
可加速数据分析的数据准备工作自动化技术
本技术介绍参考了以下链接
English
2018年05月15日
可加速数据分析的数据准备工作自动化技术
株式会社富士通研究所(注1)(以下简称,富士通研究所)开发了一项数据准备工作的自动化技术,它可以集成在收集和使用数据时所需的数据格式等,这些数据生成于多种不同目的。
开发背景
近年来,集成和利用各种数据的新业务创造和新产品开发变得越来越重要,其中包括结合了POS数据和社交媒体数据的市场分析,以及利用地方医院收集到的电子病历进行分析的药物发现研究等。富士通研究所从数据流通和使用的角度出发,将需要的各种数据处理技术系统化,开展了称作“Data Bazaar(数据集市)”的研究(图1)。该Data Bazaar由一套综合的基础数据处理技术组成,通过格式化、集成、分析各种分散数据,使之高效连接,并将提取到的价值安全及时地提供给用户,从而创造新的商业机会。作为其中一环,此次富士通研究所开发了一项技术,可以使数据自动格式化并集成为连接的形式。
例如,通过利用该技术对本公司的POS数据和天气信息进行关联与分析,与仅分析本公司数据相比,能获得难以发现的知识与见解,因此可将其用于销售策略制定和新产品研发。
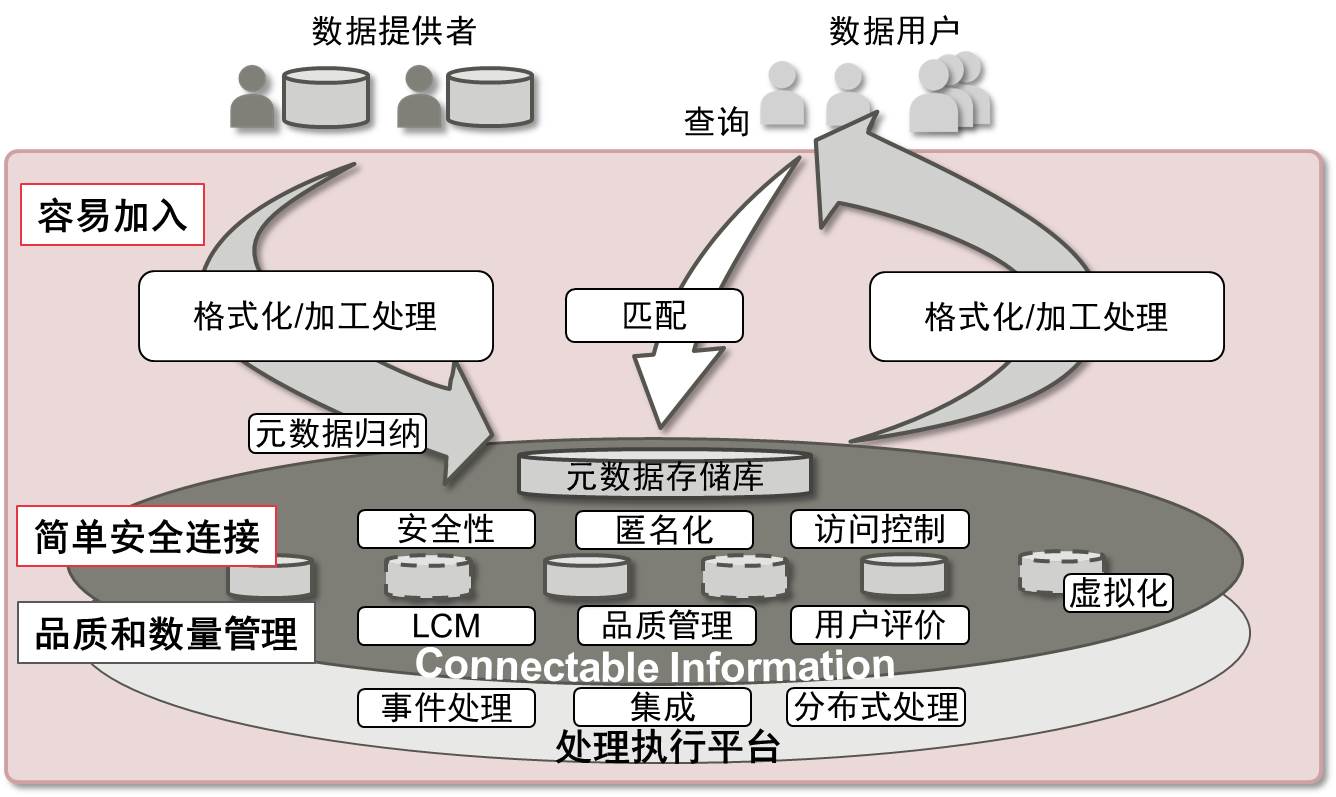
图1 基于Data Bazaar的数据应用
课题
