![]()
Solaris活用ナビ ~Practical Tips for SPARC~
第2回:SPARC Servers / Solaris上でHadoopとSparkを使ってみよう(Hadoopクラスタ構成構築編)
2017年11月14日
第1回ではHadoopのシングル環境構築を行いました。
今回はHadoopのクラスタ環境構築を行います。
Hadoopクラスタについて
HadoopクラスタではNameNodeとResourceManagerをZookeeper(Hadoopとは別パッケージ)で冗長化させます。また、JournalNodeによりNameNodeの情報を分散して管理します。
ZookeeperとJournalNodeの最低構成台数は3台となっているので環境を準備する際は注意してください。
なお、Zookeeperについての詳細は以下を参照してください。
構成について
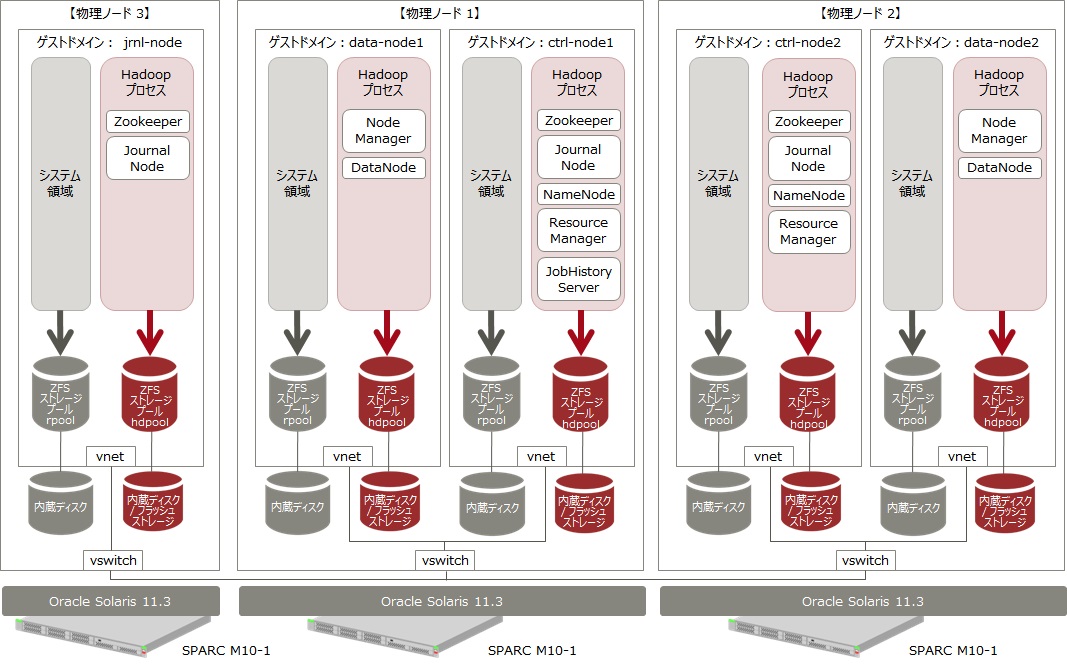
今回はHadoopクラスタの冗長性要件を満たすために物理ノードは3台で構成します。Hadoop環境はOracle VM for SPARCのゲストドメインとして構築していきます。
作成するゲストドメインとその用途は以下となります。
(物理ノード1)
ctrl-node1(NameNode、ResourceManager、JobHistoryServer、Zookeeper、JournalNodeを実行します。)
data-node1(DataNode、NodeManagerを実行します。)
(物理ノード2)
ctrl-node2(NameNode、ResourceManager、Zookeeper、JournalNodeを実行します。)
data-node2(DataNode、NodeManagerを実行します。)
(物理ノード3)
jrnl-node(Zookeeper、JournalNodeを実行します。)
確認したOS/ソフトのバージョンは第1回と同様です。今回はZookeeperが含まれています。
- サーバ:SPARC M10-1
- OS:Oracle Solaris11.3 SRU 10.7
- Java:jdk 1.7.0_111
- Hadoop:2.7.3
- Zookeeper:3.4.9
仮想環境の構築
制御ドメインの作成
制御ドメインの作成は以下を参照してください。今回は制御ドメインを直接使用しないためホスト名等は任意で構いません。
ゲストドメインの作成
ゲストドメインは前記の5つを作成します。ホスト名はドメイン名と同じにしておきます。
ゲストドメインの作成に関しては下記を参照してください。
なお、各ゲストドメインにはシステムボリュームとは別にHadoopデータ用のデバイスを仮想ディスクとして組み込んでおきます。
以下はすべてrootで作業してください。特に記載が無い限りすべてのゲストドメインで同じように設定します。
ZFSプールの作成
Hadoopデータ用ZFSストレージプールを作成します。ストレージプール名はhdpoolとします。
# zpool create hdpool
必要なパッケージのインストール
第1回の記事を参考にjdk7をインストールし、Javaのバージョンをjava7にします。
/etc/hostsの編集
/etc/hostsを編集します。関連するノードのIPアドレスをすべて記載します。下記はctrl-node1の例です。
::1 localhost
127.0.0.1 localhost loghost
xxx.xxx.xxx.xxx ctrl-node1 crtl-node1.local
xxx.xxx.xxx.xxx ctrl-node2
xxx.xxx.xxx.xxx jrnl-node
xxx.xxx.xxx.xxx data-node1
xxx.xxx.xxx.xxx data-node2
Hadoop用ユーザー/グループの追加
Hadoop用グループIDをhadoopという名前で作成します。以下作成するユーザーの所属グループはhadoopとします。
