

ChatGPTなど生成AIの登場は社会に大きなインパクトをもたらし、同時にAIの信頼性や安全性への関心がさらに高まっています。こうした状況の中、富士通は東京工業大学、東北大学、理化学研究所と協力してスーパーコンピュータ「富岳」を活用した大規模言語モデルの学習手法の開発に取り組むことを発表しました。
今回の取り組みを通じて富士通は何を目指すのか。大規模言語モデル研究の最前線に立つ富士通研究所 人工知能研究所 AIイノベーション コアプロジェクト リサーチディレクターの小林 健一に聞きました。
- 目次
「人間並み」のLLMを実現するには「富岳」の持つ計算パワーが必要
—ChatGPTに代表される生成AIが注目されています。AIには無限の可能性があり、人間の能力を超えるのではと思えてしまうほどの衝撃ですが、こうした中で富士通も、大規模言語モデル(Large Language Model:LLM)の開発にスーパーコンピュータ「富岳」を活用する取り組みを発表しましたね。
小林: 生成AIとは、分かりやすくいえば「文章や画像などのコンテンツを、人間並みに生成できるAI」のことです。代表的なものは文章や画像などのコンテンツを生成するAIですが、それらに限らず、音楽や動画などを生成できるAIもあります。ChatGPTのように自然な文章を生成できるAIはLLMと呼ばれます。
富士通では、これまでもLLMの研究・開発に取り組んできましたが、それほど大きな規模のものではありませんでした。ところが、ChatGPTの登場で世の中に大きな衝撃が走り、日本がこの分野の研究・開発で後れを取ってしまうのではないかという危機感も生まれました。また、LLMは英語を中心に開発が進められています。今、このタイミングで日本語のLLMの開発にきちんと取り組まないと、この先もずっと日本語のLLMは精度が低いままとなってしまうとも考えられました。
そこで、これまでの延長線上ではなく、圧倒的な規模でLLMの研究・開発に取り組もうと動き出したのです。具体的には東京工業大学、東北大学、富士通、理化学研究所、名古屋大学、サイバーエージェントと組んで、「富岳」を活用してこれまでにないほど大規模で新しい日本語のLLMを作ろうという取り組みです。
—そうした背景があるからでしょうか、今回の取り組みは富士通をはじめとする産学が協力し、「富岳」を活用していわゆる「国産ChatGPT」の開発に乗り出したと思われているところもあるように感じます。その理解で正しいのでしょうか。
小林: 意外に思われるかもしれませんが、今回の取り組みはChatGPTのようなLLMを開発することが最終目的ではないということです。LLMを作るのではなく、LLMを開発できるように「環境を整えること」が目的です。この取り組みが終わりを迎えるころには、LLMを開発するための技術上のさまざまな知見が得られているでしょう。その環境を構築するのに「富岳」を活用するということです。LLMで「人間並み」を実現するには、膨大なデータをもとにした大規模な深層学習が必要になり、そのためには高性能な計算資源が必須となります。そこに「富岳」のパワーが必要となります。