在传统的数据准备工作中,为了获得目标数据,需要充分掌握材料数据的转换和集成方式,并通过逐个连接来创建数据,这需要具有高技能的人才花费很长时间来完成。另外,在集成作业中,可能会出现需要添加缺少的数据集,或因转换程序考虑不充分,无法获得处理后的目标数据等问题,这就需要反复摸索改进方法。像这样的数据准备工作,从数据准备到分析的整个过程,约80%是用来反复理解数据,格式化并集成数据,对集成的数据进行验证的。
为了高效地格式化并集成数据,已有研究致力于基于目标转换结果的实例,开发数据的自动转换技术。为此,需要在尝试各种转换处理(如业务中假定的符号和格式统一、单位转换等)的同时,结合缺失的数据集进行不断补充,并对可实现目标数据集成结果的组合进行穷举搜索。当格式化处理变得更加复杂时,业务所需的转换处理和缺失的数据集也会随之增加,这时需要搜索的组合数量将变得十分庞大,使得很难在现实的时间范围内完成该处理过程。
开发的技术
为了实现数据的自动格式化、集成处理,富士通研究所开发了一项技术,通过提高数据处理组合的搜索速度,在转换处理数量或缺失数据集增加,组合数量变大的情况下,也可以快速完成数据处理。
该技术具有以下特点
1. 基于转换处理历史记录预测所需处理,提高搜索效率
该技术从加工处理前的数据开始,针对数据库上的每个数据列(栏),分别计算应用各种转换处理获得的中间结果,如符号和格式统一、单位转换,缺失的数据集等,然后计算中间结果与目标数据之间的相似度。接下来,基于相似度高的中间结果,进一步应用转换处理,计算下一个中间结果,计算相似度并重复该过程,使其高效接近目标数据。
