![]()
Solaris活用ナビ ~Practical Tips for SPARC~
第1回:SPARC Servers / Solaris上でHadoopとSparkを使ってみよう(Hadoopシングル構成構築編)
2017年11月7日
はじめに
30年ほど前はシステム開発といえばSPARC/Solarisが主流であり、ミッションクリティカルな基幹系から小規模なシステムまでSPARC/Solarisで構築していました。OSSなども最初にSolarisで開発が行われ、その他のプラットフォームに移行されるのが普通でした。
近年はIAプラットフォームも性能・信頼性が高まってきており、OSSもIA/Linuxでの開発においても主流になってきましたが、SPARC/Solarisも進化し続けております。OSとハードウェアを一体に開発・機能拡張することにより、OS・ハードウェアそれぞれのよさを最大限に発揮しています。
例えば、SPARC M10/M12ではソフトウェア処理の一部をハードウェア(プロセッサ)上に組み込む「Software on Chip」という技術を採用しています。このようにハードウェア(プロセッサ)自体の機能拡張を行うのと同時に、Oracle Solaris OSがこの機能を自動的に利用する機能拡張も行っています。
ハードウェアの信頼性は以前にも増して高まっており、業務システムの安定稼動を確実なものにしています。
昨今はSolaris自体にOSSを最適化して取り込む傾向があり、より安定したOSSの運用が可能となっています。
また、SPARC/Solarisの長所を理解して使い続けておられるお客様を中心に、SPARC/SolarisとOSSの組み合わせに関するお問い合わせを受けることがあります。
このブログでは、そういった方々により幅広い分野で活用いただけるよう、SPARC/Solarisの特長を活かした利用例を紹介していきます。
ビッグデータ処理とSolaris
ビッグデータ処理でHadoopやSparkのようなOSS(Open Source Software)を使っている方も多いと思いますが、これらのOSSはLinux系のOSだけでなくもちろんSolarisでも動きます。
そこで、今回から3回に渡って、HadoopとSparkをSolarisの利点を活かしながら動作させる方法を解説していきます。
第1回:Hadoop シングルノード環境を構築する
第2回:Oracle VM for SPARC上でHadoop クラスタ環境を構築する
第3回:Hadoop クラスタ環境を使用してSparkのクラスタ環境を構築する
なお、HadoopやSparkの詳しい解説はここでは行いませんので適宜以下を参照してください。
今回はHadoopのシングルノード環境の構築を行います。
SPARC Servers / SolarisでHadoopを動作させる利点
Hadoopの解説に、「データを分散して持つため個々のノードの信頼性は必要ない」といった記述を目にすることがよくあります。
確かにデータ本体は複数のノードに複製して保管されますが、そのファイルシステムの情報を管理するNameNodeは冗長化を行っても2ノードまでしか構築できません。ここがHadoopの単一障害点(SPOF)となっています。開発者向けの環境であればNameNodeが壊れても作り直せばいいだけかもしれませんが、企業などで業務として運用している場合は業務の中断時間含めてそういうわけにはいきません。
少なくともNameNodeとResourceManagerを動作させるノードはSPARC M10のように信頼性の高いハードウェアを使ったほうがよいと思われます。
構成について
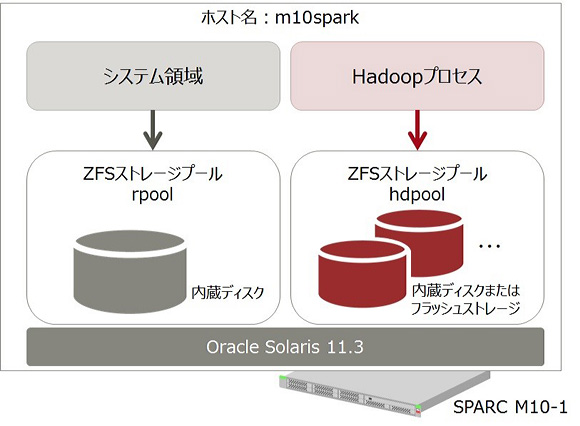
Hadoopのデータ用ディスクは通常のシステムボリューム(rpool)とは別にZFSストレージプールを作成します。
こうすることでシステムボリュームとは独立してディスクの追加等の操作を行うことが可能です。
SPARC M10では内蔵ディスクではなくフラッシュカードを使用することで、高速大容量のストレージを作成できます。
今回確認したサーバ/OS/ソフトのバージョンは以下になります。
- サーバ:SPARC M10-1
- OS:Oracle Solaris11.3 SRU 10.7
- Java:jdk 1.7.0_111
- Hadoop:2.7.3
環境の構築
OSのインストール
今回の環境はSPARC M10の制御ドメイン上に構築します。OSのインストールと初期設定は以下を参照してください。
ホスト名はm10sparkとしています。