# groupadd -g 200 hadoop
NameNodeとDataNodeの実行用ユーザーIDをhdfsという名前で作成し、パスワードの設定を行います。
# useradd -u 200 -m -g hadoop hdfs
# passwd hdfs
ResourceManagerとNodeManagerサービスの実行用ユーザーをyarnという名前で作成し、パスワードの設定を行います。
# useradd -u 201 -m -g hadoop yarn
# passwd yarn
History Serverサービスの実行用ユーザーをmapredという名前で作成し、パスワードの設定を行います。
# useradd -u 202 -m -g hadoop mapred
# passwd mapred
実際のジョブの実行用ユーザーをsparkという名前で作成し、パスワードの設定を行います。
# useradd -u 101 -m -g hadoop spark
# passwd spark
Hadoopのインストール
HadoopとZookeeperをダウンロードし、インストールするノードに転送します。
HadoopとZookeeperをインストールします。
# cd /opt
#
# ln -s hadoop-2.7.3 hadoop
# ln -s zookeeper-3.4.9 zookeeper
HadoopとZookeeperのオーナー/パーミッションを変更します。
# chown -R root:hadoop /opt/hadoop-2.7.3
# chmod -R 755 /opt/hadoop-2.7.3
# chown -R root:hadoop zookeeper-3.4.9
# chmod -R 755 /opt/zookeeper-3.4.9
SSH通信の設定
Hadoopはsshで通信を行って処理を実行するため、ユーザー毎にssh通信用の証明書を作成します。
# su - hdfs
# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# logout
# su - yarn
# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# logout
# su - mapred
# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# logout
他ノードの公開証明書を自ノードにコピーし、authorized_keysファイルに格納します。
# su - hdfs
# cd .ssh
# scp <他ノード>:/export/home/<ユーザー名>/.ssh/id_dsa.pub <他ノード名>_id_dsa.pub
# cat <他ノード名>_id_dsa.pub >> authorized_keys
# logout
# su - yarn
# cd .ssh
# scp <他ノード>:/export/home/<ユーザー名>/.ssh/id_dsa.pub <他ノード名>_id_dsa.pub
# cat <他ノード名>_id_dsa.pub >> authorized_keys
# logout
# su - mapred
# cd .ssh
# scp <他ノード>:/export/home/<ユーザー名>/.ssh/id_dsa.pub <他ノード名>_id_dsa.pub
# cat <他ノード名>_id_dsa.pub >> authorized_keys
# logout
この処理の途中で以下のようなメッセージが表示された場合はyesと入力します。
The authenticity of host 'XXXXXXXX (xx.xx.xx.xxx)' can't be established.
RSA key fingerprint is xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx.
Are you sure you want to continue connecting (yes/no)?
