
Amazon Auroraでアプリごとにリードレプリカを分けつつオートスケールも設定したい
2024年3月22日 富士通株式会社 ジャパングローバルゲートウェイ 堀口 洋
はじめに
皆さんこんにちは。
本日は、Amazon Aurora PostgreSQL(以下Amazon Auroraとします)で、
- オンラインアプリ/バッチアプリで利用するリードレプリカを分けつつ、
さらにリードレプリカのオートスケールも設定したい
というテーマでブログを記載したいと思います。
(ある案件で対応させていただいた内容を元に記載しております)
具体的には以下の状況で、以下の個別要件①②の両方、あるいは個別要件①~③のすべてを満たす構成を考えてみたいと思います。
▼状況
| 状況 | 概要 |
|---|---|
| 構成 |
|
| バッチアプリの
稼働状況 |
|
| オンラインアプリの
稼働状況 |
|
▼要件 ※個別要件①②の両方、あるいは個別要件①~③のすべてを満たすこと
| 要件 | 内容 |
|---|---|
| 個別要件① | リードレプリカへ負荷をかけるアクセスの状況から、オンラインアプリとバッチアプリで、
お互いに性能上で影響を及ぼさないように、それぞれリードレプリカを使い分けるようにしたい。 パッチアプリのリードレプリカは、バッチアプリの処理で必要な時にだけ使うようにしたい。 (必要な時に作成し、処理が終われば削除できるようにしたい) |
| 個別要件② | コスト最適化の観点から、オンラインアプリのリードレプリカはオートスケールの設定をして、
オンラインアプリのアクセス状況に応じて、スケールアウト/スケールインできるようにしたい。 |
| 個別要件③ | リードレプリカへのアクセスの負荷分散の観点から、
オンラインアプリのリードレプリカへのアクセスに偏りがでないよう、 オンラインアプリからリードレプリカへの接続を平準化したい。 |
個別要件①リードレプリカの使い分け
~カスタムエンドポイント活用 or データベースのクローン作成~
最初に、個別要件①のリードレプリカの使い分けを考えていきたいと思います。
| 要件 | 内容 |
|---|---|
| 個別要件① | リードレプリカへ負荷をかけるアクセスの状況から、オンラインアプリとバッチアプリで、
お互いに性能上で影響を及ぼさないように、それぞれリードレプリカを使い分けるようにしたい。 パッチアプリのリードレプリカは、バッチアプリの処理で必要な時にだけ使うようにしたい。 (必要な時に作成し、処理が終われば削除できるようにしたい) |
この個別要件を実現する方式として、以下の2つの方式を記載します。
▼要件 ※個別要件①②の両方、あるいは個別要件①~③のすべてを満たすこと
- カスタムエンドポイントを活用する方式 ➡(2)で記載
- データベースのクローンを作成する方式 ➡(3)で記載
(1)Amazon Auroraのエンドポイントについて
方式の話に入る前に、Amazon Auroraのエンドポイントについて振り返っておきます。
Amazon Auroraでは、アプリからの接続用に、以下の4種類のエンドポイント(FQDN)を利用できます。
| エンドポイント | 用途 | FQDNサンプル |
|---|---|---|
| クラスター
エンドポイント | データベースクラスターのプライマリーインスタンスを指すエンドポイント。
書き込み用で使用する。 | mydbcluster.cluster-************.
ap-northeast-1.rds.amazonaws.com:5432 |
| リーダー
エンドポイント | リードレプリカ(単体ないし複数)を指すエンドポイント。
| mydbcluster.cluster-ro-************.
ap-northeast-1.rds.amazonaws.com:5432 |
| インスタンス
エンドポイント | Amazon Auroraのプライマリーインスタンスやリードレプリカのインスタンスなど、
それぞれのインスタンス自体を指すエンドポイント。 | mydbinstance.************.
ap-northeast-1.rds.amazonaws.com:5432 |
| カスタム
エンドポイント | Amazon Auroraの利用者が独自に作成できるエンドポイント。
任意のインスタンスを含むことができる。 プライマリーインスタンスとリードレプリカ1つのカスタムエンドポイントも構成可。 | myendpoint.cluster-custom-************.