まだ引き出せていない「富岳」のパワーを5倍に高める
—膨大なデータを学習させるとのことですが、どの程度のデータ量になるのでしょうか。
小林: 膨大なデータというのは確かですが、まだ多くの検討事項があり、具体的な量についてはお答えできる段階ではありません。ただ、学習時の計算量については、これ以上は必要だろうというラインは分かっています。LLMのような基盤モデルで、1023FLOPsという膨大な計算量の学習をさせると、これまで全くできなかったことを、教えてもいないのに突然できるようになる「創発性」が発揮されることが確認されています。つまり、LLMを人間並みにするには、1023FLOPsという通常のコンピュータでは到底不可能な規模(スマホ1台で実行すると6000年)の膨大な計算量の学習をさせる必要があるということです。
それだけの学習をさせるとLLMの性能が飛躍的に向上し、これまで持っていなかった言語能力を獲得するといわれているのです。しかも、データ量と計算量を増やせば、AIがこの先もさまざまな能力を自然に獲得することができると考えられています。
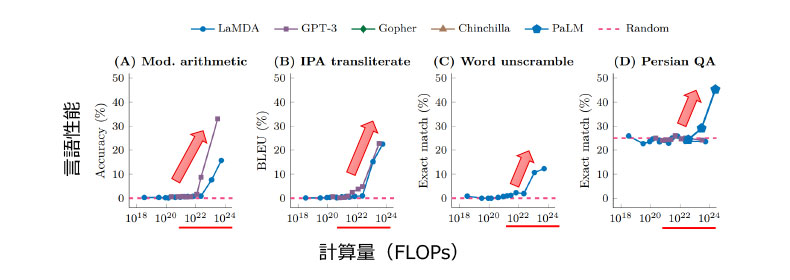 計算量の増加にともなって現れる創発性(飛躍的性能向上)(図はhttps://arxiv.org/abs/2206.07682より引用)
計算量の増加にともなって現れる創発性(飛躍的性能向上)(図はhttps://arxiv.org/abs/2206.07682より引用)
そこで、「富岳」を活用します。「富岳」はスーパーコンピュータとしてさまざまな目的で使われることを想定して汎用的に設計されているのですが、実は今回のようなLLMの学習はその想定には入っていませんでした。この取り組みが始まる前は、LLMの学習については、「富岳」が持つ能力のわずか10%しか引き出せていませんでした。そこで、「富岳」で用いられるLLM向けの学習ソフトウェアを最適化し、能力を50%まで引き出すことを目指しています。
—どうやって10%を50%に引き上げるのでしょう。5倍も高めるのですよね。
小林: それには、分散並列処理の技術が鍵を握ります。これほど巨大なLLMになると学習データも膨大ですが、LLM自身も巨大になって1台のサーバーには収まりきらず、多数のサーバーに分割して配置する必要があります。今回は数万台のサーバーが使用されます。そして学習時にはそれら多数のサーバーを密に通信させながら並列に動作させる必要があります。データをどのように分割配置し、LLM自身をどのように分割配置し、膨大な数に分割された学習処理をどの順で実行させるかを決め、学習処理中に多数のサーバーで計算された途中結果をどのように通信させて共有するかを計画するなど、非常に多くの要素が複雑に絡み合います。これら複雑な処理を最適化して効率よくこなすのが、「分散並列処理」の技術です。LLMの学習向けにその技術とソフトウェアを開発することで、「富岳」の能力を50%まで引き出すことを目指しています。
「富岳」は全体で約16万ノード(1ノードがサーバー1台に当たる)になりますが、この取り組みではその5分の1の約3万ノードを利用する予定です。この条件で、GPT-3相当のLLMを実現するのに必要となる3×1023FLOPsという膨大な計算量を今の「富岳」のままで処理しようとすると約150日かかります。LLM用の分散並列処理技術を開発して最適化することで、これを約30日までに短縮しようというのが、これから約半年をかけて実現しようという目標のひとつです。
もうひとつの目標は、学習させるLLMの言語性能を高めること、特に日本語に対する性能を高めることです。LLMの日本語性能をより高めるには、とにかく膨大な量の日本語データを用意する必要があります。それも闇雲に集めるのではなく、良質なデータを集める必要があります。あわせて、日本語の言語としての特性を踏まえて、LLMが日本語を理解しやすいように前処理すること、さらに出力された文章が人間にとって無害で適切になるようにLLMを調整することも重要です。ここにも様々な要素が絡むため、いきなり最初から最高性能のLLMを学習させることはむずかしいでしょう。まずは最終ゴールのLLMの10分の1くらいの小さなLLMから始め、実験を繰り返しながら段階的に性能を高めていく予定です。