パスワードの入力を求められた場合はパスワードを入力します。
各ユーザーですべてのノードにSSH通信が出来ることを確認します。
環境変数の設定
各ユーザーにHadoop実行のための環境変数を設定します。
hdfsユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_PID_DIR=/hdpool/run/hdfs
export ZOOKEEPER_USER=hdfs
export ZOO_LOG_DIR=/hdpool/log/zookeeper
export ZOO_PID_DIR=/hdpool/run/zookeeper
export ZOOPIDFILE=$ZOO_PID_DIR/zookeeper_server.pid
export ZOO_DATADIR=/hdpool/data/zookeeper
export ZOOCFG=/opt/zookeeper/conf
export HADOOP_GROUP=hadoop
yarnユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_PID_DIR=/hdpool/run/yarn
mapredユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export MAPRED_PID_DIR=/hdpool/run/mapred
sparkユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Hadoop環境ファイルの設定
Hadoop用ディレクトリの設定
Hadoopのデータ格納用のディレクトリを作成していきます。今後の運用を考えてZFSのファイルシステムとして作成します。
hdfsユーザー用ログファイルディレクトリを作成します。
# zfs create -p hdpool/log/hdfs
# chown hdfs:hadoop /hdpool/log/hdfs
yarnユーザー用ログファイルディレクトリを作成します。
# zfs create -p hdpool/log/yarn
# chown yarn:hadoop /hdpool/log/yarn
mapredユーザー用ログファイルディレクトリを作成します。
# zfs create -p hdpool/log/mapred
# chown mapred:hadoop /hdpool/log/mapred
NameNodeのメタデータ用ディレクトリを作成します。
# zfs create -p hdpool/data/1/dfs/nn
# chmod 700 /hdpool/data/1/dfs/nn
# chown -R hdfs:hadoop /hdpool/data/1/dfs/nn
NameNodeのデータブロック保管用ディレクトリを作成します。
# zfs create -p hdpool/data/1/dfs/dn
# chown -R hdfs:hadoop /hdpool/data/1/dfs/dn
JournalNode用ディレクトリを作成します。
# zfs create -p hdpool/data/1/dfs/jn
# chown -R hdfs:hadoop /hdpool/data/1/dfs/jn
yarnユーザーが使用するローカルデータディレクトリを作成します。
# zfs create -p hdpool/data/1/yarn/local
# zfs create -p hdpool/data/1/yarn/logs
# chown -R yarn:hadoop /hdpool/data/1/yarn/local
# chown -R yarn:hadoop /hdpool/data/1/yarn/logs
ランタイム用のディレクトリを作成します。
# zfs create -p hdpool/run/yarn
# chown yarn:hadoop /hdpool/run/yarn
# zfs create -p hdpool/run/hdfs
# chown hdfs:hadoop /hdpool/run/hdfs
# zfs create -p hdpool/run/mapred
# chown mapred:hadoop /hdpool/run/mapred
一時的なデータの使用のディレクトリを作成します。
# zfs create -p hdpool/tmp
Zookeeperが使用する各種ディレクトリを作成します。
# zfs create -p hdpool/run/zookeeper
# chown -R hdfs:hadoop /hdpool/run/zookeeper
# zfs create -p hdpool/data/zookeeper
# chown -R hdfs:hadoop /hdpool/data/zookeeper
# zfs create -p hdpool/log/zookeeper
# chown -R hdfs:hadoop /hdpool/log/zookeeper
以下のコマンドを実行しディレクトリが作成されていることを確認します。
# zfs list -r hdpool
以下のように表示されれば正常に作成されています。
NAME USED AVAIL REFER MOUNTPOINT
hdpool 9.57M 1.94G 352K /hdpool
hdpool/data 2.96M 1.94G 320K /hdpool/data
hdpool/data/1 2.36M 1.94G 320K /hdpool/data/1
hdpool/data/1/dfs 1.17M 1.94G 336K /hdpool/data/1/dfs
hdpool/data/1/dfs/dn 288K 1.94G 288K /hdpool/data/1/dfs/dn
hdpool/data/1/dfs/jn 288K 1.94G 288K /hdpool/data/1/dfs/jn
hdpool/data/1/dfs/nn 288K 1.94G 288K /hdpool/data/1/dfs/nn
hdpool/data/1/yarn 896K 1.94G 320K /hdpool/data/1/yarn
hdpool/data/1/yarn/local 288K 1.94G 288K /hdpool/data/1/yarn/local
hdpool/data/1/yarn/logs 288K 1.94G 288K /hdpool/data/1/yarn/logs