ap-northeast-1.rds.amazonaws.com:5432 |
(2)Amazon Auroraのカスタムエンドポイントを使った方式
それでは、カスタムエンドポイントを活用する方式について記載していきます。
以下の図1~図3について記載します。
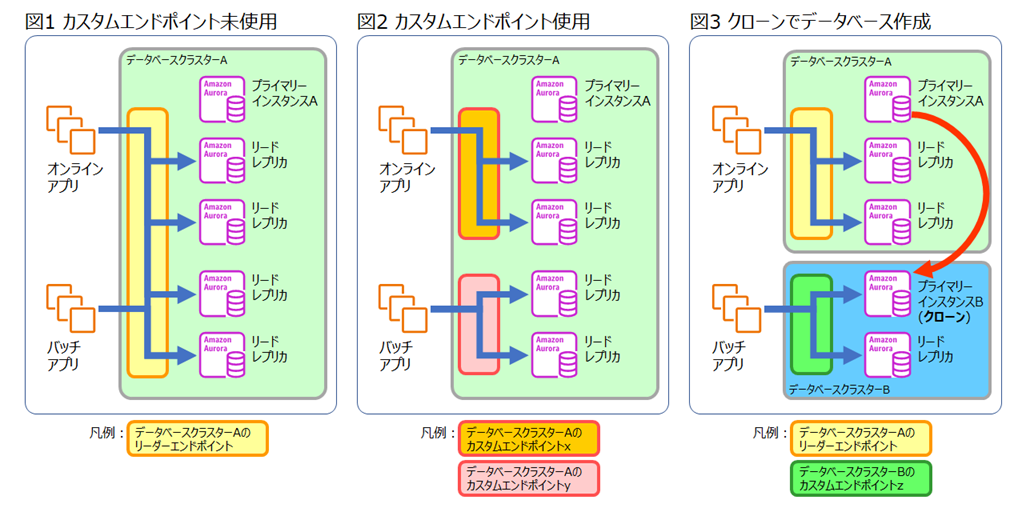
図1は、データベースクラスターAの中で、リードレプリカが複数作成されています。
リーダーエンドポイントがあり、リーダーエンドポイントにはすべてのリードレプリカが含まれています。
アプリがリーダーエンドポイントへ接続すると、複数のリードレプリカのいずれかに負荷分散(※)して接続する構成です。
- (※)DNSのラウンドロビンで負荷分散します。
図1の構成では、オンラインアプリ用のリードレプリカと、バッチアプリ用のリードレプリカが分かれていません。
そのため、バッチアプリでいずれかのリードレプリカに負荷がかかると、オンラインアプリの読み込み性能に影響が出る可能性があります。
図1に対して図2の構成では、オンラインアプリ用のリードレプリカを「カスタムエンドポイントx」、
バッチアプリ用のリードレプリカを「カスタムエンドポイントy」として、
カスタムエンドポイントでオンラインアプリ用とバッチアプリ用のリードレプリカを分ける構成になっています。
この構成だと、バッチアプリの読み込み負荷が、オンラインアプリの読み込み性能に影響を与えることはありません。
(3)Amazon Auroraのクローンを使った方式
次に、データベースのクローンを作成する方式について記載していきます。
図を再掲します。
図3の構成は、データベースクラスターAのプライマリーインスタンスAを元にデータベースクラスターBを作成した構成です。
データベースクラスターBは、Amazon Auroraのクローン機能を使って高速に作成します。
クラスターの作成後に、リードレプリカを1つ加えています。
プライマリーインスタンスBとリードレプリカ1つで合わせて2つのインスタンスで、「カスタムエンドポイントz」も構成しています。
オンラインアプリは、プライマリーインスタンスAが属するデータベースクラスターのリーダーエンドポイントに接続します。
リーダーエンドポイントによって、オンラインアプリの接続が後段のリードレプリカに負荷分散されます。
バッチアプリは、カスタムエンドポイントzによって、プライマリーインスタンスBあるいはリードレプリカに接続します。
カスタムエンドポイントzによって、後段のプライマリーインスタンスBまたはリードレプリカへの接続が負荷分散されます。
(4)個別要件①だけの場合の考察
求められる要件が個別要件①だけの場合ですと、図2のカスタムエンドポイントを活用する方式も、図3のクローンを作成する方式も採用できます。
なお、実装の際には、以下の(5)の留意事項も合わせてご参照の上、それぞれの環境で動作検証を行ってください。
(5)カスタムエンドポイントを利用する際のリードレプリカの追加と削除に関する留意事項
カスタムエンドポイントを利用する際のリードレプリカの作成/削除について、カスタムエンドポイントとリードレプリカの仕様を留意事項として振り返ります。
▼カスタムエンドポイントとリードレプリカの仕様上の留意事項
- カスタムエンドポイントのエンドポイントタイプ
- カスタムエンドポイントのメンバーシップルール
- フェイルオーバーの際のリードレプリカの優先度
リードレプリカの追加/削除は、これらの留意事項を加味して手順を検討する必要があります。
①カスタムエンドポイントとリードレプリカの仕様上の留意事項
①-a カスタムエンドポイントのエンドポイントタイプ
カスタムエンドポイントには、以下のエンドポイントタイプがあります。
| エンドポイントタイプ | 仕様 | 備考 |
|---|---|---|
| READER | リードレプリカのみ含めることができる | READER/WRITERタイプは、AWS CLIかAPIで作成/変更可能 |
| WRITER | プライマリーインスタンスのみ含めることができる | |
