![]()
Archived content
NOTE: this is an archived page and the content is likely to be out of date.
Whole system reliability supported by PRIMECLUSTER
Enterprise and business critical systems in the broadband and internet age are required to provide non-stop services 24 hours a day, 365 days a year.
Any system improvement requires not just the choice of highly reliable components, but an integrated management of the system components that maximizes total system reliability.
PRIMECLUSTER is the high reliability system foundation Fujitsu has developed to match the needs of the most demanding customers.
High reliability of the total system is assured by the self-governing mechanisms within PRIMECLUSTER. These include, virtualization of redundant components, fast error detection, application take-over and system downgrading to ensure operational continuity.
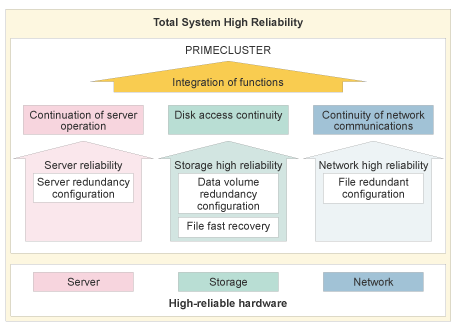
Continuity of Server Operation
PRIMECLUSTER can virtualize multiple SPARC Enterprise servers into a single server image. Collaboration with the system management feature in SPARC Enterprise systems enables fast and exact error detection and application swapping or failover.
Collaboration with Oracle Real Applications Cluster drives high performance and minimizes system downtime caused by server separation or addition.
Disk Access Continuity
Disk mirroring functions protect stored data from hardware failure by duplicating distributed data systems.
PRIMECLUSTER integrates such distributed storage and enables shared file systems to operate in a clustered environment.
These functions provide the necessary reliability to correctly switch data access when cluster status changes occur.
Continuity of Network Communications
Even during a network failure, network communication is assured by the use of network redundancy functions that quickly downgrade and switching network routing to unaffected circuits.
Trunking and other functions support network redundancy, switching, workload balancing and bandwidth improvement across the supported multiple network routes.