hdpool/data/zookeeper 296K 1.94G 296K /hdpool/data/zookeeper
hdpool/log 1.47M 1.94G 352K /hdpool/log
hdpool/log/hdfs 288K 1.94G 288K /hdpool/log/hdfs
hdpool/log/mapred 288K 1.94G 288K /hdpool/log/mapred
hdpool/log/yarn 288K 1.94G 288K /hdpool/log/yarn
hdpool/log/zookeeper 288K 1.94G 288K /hdpool/log/zookeeper
hdpool/run 1.47M 1.94G 352K /hdpool/run
hdpool/run/hdfs 288K 1.94G 288K /hdpool/run/hdfs
hdpool/run/mapred 288K 1.94G 288K /hdpool/run/mapred
hdpool/run/yarn 288K 1.94G 288K /hdpool/run/yarn
hdpool/run/zookeeper 288K 1.94G 288K /hdpool/run/zookeeper
hdpool/tmp 288K 1.94G 288K /hdpool/tmp
シングルノードの時と同様にZFSの機能を用いてログ領域の圧縮を行います。
# zfs set compression=lz4 hdpool/log
ctrl-node1で以下のコマンドを実行します。
# su - hdfs -c 'echo "1" > /hdpool/data/zookeeper/myid'
ctrl-node2で以下のコマンドを実行します。
# su - hdfs -c 'echo "2" > /hdpool/data/zookeeper/myid'
jrnl-nodeで以下のコマンドを実行します。
# su - hdfs -c 'echo "3" > /hdpool/data/zookeeper/myid'
Hadoop環境設定ファイルの作成
Hadoopの構成ファイルのディレクトリ(/opt/hadoop/etc/hadoop)に移動します。
hadoop-env.shに以下を追加します。
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export JAVA_HOME=/usr/java
export HADOOP_LOG_DIR=/hdpool/log/hdfs
yarn-env.shに以下を追加します。
export JAVA_HOME=/usr/java
export YARN_LOG_DIR=/hdpool/log/yarn
export HADOOP_HOME=/opt/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
mapred-env.shに以下を追加
export JAVA_HOME=/usr/java
export HADOOP_MAPRED_LOG_DIR=/hdpool/log/mapred
export HADOOP_MAPRED_IDENT_STRING=mapred
slavesファイルを編集します。DataNodeの管理下に入るホスト名を記載します。今回はdata-node1とdata-node2です。
data-node1
data-node2
core-site.xmlファイルを以下のように編集します。
<
mapred-site.xmlファイルを以下のように編集します。
yarn-site.xmlファイルを以下のように編集します。
hdfs-site.xmlファイルを以下のように編集します。今回はDataNodeが2つのため、dfs.replicationは2にしています。
Zookeeper環境設定ファイルの作成
Zookeeperの構成ファイルのディレクトリ(/opt/zookeeper/conf)に移動します。
zoo.cfgファイルを以下のように編集します。
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/hdpool/data/zookeeper
clientPort=2181
server.1=ctrl-node1:2888:3888
server.2=ctrl-node2:2888:3888
server.3=jrnl-node:2888:3888
Hadoopの起動確認
Hadoopプロセスの起動
※注意:以下のようなwarningが出力されますが、動作には影響ありませんので無視してください。
xx/xx/xx xx:xx:xx WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
まず、ctrl-node1, ctrl-node2, jrnl-nodeでZookeeperを起動します。
# su - hdfs -c '/opt/zookeeper/bin/zkServer.sh start /opt/zookeeper/conf/zoo.cfg'
Zookeeperの起動を確認します。
# /usr/java/bin/jps | grep QuorumPeerMain
以下のように表示されれば正常に起動されています。
21384 QuorumPeerMain
ctrl-node1でZookeeperのHA状態を初期化します。
# su - hdfs -c 'hdfs zkfc -formatZK'
ctrl-node1, ctrl-node2, jrnl-nodeでJournalnodeを実行します。
# su - hdfs -c 'hadoop-daemon.sh start journalnode'
Journalnodeプロセスを確認します。
# /usr/java/bin/jps | grep JournalNode
以下のように表示されれば正常に起動されています。
21893 JournalNode
ctrl-node1でHadoop ファイルシステムをフォーマットします。
# su - hdfs -c 'hdfs namenode -format'
以下のように表示されれば正常にフォーマットされています。
16/10/24 08:17:36 INFO common.Storage: Storage directory /hdpool/data/1/dfs/nn has been successfully formatted.