| ANY | プライマリーインスタンスもリードレプリカも含めることができる | マネジメントコンソールでは、ANYのみ作成可能 |
①-b カスタムエンドポイントのメンバーシップルール
カスタムエンドポイントにプライマリーインスタンスないしリードレプリカを追加/削除する際に、以下のメンバーシップルールがあります。
| メンバーシップ | 仕様 |
|---|---|
| 静的リスト | カスタムエンドポイントに登録するプライマリーインスタンス/リードレプリカを選択して、静的なリストにする |
| 除外リスト | カスタムエンドポイントに登録しないプライマリーインスタンス/リードレプリカを選択して、動的なリストにする |
リードレプリカが増えた時にカスタムエンドポイントに追加されるようにする等、
以下のケースでプライマリーインスタンス/リードレプリカの状態の変化に追従する場合は、除外リストを用います。
▼除外リストを利用して状態の変化に追随できるようにすることを検討するケース
- オートスケールでリードレプリカが増減するケース
カスタムエンドポイントに含まれるリードレプリカを増減させたい - フェイルオーバーでリードレプリカがプライマリーインスタンスに変わるケース
プライマリーインスタンスになった旧リードレプリカのインスタンスを除外したい - フェイルオーバーでリードレプリカが新規に作成されるケース
新しく追加されたリードレプリカをカスタムエンドポイントに含めたい
除外リストを利用する場合は、AWSのマネジメントコンソールでは、当該カスタムエンドポイントの設定で、以下のチェックボックスをチェックします。
[Attach future instances added to this cluster]
(今後追加されるインスタンスをこのクラスターにアタッチする)
①-c フェイルオーバーの際のリードレプリカの優先度
プライマリーインスタンスに障害が発生した場合に、どのリードレプリカをプライマリーインスタンスにするか、優先順位を設定することができます。
②図2のケースで手順に盛り込む内容の検討
カスタムエンドポイントのエンドポイントタイプとメンバーシップルールを考慮して、リードレプリカの追加と削除の手順に盛り込む内容を検討します。
②-a カスタムエンドポイントのエンドポイントタイプ
エンドポイントタイプがANYで、メンバーシップルールが除外リストだと、プライマリーインスタンスも含まれることになります(※)。
アプリからの読み込みをリードレプリカに寄せたい場合は、カスタムエンドポイントはREADERタイプに設定します。
カスタムエンドポイントのエンドポイントタイプの設定は、AWS CLIないしAPIで可能です。
マネジメントコンソールでは、エンドポイントタイプの設定はできません。
- (※)「エンドポイントタイプがANYで、メンバーシップルールが除外リストだと、プライマリーインスタンスも含まれる」について
アプリからの読み込みをリードレプリカに寄せたい場合は、カスタムエンドポイントはREADERタイプに設定します。
カスタムエンドポイントのエンドポイントタイプの設定は、AWS CLIないしAPIで可能です。
マネジメントコンソールでは、エンドポイントタイプの設定はできません。
②-b オンラインアプリ用のカスタムエンドポイントからバッチアプリ用のリードレプリカを削除
図2の構成では、バッチアプリ用のリードレプリカは、バッチアプリ実行に合わせてリードレプリカを作成し、
バッチアプリ終了時に削除することで、リードレプリカにかかるコストを最適化したい構成になっています。
図2のオンラインアプリ用のカスタムエンドポイントでは、オートスケールに追随して、リードレプリカの増減が必要です。
しかしながら、単にリードレプリカの増減に追随できる設定だった場合に、バッチアプリ用のリードレプリカを追加すると、
その追加したリードレプリカがオンラインアプリ用のカスタムエンドポイントにも含まれてしまうことになります。
そこで、バッチアプリ用のリードレプリカを追加した際には、オンラインアプリ用のカスタムエンドポイントから、
