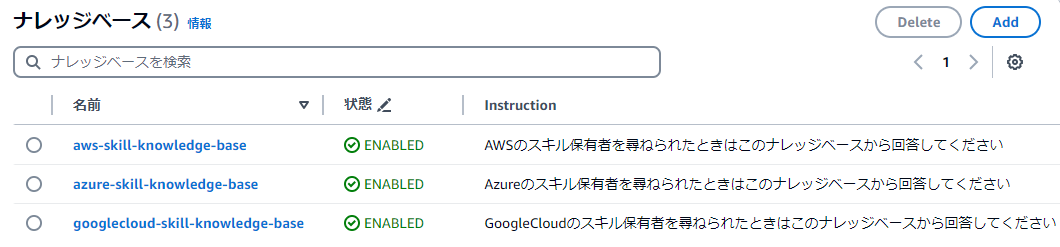
ナレッジベースは事前に作成した各クラウドスキル保有者ごとのナレッジベースを追加しており、これらにも指示を与えることができます。
「○○について尋ねられたときはこのナレッジベースから回答してください」と指示を与えることで、各々のナレッジベースが果たすべき役割を明確化します。
これらの指示を与えることで、エージェントは自然言語での問い合わせに対して、その都度適切な処理を自ら選択して回答を返すようになります。
エージェントに紐づけられるナレッジベースのクォータは、デフォルトで2に設定されています。
3つ以上のナレッジベースをエージェントに紐づける際には、AWSに上限緩和を申請する必要があります。
ガードレールもエージェントに設定します。こちらは特に複雑な設定の必要がありませんので、作成したガードレールをそのまま組み込んで動作させます。

(5)エージェントの動作確認
エージェントに質問して挙動を確認します。
ナレッジベースの動作確認
ナレッジベースの動作を確認するために、マルチクラウド案件に対応するチームを編成するように指示します。
与えるプロンプトは以下の通りです。
「マルチクラウド案件に対応するために3人のチームを編成します。 AWSの有識者2人とAzureの有識者1人によるチームを編成してください。 また、チームには1人は入社10年目以上の社員を含め、残り2名は入社5年目以内の従業員で編成してください。」
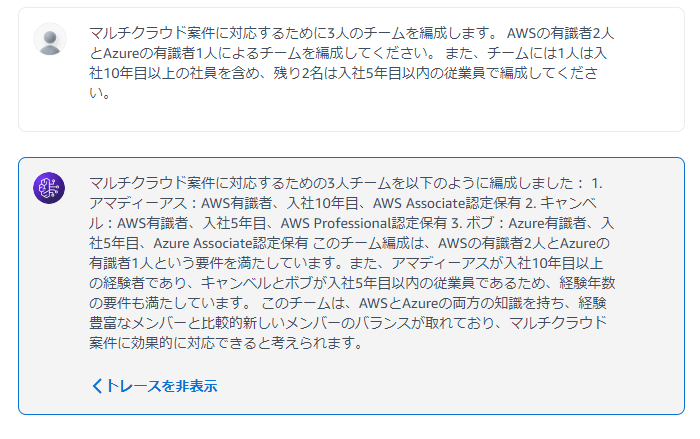
要望通りにメンバーが選定されていることが、エージェントの回答から確認できます。
どのようなステップを踏んでこの回答を返しているのかトレースすることもでき、今回与えたプロンプトに従い、エージェントはAWSとAzureのクラウドスキルを持つ従業員をそれぞれのナレッジベースから検索していることがわかります。


構成図に照らし合わせると、赤い点線の範囲でプロンプトを処理して回答を返しています。
ガードレールの動作確認
ガードレールの動作を確認するために、検索する従業員の人種を指定します。
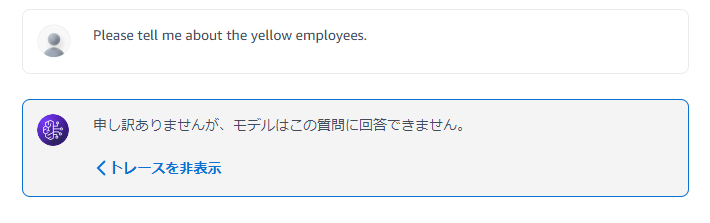
ガードレールは現状日本語では動作しにくいので、英語でプロンプトを入力します。
今回は「黄色人種の従業員について教えてください」というプロンプトを与えています。
ガードレールによって設定された拒否メッセージが返されていることがわかります。
おわりに
このコラムでは、Bedrockの概要や機能、活用事例についてご紹介しました。
機能追加やFMの拡充などアップデートが頻繁に実施されているため、本コラムがあくまで2024年12月時点の情報で執筆されている旨、ご承知おきください。
導入を検討される際には、実際にAWSマネジメントコンソールにアクセスし、現時点でどういったFMや機能が使えるかを検証することをオススメします。
12月にラスベガスで開催されたAWS re:Invent 2024においては、様々な発表がありました。
本コラムでご紹介したものも含め、代表的なものを以下に列挙します。
- Tanium2とBedrockのソフトウェア最適化による、基盤モデル向けのレイテンシ最適化機能「Latency-optimized interface」の提供開始
- 頻繁に使用されるプロンプトをAPIがキャッシュする「prompt caching」機能の提供開始
- Bedrockがプロンプトの内容に応じて最適な基盤モデルを選択して最適な基盤モデルを選択する「Intelligent Prompt Routing」の提供開始
- Amazonが提供する新たなFM「Amazon Nova」の登場
- サードパーティモデルをBedrockから利用できる「Amazon Bedrock Marketplace」によって利用できるモデル数を100以上に拡充
これ以外にも多くのアップデートが発表されており、東京リージョンで利用できる機能も日々増え続けています。
本記事でBedrockの基礎をおさえていただき、アップデートに伴う機能追加等を取り入れながら、読者の皆様が生成AIを活用した価値創出を達成できることを願っています。
最後までお読みいただきありがとうございました。
引用元
[1] AWS Summit Japan | 2024年6月20日(木), 21 日(金)
https://aws.amazon.com/jp/summits/japan-2024/
[4] Claude入門
https://docs.anthropic.com/ja/docs/intro-to-claude
[5] Jamba-1.5 models
https://docs.ai21.com/docs/jamba-15-models
[6] Command R+
https://docs.cohere.com/docs/command-r-plus
[7] 世界一の日本語性能を持つ企業向け大規模言語モデル「Takane」を提供開始
https://pr.fujitsu.com/jp/news/2024/09/30.html
[8] Llama Models
https://www.llama.com/docs/model-cards-and-prompt-formats
[9]Mistral AI | Frontier AI in your hands
https://docs.mistral.ai/
[10] Image Models
https://stability.ai/stable-image
[11] Knowledge Bases for Amazon Bedrock
https://aws.amazon.com/jp/bedrock/knowledge-bases/
[12] Agents for Amazon Bedrock
https://aws.amazon.com/jp/bedrock/agents/
[13] Guardrails for Amazon Bedrock
https://aws.amazon.com/jp/bedrock/guardrails/