ctrl-node1でJournalnodeをフォーマットします。特にエラーが無ければ正常に終了しています。ctrl-node1とjrnl-nodeも連携して初期化されます。
# su - hdfs -c 'hdfs namenode -initializeSharedEdits'
ctrl-node1でNameNodeを起動します。
# su - hdfs -c 'hadoop-daemon.sh start namenode'
ctrl-node1でNameNodeの起動を確認します。
# /usr/java/bin/jps | grep NameNode
以下のように表示されれば正常に起動されていされています。
25852 NameNode
ctrl-node1でResourceManagerを起動します。
# su - yarn -c 'yarn-daemon.sh start resourcemanager'
ctrl-node1でResourceManagerの起動を確認します。
# /usr/java/bin/jps | grep ResourceManager
以下のように表示されれば正常に起動されています。
25982 ResourceManager
ctrl-node1でzkfcを起動します。
# su - hdfs -c 'hadoop-daemon.sh start zkfc'
zkfcの起動を確認します。
# /usr/java/bin/jps | grep DFSZKFailoverController
以下のように表示されれば正常に起動されています。
26860 DFSZKFailoverController
ctrl-node2で以下のコマンドを使用し、ctrl-node1からHadoop ファイルシステム情報をコピーします。
# su - hdfs -c 'hdfs namenode -bootstrapStandby'
以下のように表示されれば正常にコピーされています。
16/10/24 08:17:36 INFO common.Storage: Storage directory /hdpool/data/1/dfs/nn has been successfully formatted.
ctrl-node2でNameNodeを起動します。
# su - hdfs -c 'hadoop-daemon.sh start namenode'
ctrl-node2でNameNodeの起動を確認します。
# /usr/java/bin/jps | grep NameNode
以下のように表示されれば正常に起動されています。
25852 NameNode
ctrl-node2でResourceManagerを起動します。
# su - yarn -c 'yarn-daemon.sh start resourcemanager'
ctrl-node2でResourceManagerの起動を確認します。
# /usr/java/bin/jps | grep ResourceManager
以下のように表示されれば正常に起動されています。
25982 ResourceManager
ctrl-node2でzkfcを起動します。
# su - hdfs -c 'hadoop-daemon.sh start zkfc'
zkfcの起動を確認します。
# /usr/java/bin/jps | grep DFSZKFailoverController
以下のように表示されれば正常に起動されています。
26860 DFSZKFailoverController
NameNodeの冗長化の状態を確認します。通常はnn1がactiveであれば正常です。ctrl-node1とctrl-node2のどちらでも実行は構いません。
# su - hdfs -c 'hdfs haadmin -getServiceState nn1'
Oracle Corporation SunOS 5.11 11.3 June 2016
16/10/24 14:29:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
# su - hdfs -c 'hdfs haadmin -getServiceState nn2'
Oracle Corporation SunOS 5.11 11.3 June 2016
16/10/24 14:29:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
ResourceManagerの冗長化の状態を確認します。通常はrm1がactiveであれば正常です。ctrl-node1とctrl-node2のどちらでも実行は構いません。
# su - yarn -c 'yarn rmadmin -getServiceState rm1'
Oracle Corporation SunOS 5.11 11.3 June 2016
16/10/24 14:29:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
# su - yarn -c 'yarn rmadmin -getServiceState rm2'
Oracle Corporation SunOS 5.11 11.3 June 2016
16/10/24 14:29:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
data-node1とdata-node2でDataNodeとNodeManagerを起動します。
# su - hdfs -c 'hadoop-daemon.sh start datanode'
# su - yarn -c 'yarn-daemon.sh start nodemanager'
DataNodeの起動を確認します。
# /usr/java/bin/jps | grep DataNode
以下のように表示されれば正常に起動されています。
26240 DataNode
NodeManagerの起動を確認します。
# /usr/java/bin/jps | grep NodeManager
以下のように表示されれば正常に起動されています。
26299 NodeManager
ctrl-node1でJobHistoryServerを起動します。
# su - mapred -c 'mr-jobhistory-daemon.sh start historyserver'
JobHistoryServerの起動を確認します。
# /usr/java/bin/jps | grep JobHistoryServer
以下のように表示されれば正常に起動されています。
26573 JobHistoryServer
ctrl-node1でHadoop内のディレクトリ構成を設定します。
# (name-node1にhdfsでログインする。)
# hadoop fs -mkdir /tmp
# hadoop fs -chmod -R 1777 /tmp
# hadoop fs -mkdir /data
# hadoop fs -mkdir /data/history
# hadoop fs -chmod -R 1777 /data/history
# hadoop fs -chown yarn /data/history
# hadoop fs -mkdir /var
# hadoop fs -mkdir /var/log
# hadoop fs -mkdir /var/log/hadoop-yarn
# hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
# hadoop fs -mkdir /data/spark
# hadoop fs -chown spark /data/spark
# hadoop fs -mkdir /apl
# hadoop fs -mkdir /apl/spark-2.1.0
# hadoop fs -chmod 775 /apl/spark-2.1.0
# hadoop fs -mkdir /apl/spark-2.1.0/jars
# hadoop fs -chmod 775 /apl/spark-2.1.0/jars
以下のコマンドを実行し、すべてのノードからHadoop内のディレクトリ構成が見えることを確認します。