新しく作成したバッチアプリ用のリードレプリカを除外することを考慮します。
②-c フェイルオーバーの際のリードレプリカの優先度
バッチアプリ用のリードレプリカは、バッチアプリ実行に適したインスタンスを選定することになります。
そのため、フェイルオーバーが発生した際にバッチアプリ用のリードレプリカがプライマリーインスタンスになることがないよう、
バッチアプリ用のリードレプリカの優先度を下げておきます。
②-d 図2のケースのまとめ
まとめです。
| カスタムエンドポイント | 図2上の表記 | エンドポイントタイプ | メンバーシップルール | フェイルオーバーの優先度 |
|---|---|---|---|---|
| オンラインアプリ用 | カスタムエンドポイントx | READER | 除外リスト | 優先度「高」のリードレプリカを含める |
| バッチアプリ用 | カスタムエンドポイントy | READER | 静的リスト | 優先度「低」のリードレプリカを含める |
③クローンの追加と削除
図3のケースで、クローンを追加/削除する際に留意する項目について記載します。
バッチアプリ用のプライマリーインスタンスBとリードレプリカ、カスタムエンドポイントzは、バッチアプリ実行に合わせて作成し、終了時に削除するようにします。
図3の構成では、データベースのクラスターをオンラインアプリ用とバッチアプリ用で分けています。
オンラインアプリ用では、リードレプリカはデフォルトのリーダーエンドポイントを通して接続します。
そのため、カスタムエンドポイントに関する考慮は不要です。
バッチアプリ用のデータベースクラスターでは、図3では一例として、プライマリーインスタンスとリードレプリカでカスタムエンドポイントを構成しています。
バッチアプリ用のデータベースクラスターは、クローンでバッチアプリ用実行時に都度作成する環境です。
そのため、フェイルオーバーは考慮しない構成として、エンドポイントタイプをANY、メンバーシップルールを静的リストで設定します。
| カスタムエンドポイント | 図2上の表記 | エンドポイントタイプ | メンバーシップルール | フェイルオーバーの優先度 |
|---|---|---|---|---|
| バッチアプリ用 | カスタムエンドポイントz | ANY | 静的リスト | すべてのインスタンスの優先度を揃える |
個別要件②適切な読み込み性能の維持を目的としたリードレプリカのオートスケール
次に、個別要件②のオートスケールを考えていきたいと思います。
| 要件 | 内容 |
|---|---|
| 個別要件② | コスト最適化の観点から、オンラインアプリのリードレプリカはオートスケールの設定をして、
オンラインアプリのアクセス状況に応じて、スケールアウト/スケールインできるようにしたい。 |
(1)Amazon Auroraのオートスケールの種類
Amazon Auroraでは、以下のオートスケールが提供されています。
| オートスケールの種類 | 実現方式 | 用途 |
|---|---|---|
| スケールアウト/スケールイン | Amazon Aurora Serverless v2 | 適切な読み込み性能を確保するため、スケールアウト/スケールインで、
リードレプリカを増減する。 |
| スケールアップ/スケールダウン | Amazon Aurora Auto Scaling | 適切な書き込み性能 / 読み込み性能を確保するため、
ライターまたはリーダーをスケールアップ/スケールダウンする。 |
今回は、オンラインアプリではアクセス状況に応じて読み込み性能を適切に維持することを目的としているため、
Amazon Aurora Auto Scalingでリードレプリカを増減させる方式を採用します。
- ※なお、執筆時点では、Amazon Aurora Serverless v2 は Amazon Aurora Auto Scaling に対応していません。
(2)Amazon Aurora Auto Scalingで設定可能なオートスケール
Amazon Auroraのリードレプリカのオートスケールでは、以下のポリシーが設定できます。