此次,我们开发了一项技术,它针对应用于中间结果的转换处理,通过保持转换处理和转换结果的历史记录,并预测能生成与目标数据相似数据的转换处理,可减少不必要的转换处理(图2)。
通过应用该技术,与仅基于目标数据进行搜索相比,搜索时间缩短到了原来的几十分之一。
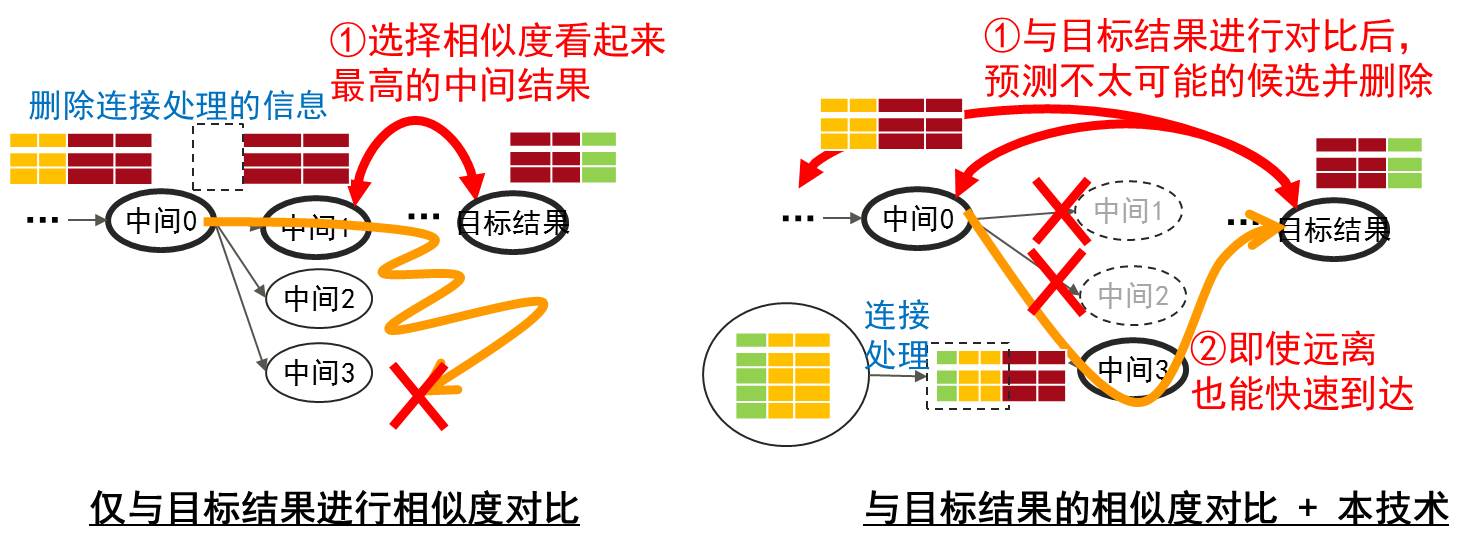
图2 提高转换处理搜索效率的技术
2. 高效搜索缺失数据,实现相似数据快速过滤
为获取目标处理数据,出现数据集缺失时,可基于背景知识,通过人工高效地搜索合适的数据集。但要实现其自动化,则需要将准备的辅助数据集作为库,对其进行循环调查,这样,在处理上会花费大量时间。
此次,富士通研究所开发了一项技术,通过将准备的辅助数据作为库,预先计算出每列所包含的值的分布特征并作为元数据,然后计算与中间数据算出的特征的相似度,可实现快速过滤缺失数据(图3)。
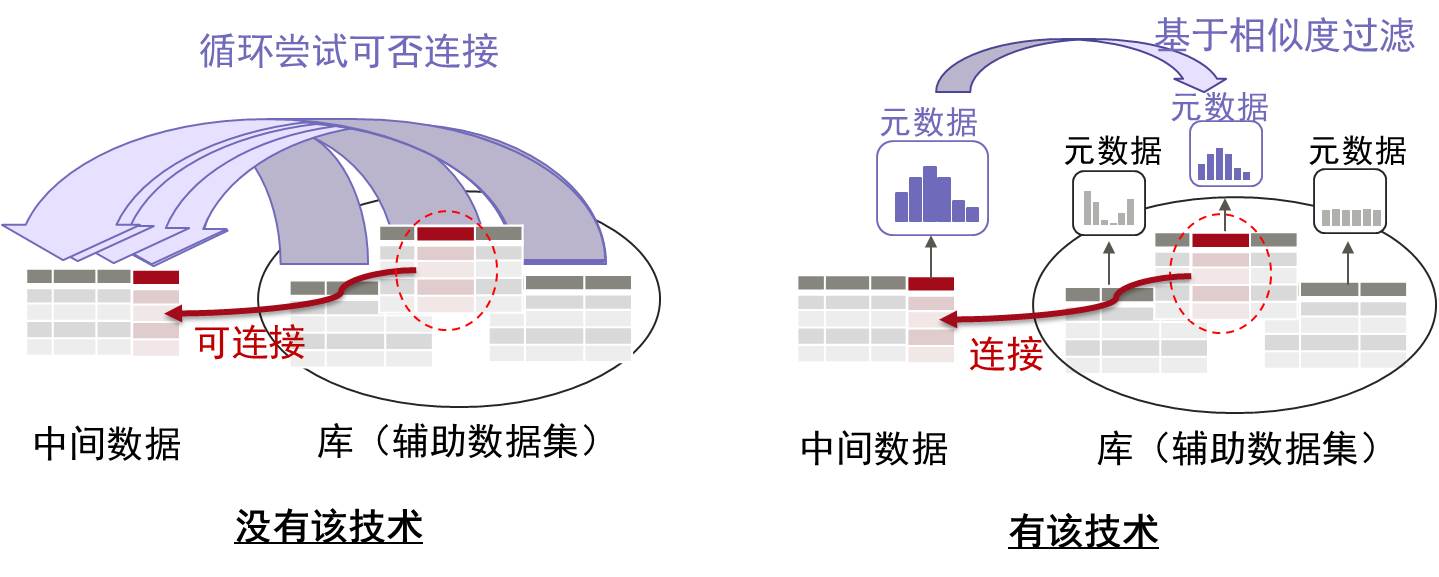
图3 相似数据快速过滤技术
效果
此次,富士通研究所将该技术应用于一个过去处理过的,基于约8,000个POS交易数据的市场营销分析数据集中,原来需要5天才能完成的数据准备工作,现在用半天时间即可完成,大大缩短了数据分析的准备时间。
该技术可促进企业公司间的数据互用性和数据流通,加速数据分析,为以新见解为基础的企业新业务创造做出贡献。
今后
今后我们将对该技术反复进行验证实验,同时进一步扩展功能,包括扩充转换处理类型、支持作为辅助数据的开放数据等,并将其作为构建Data Bazaar的一种功能,目标于2018年实现商业化。