AIが人間に近づくほど透明性と説明責任の重要性が高まる
—富士通の人工知能研究所では、ChatGPTがカバーできない領域のLLMや、機密情報を扱えるLLMなど、さまざまなLLMの研究・開発にも取り組んでいますね。
小林: ChatGPTはクラウド上で提供されるサービスですが、自治体が管理している個人情報はクラウド上で保管したり処理したりすることは法律で禁止されています。また、金融機関の機密性の高いデータもクラウド上で管理・処理するのが認められないケースが多くあります。このように機密性の高い情報を扱う組織や機関においてLLMを活用する場合には、機密情報が外部に漏洩しないように専用のLLMを構築する必要があります。そういったLLMをどう構築すればいいのか、そういった研究・開発に取り組んでいます。
また、専門性の高い企業や職種で生成AIを活用するには、その業種・業界に特化したLLMが必要となるでしょう。これを実現するためには、専門家の知見や熟練技術者が持っているノウハウなどもLLMに学習させなくてはなりません。こうした専門性の高いLLMは、ノウハウや知見が凝縮された、言ってみれば「秘伝のタレ」のようなものです。活用したいと同時に守りたいという声をよく聞きます。
こうした、さまざまなLLMに画像や音声、動画といったコンテンツを組み合わせていくと、これまで以上にAIの活用が広がっていくと考えて取り組んでいます。
—先ほど、LLMは生成AIのひとつの領域というお話しを伺いました。LLMを研究・開発してきた立場から、現在のLLMや生成AIのリスクについてどのようにお考えでしょうか。
小林: LLMや生成AIが持つリスクは、信頼性や倫理観に直結する問題も少なくありません。例えば、不正確な内容や間違った内容が出力されるハルシネーション(※1)は、AIの信頼性を損ねる原因となるでしょう。
-
※1ハルシネーション:生成AIにおけるハルシネーションとは、事実とは異なる不正確な回答をAIが生成してしまう現象
また、倫理観に関する問題としては、ディープフェイクによって作成された有名政治家の偽画像が深刻な社会問題を引き起こす可能性がありますし、普段の生活で起こりそうな例でいえば、子どもに爆弾の作り方を教えてしまうなど、LLMが不適切な回答をしてしまう恐れがないとはいえません。
AIが進化するということは、言い方を替えれば「より人間に近づいていく」ということだと思います。人間と同じような能力を備えてきたということは、常識や善意も身につけていると期待してしまいますが、そこはまだまだ不十分で研究の余地の多い領域です。ですから、これからは、AIを活用したシステムでは、そのAIがどのように作られているのかという透明性の確保と、どのような経緯でAIが回答を導き出したのかを示す説明責任が問われます。今後、AIの能力が上がれば上がるほど、その要求は高まるでしょう。
期待して楽しむ、それが「新しいAI時代」
—富士通では以前より「説明可能なAI」の開発に取り組んできました。その視点も踏まえて、今後のAI活用の在り方、理想のAI社会についてのお考えを聞かせてください。
小林: 富士通が説明可能なAIの開発に向けて取り組んでいるのは、AIを社会の基盤として安心して活用して欲しいという、AIを開発し、提供する立場としての使命感があるからです。AIが何故そのような判断を下したのか、どのような学習データから導き出された結論なのかといったことを明確に説明できることが安心につながります。
これからのAIは説明可能であることに加えて、導き出した答えに思想の誘導が入っていないか、何らかの意図に沿って情報を取捨選択した結果ではないかといった倫理的な側面での透明性も重要になるでしょう。先ほども説明したように「AIの能力が高まれば高まるほど、透明性や説明責任が問われる」のです。
このようにAIにはさまざまな課題がありますが、一方でこれからのAIには無限の可能性が広がっていることは間違いないでしょう。20数年前、インターネットと検索が世に広まって世界が広がり、さまざまな人たちと知恵を共有できるようになった素晴らしい変化がありました。今回も同様です。これまでできなかったことができるようになり、人間がしなくてはならなかった煩わしいことからも解放される社会に変わっていくと思います。
そのような意味で、AIを怖い・不気味な存在だと恐れるのではなく、大きな期待を抱いていただきたいというのが開発者としてのメッセ―ジです。富士通は、企業のお客様に対してAIを届けることをミッションとし、さまざまな素晴らしい可能性があることを伝えていきます。そして、お客様が安心・安全にAIを活用できるよう、技術的な課題もクリアしていきます。
ChatGPTに代表される生成AIは世の中に大きなインパクトを与えました。人間のすることが失われる、仕事が奪われると不安を抱いたり、ある意味での恐怖を感じたりした人もいるかもしれません。しかし、AIには無限の可能性があるのも事実です。恐れるのではなく、期待して楽しむということを念頭に、「新しいAI時代」を迎えていただきたいと考えています。

富士通株式会社
富士通研究所 人工知能研究所
AIイノベーション コアプロジェクト
リサーチディレクター
小林 健一



{kind=link}
{kind=link}