▼ Amazon Aurora Auto Scalingで設定可能なオートスケールのポリシー
- ターゲット追跡スケーリングポリシー
- ステップスケーリングポリシー
- スケジュールされたスケーリング
このうち、マネジメントコンソールで設定できるポリシーは、ターゲット追跡スケーリングポリシーのみです。
また、マネジメントコンソールで設定できるメトリクスも、以下に記載したメトリクスの2種類のみとなります。
それ以外のポリシーやメトリクスの設定をしたい場合は、AWS CLI、ないしAPIで設定します。
▼ ターゲット追跡スケーリングポリシーをマネジメントコンソールで設定する場合に選択できるメトリクス
- RDSReaderAverageCPUUtilization
平均 CPU 使用率に基づいてポリシーを作成するための Aurora レプリカの平均 CPU 使用率 - RDSReaderAverageDatabaseConnections
Aurora レプリカへの平均接続数に基づいてポリシーを作成するための Aurora レプリカの平均接続数
図を再掲します。
図2は、1つのデータベースクラスターの中で2つのカスタムエンドポイントを利用する構成です。
上記の平均CPU使用率や平均接続数はすべてのリードレプリカの平均になります。
一部のリードレプリカのみを含むカスタムエンドポイントの構成では、上記の平均CPU使用率や平均接続数は不適切です。
オンラインアプリ用のカスタムエンドポイントxを構成するリードレプリカ群の利用状況だけでオートスケールさせたい場合、
カスタムエンドポイントxを構成するリードレプリカ群から何らかのカスタムメトリクス(※)を作成し、
そのカスタムメトリクスを用いてオンラインアプリ用のリードレプリカをオートスケールさせるようにします。
- ※カスタムエンドポイントxに含めるリードレプリカ群だけの平均CPU使用率、などを作成します。
図3の場合は、オンラインアプリ用のリードレプリカ群はバッチアプリ用のリードレプリカ群と分かれています。
オンラインアプリ用のリードレプリカのみが、データベースクラスターAに存在している構成です。
そのため図3の構成では、リードレプリカ群全体の平均CPU使用率や平均接続数のメトリクスも、
オンラインアプリ用のリードレプリカをスケールさせるトリガーとして適切であれば利用可能です。
(3)個別要件①②の両方を満たす場合の考察
求められる要件が個別要件①②の両方の場合でも、図2のカスタムエンドポイントを活用する方式も、図3のクローンを作成する方式も採用できます。
(4)留意事項
Amazon Aurora Auto Scalingでオートスケールを利用する場合の留意事項を振り返ります。
▼Amazon Aurora Auto Scalingでのオートスケールの留意事項
- インスタンスの仕様を揃える
オートスケールを利用する場合は、インスタンスのスペックを揃えるよう留意してください。 - オートスケールとスパイク
一般に、オートスケールは急激なアクセス増(スパイク)への追従は困難です。
スパイクが想定される場合は、CPU利用率や接続数をトリガーとするオートスケールだけではなく、
時間帯によって増やす/減らす等のスケーリングも検討してください。 - カスタムエンドポイントでリードレプリカの増減に追従
リードレプリカの増減をカスタムエンドポイントに反映する場合は、
前章で記載の通り、メンバーシップルールを除外リストでカスタムエンドポイントを設定します。 - リードレプリカの増減と、アプリからカスタムエンドポイントへの接続
リードレプリカの増減によって、カスタムエンドポイントから接続できるリードレプリカに変更がある場合でも、
アプリはカスタムエンドポイントからリードレプリカに接続できます。
カスタムエンドポイントの変更中にカスタムエンドポイントに接続できなくなる、というようなことはありません。
個別要件③リードレプリカへの接続の平準化
最後に、個別要件③のアクセスの平準化を考えていきたいと思います。
| 要件 | 内容 |
|---|---|
| 個別要件③ | リードレプリカへのアクセスの負荷分散の観点から、
