
医療AIの国際会議CLEF eHealth 2020のコンペティションで1位を獲得
2021年1月18日
English世界各地の医療機関では日々膨大な数のカルテ等の医療文書が取り扱われており、これら文書に対して診断や治療の分類コードを付与することが求められる中、その作業が医療機関の大きな負担となっています。医療AIの国際会議CLEF eHealthは医療テキストを対象としたAI技術の向上を目指してコンペティションを開催しています。今年はスペイン語医療テキストに対する国際保健機関(WHO)国際分類コードの自動付与がタスクとして取り上げられました。我々は、本コンペティションに参加して自然言語処理をベースとする独自のAI技術を開発し、世界11か国から22団体の大学・企業・研究機関が参加するなかコード自動付与精度で最高値を達成しました。これによって9月の大会で招待講演を行い、11月に学会から表彰を受けました。
 1位を受賞した Nuria Garcia研究員、Kendrick Cetina研究員
1位を受賞した Nuria Garcia研究員、Kendrick Cetina研究員
コンペティションの概要
- 主催学会
- Conference and Labs of the Evaluation Forum, eHealth(CLEF eHealth)
- 大会日程
- 2020年9月22日~25日
- 表彰日程
- 2020年11月
- 開催場所
- オンライン(当初予定のギリシャ テッサロニキから変更)
- 招待講演
- Text Mining and Semantic Knowledge for Automated Clinical Encoding (講演動画
 )
)
- 著者
- Fujitsu Laboratories of Europe(FLE ; 欧州富士通研究所)人工知能研究所
Nuria García-Santa, Kendrick Cetina
世界各地の医療機関では、日々の診療について医師がテキストで記録を残しており、多くの国や地域では、診療記録を保存する際に診断や治療に関する国際分類コードを付与することが求められています。現状、分類コード付与は、医療スタッフがテキストを読解しながら行うため大きな手間がかかっており、AIによる支援が期待されています。
CLEF eHealthは、医療テキストを対象としたAIに関する学会であり、今年はスペイン語医療テキストに対する分類コード自動付与がテーマとして取り上げられました。分類コードとしては、世界保健機関(WHO)が定めた国際疾病分類第10版(ICD-10)が世界標準となっており、今回はそのスペイン語版であるCIE-10のコードを付与するタスクとなりました。大会は、学会が提供する共通データを対象に、各参加団体がAIシステムを構築して分類コード自動付与を行い、参加団体間で精度を競い合うコンペティション形式で行われました。タスクは、テキストに対する①診断コード付与、②治療コード付与、③診断・治療コードおよび参考情報付与、の3つのサブタスクが設けられました。
世界11か国から22団体の大学・企業・研究機関が参加するなか、我々は3つのサブタスクすべてにエントリーしました。ルールベースと機械学習ベースの手法を統合する独自の手法を考案し、人手作業を発生させることなく高精度な臨床コード付与を実現しました。この手法を学会提供の課題データに適用したところ、タスク3で最高スコアを達成して1位を獲得、タスク1とタスク2で2位を獲得しました。9月22日~9月25日の大会において本成果の報告を行うとともに、成績優秀団体として大会特別セッションにおいて招待講演を行いました(図1)。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
技術の特徴
自動臨床コード付与に関する従来の研究では、主にルールベースと機械学習ベースの2種類の手法が採用されてきました。ルールベースの手法では、臨床コードに関する分野知識を使ったきめ細かい現場適用ができる半面、分野専門家によるルール構築に膨大な手間がかかるという問題がありました。一方、機械学習による手法では、人手作業は大幅に軽減できる半面、学習データ不足により十分に学習ができないという問題がありました。特に、機械学習において、1万種類に上る臨床コードから1つの臨床コードを選択する分類問題では膨大な学習データが必要になり、現実的には十分な量の自然言語の文章を構造化し大規模に集積した学習コーパスが用意できない問題が発生していました。
今回、ルールベースと機械学習ベースの手法を統合する独自の手法を考案し、人手作業を発生させることなく高精度な臨床コード付与を実現し、本ワークショップを通じてその有効性を実証しました。提案手法では、臨床テキストから専門用語を自動的に抽出し、自然言語処理によって自動的に構築した、臨床コードの知識体系と照合することによって、自動臨床コード付与を実現しています。機械学習に適した専門用語抽出のステップをはさむことによって、入力テキストを直接多数の分類コードに分類するという難しい課題を回避し、自動的かつ高精度な処理を実現しています。
今後、ゲノム医療を始めとする当研究所のヘルスケア分野向けAI技術として、現場での実証を経て社会実装を進めるとともに、さらなる技術の深化を進めていきます。
付録:技術詳細
コンペティションで使用したシステムについて、図2のシステムアーキテクチャーを用いて説明します。図中、「CIE-10」は、国際疾病分類第10版(ICD-10)のスペイン語版で、今回のタスクは、入力の臨床テキストにCIE-10の分類コードを付与するタスクになります。事前準備となる学習の段階では、CIE-10を機械処理可能な疾病知識体系(KG)に変換します。また、ワークショップが用意した学習データである、正解コードが付与された臨床テキストを用いて、臨床テキストからの専門用語抽出を学習させます。専門用語抽出の学習は、さらに事前学習モデルであるBERTを用いて強化しています。システムの実行時には、入力臨床テキストに対して専門用語抽出を行い、独自に開発した距離計算手法を用いて、専門用語群と疾病知識体系の照合を行って、分類コードを付与します。さらに、富士通独自のテキスト拡張技術を適用して、専門用語抽出における学習データセットを拡張することでデータ不足問題を解決しています。
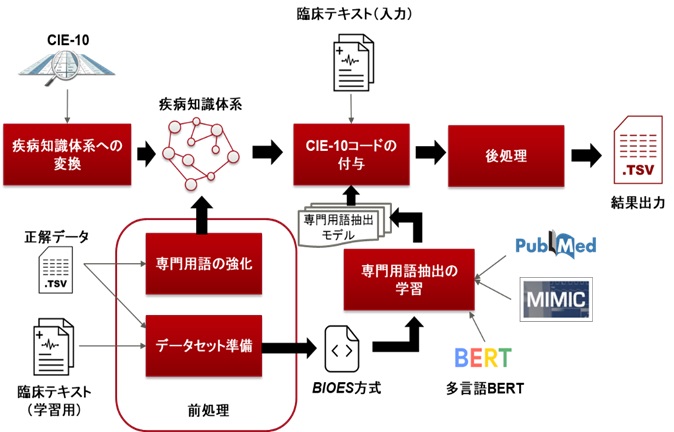 図2 システムアーキテクチャー
図2 システムアーキテクチャー
関連ニュース
・July 04, 2019: Fujitsu Applies Innovative AI Text Mining to Automate Medical Notes Coding![]()
・November 10, 2016: Fujitsu’s Human-Centric AI Helps Enable Faster, Improved Clinical Decision-Making![]()
本件に関するお問合せ
contact-clef2020@cs.jp.fujitsu.com
EEA (European Economic Area) 加盟国所在の方は以下からお問い合わせください。
Ask Fujitsu
Tel: +44-12-3579-7711
http://www.fujitsu.com/uk/contact/index.html![]()
Fujitsu, London Office
Address :22 Baker Street
London United Kingdom
W1U 3BW
このページをシェア
Recommend
Connect with Fujitsu Research