# su - hdfs -c 'hadoop fs -ls -R /'
以下が作成されていれば正常に実行されています。
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:35 /apl
drwxrwxr-x - hdfs hadoop 0 2016-10-25 07:35 /apl/spark-2.1.0
drwxrwxr-x - hdfs hadoop 0 2016-10-25 07:35 /apl/spark-2.1.0/jars
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:32 /data
drwxrwxrwt - yarn hadoop 0 2016-10-25 07:26 /data/history
drwxr-xr-x - spark hadoop 0 2016-10-25 07:32 /data/spark
drwxrwxrwt - hdfs hadoop 0 2016-10-25 16:08 /tmp
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:29 /var
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:29 /var/log
drwxr-xr-x - yarn mapred 0 2016-10-25 07:29 /var/log/hadoop-yarn
動作確認
ブラウザーからhttp://
任意のノードでhadoopのサンプルプログラムを実行します。正常に終了すれば確認は終了です。
# su - spark
$ hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 20
Number of Maps = 10
Samples per Map = 20
17/03/01 15:21:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
17/03/01 15:21:56 INFO input.FileInputFormat: Total input paths to process : 10
17/03/01 15:21:57 INFO mapreduce.JobSubmitter: number of splits:10
17/03/01 15:21:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1484800892214_0017
17/03/01 15:21:57 INFO impl.YarnClientImpl: Submitted application application_1484800892214_0017
17/03/01 15:21:57 INFO mapreduce.Job: The url to track the job: http://ctrl-node1:8088/proxy/application_1484800892214_0017/
17/03/01 15:21:57 INFO mapreduce.Job: Running job: job_1484800892214_0017
17/03/01 15:22:08 INFO mapreduce.Job: Job job_1484800892214_0017 running in uber mode : false
17/03/01 15:22:08 INFO mapreduce.Job: map 0% reduce 0%
17/03/01 15:22:23 INFO mapreduce.Job: map 20% reduce 0%
17/03/01 15:22:37 INFO mapreduce.Job: map 20% reduce 7%
17/03/01 15:22:40 INFO mapreduce.Job: map 30% reduce 7%
17/03/01 15:22:43 INFO mapreduce.Job: map 40% reduce 10%
17/03/01 15:22:44 INFO mapreduce.Job: map 50% reduce 10%
17/03/01 15:22:46 INFO mapreduce.Job: map 50% reduce 13%
17/03/01 15:22:49 INFO mapreduce.Job: map 60% reduce 17%
17/03/01 15:22:50 INFO mapreduce.Job: map 80% reduce 17%
17/03/01 15:22:52 INFO mapreduce.Job: map 80% reduce 27%
17/03/01 15:22:53 INFO mapreduce.Job: map 100% reduce 27%
17/03/01 15:22:54 INFO mapreduce.Job: map 100% reduce 100%
17/03/01 15:22:55 INFO mapreduce.Job: Job job_1484800892214_0017 completed successfully
17/03/01 15:22:55 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=1339151
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2600
HDFS: Number of bytes written=215
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=318683
Total time spent by all reduces in occupied slots (ms)=28545
Total time spent by all map tasks (ms)=318683
Total time spent by all reduce tasks (ms)=28545
Total vcore-milliseconds taken by all map tasks=318683
Total vcore-milliseconds taken by all reduce tasks=28545
Total megabyte-milliseconds taken by all map tasks=326331392
Total megabyte-milliseconds taken by all reduce tasks=29230080
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1420
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=1414
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=1746141184
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 59.708 seconds
Estimated value of Pi is 3.12000000000000000000
以上で、仮想環境の構築からHadoopのクラスタ環境が構築できました。
次回はSpark構成の構築を行います。