オンラインアプリのリードレプリカへのアクセスに偏りがでないよう、 オンラインアプリからリードレプリカへの接続を平準化したい。 |
(1)RDS Proxyを活用したリードレプリカへのアクセスの平準化
前述しました通り、Amazon Aurora のリーダーエンドポイントは DNS ベースのラウンドロビンにより、
複数のリードレプリカに対して接続を振り分ける仕組みです。
しかしながら、瞬間的に複数の新規接続が確立された場合には、同一のリードレプリカに接続されてしまうことがあります。
そのため、短期間に大量の接続を行う場合、以下の図4のように特定のリードレプリカに接続が偏る可能性があります。
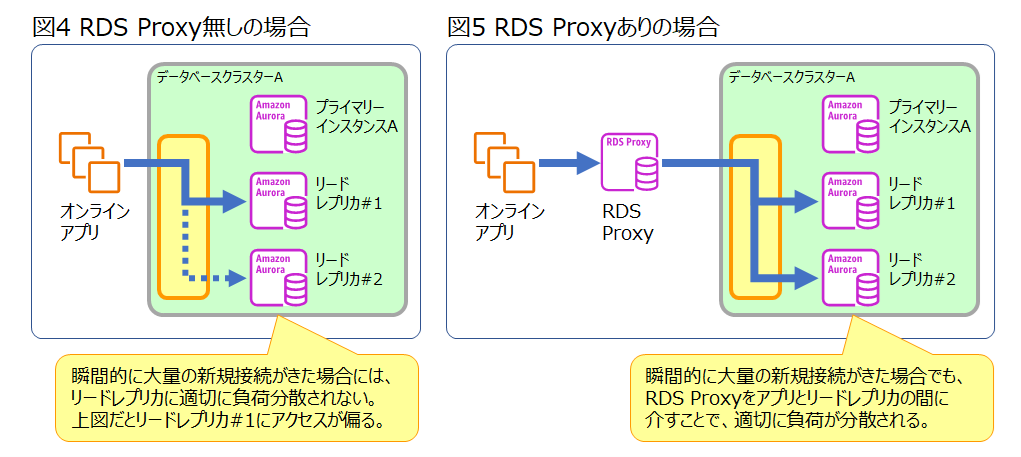
ここで、RDS Proxyの活用を検討します。
RDS Proxyにも、Amazon Auroraのエンドポイントと同じように、
読み取り/書き込みエンドポイントと読み取り専用エンドポイント(リーダーエンドポイント)があります。
このRDS Proxyのリーダーエンドポイントを使うことで、瞬間的に複数の新規接続が確立された場合でも、
図5のように複数のリードレプリカへアプリの接続を分散することが可能です。
(2)RDS Proxyの制約
RDS Proxyは、Amazon Auroraのカスタムエンドポイントへ接続することはできません。
(3)個別要件①~③のすべてを満たす場合の考察
求められる要件が個別要件①~③のすべての場合は、RDS ProxyがAmazon Auroraのカスタムエンドポイントに接続できない制約により、
クローンを作成する方式だけが採用できます。
まとめ
全体のまとめです。
オンラインアプリ/バッチアプリで利用するリードレプリカを分けつつ、
さらにリードレプリカのオートスケールも設定したい、といった場合に取りうる方式としては以下があります。
| 要件の組合せ | 要件の組合せを実現する方式の組合せ案 | 備考 |
|---|---|---|
| 個別要件①
+個別要件② | 【実現方式の組合せ案①】
| バッチアプリ実行時にリードレプリカを作成し、終了時に削除する。
※主な検討ポイント
|
| 個別要件①
+個別要件② | 【実現方式の組合せ案②】
| バッチアプリ実行時にリードレプリカを作成し、
終了時にクローンを削除する。 ※主な検討ポイント
|
| 個別要件①
+個別要件② +個別要件③ | 【実現方式の組合せ案③】
| リードレプリカへのアクセスの平準化まで求められる場合は、
【実現方式の組合せ案②】+RDS Proxyの本構成案(組合せ案③)となる。 執筆時点では、RDS Proxyがカスタムエンドポイントに対応していない。 そのため、【実現方式の組合せ①】+RDS Proxyの構成は実現できない。 |
マトリクスにすると、以下のようになります。
| 要件の組合せ | 実現方式の
組合せ案 | カスタム
エンドポイント活用 | データベースの
クローン作成 | リードレプリカの
オートスケール設定 | RDS Proxyの
利用 |
|---|---|---|---|---|---|
| 個別要件①+個別要件② | 組合せ案① | 活用する | ー | 設定する | ー |
| 個別要件①+個別要件② | 組合せ案② | ー | 作成する | 設定する | ー |
| 個別要件①+個別要件②+個別要件③ | 組合せ案③ | ー | 作成する | 設定する | 利用する |
おわりに
このコラムでは、カスタムエンドポイント、データベースのクローン、オートスケールの組合せについて、仕様の観点から考えてきました。
Amazon Auroraには他にも多くの機能がありますが、要件に応じてそれぞれの機能とその組合せを考慮していくことが肝要です。
また、この考え方は、Amazon Auroraに限らずその他のマネージドサービスでも同様となります。
最後に、実装にあたっては、机上での検討/考察に加え、実際に検証をすることも合わせてお願いしたいと思います。
こちらのコラムが、どなたかの参考になれば幸いです。