以下はすべてrootユーザーで作業してください。
ZFSストレージプールの作成
Hadoop用データの格納先となるZFSストレージプールを作成します。今回はhdpoolという名前でZFSストレージプールを作成します。
# zpool create hdpool
必要なパッケージのインストール
通常Oracle Solaris11にはJava8がインストールされていますが、今回使用するHadoopで確認されているバージョンで最も新しいものがJava7のため、jdk7のパッケージをインストールします。 関連するパッケージもインストールされます。プロセスの起動確認用にjpsコマンドを使用する関係でjreだけでなくjdkもインストールしてください。ライセンスに同意が求められるため --accept オプションをつけて実行します。
# pkg install --accept developer/java/jdk-7
通常、jdk7をインストールした段階ではまだデフォルトのJavaのバージョンはJava8のままですので、以下の手順でJavaのバージョンを切り替えます。
まず現在のJavaのバージョンを確認します。
# java -version
java version "1.8.0_102"
Java(TM) SE Runtime Environment (build 1.8.0_102-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.102-b14, mixed mode)
以下のようにして2種類のJavaのバージョンがインストールされていることを確認します。
# pkg mediator -a java
MEDIATOR VER. SRC. バージョン IMPL. SRC. IMPLEMENTATION
java system 1.8 system
java system 1.7 system
以下のようにしてJavaのバージョンをJava7に切り替えます。
# pkg set-mediator -V 1.7 java
JavaのバージョンがJava7になっていることを確認します。
# java -version
java version "1.7.0_111"
Java(TM) SE Runtime Environment (build 1.7.0_111-b13)
Java HotSpot(TM) Server VM (build 24.111-b13, mixed mode)
/etc/hostsの編集
/etc/hostsを編集します。
::1 localhost
127.0.0.1 localhost loghost
xxx.xxx.xxx.xxx m10spark m10spark.local
Hadoop用ユーザー/グループの追加
hadoop用グループIDをhadoopという名前で作成します。以下作成するユーザーの所属グループはhadoopとします。
# groupadd -g 200 hadoop
NameNodeとDataNodeの実行用ユーザーIDをhdfsという名前で作成し、パスワードの設定を行います。
# useradd -u 200 -m -g hadoop hdfs
# passwd hdfs
ResourceManagerとNodeManagerサービスの実行用ユーザーをyarnという名前で作成し、パスワードの設定を行います。
# useradd -u 201 -m -g hadoop yarn
# passwd yarn
History Serverサービスの実行用ユーザーをmapredという名前で作成し、パスワードの設定を行います。
# useradd -u 202 -m -g hadoop mapred
# passwd mapred
実際のジョブの実行用ユーザーをsparkという名前で作成し、パスワードの設定を行います。
# useradd -u 101 -m -g hadoop spark
# passwd spark
Hadoopのインストール
Hadoopをダウンロードし、インストールするノードに転送します。
Hadoopをインストールします。
# cd /opt
#
# ln -s hadoop-2.7.3 hadoop
Hadoopのファイルのオーナーをroot、グループをhadoopに変更します。パーミッションはすべて755とします。
# chown -R root:hadoop /opt/hadoop-2.7.3
# chmod -R 755 /opt/hadoop-2.7.3
SSH通信の設定
Hadoopはsshで通信を行って処理を実行するため、ユーザー毎にssh通信用の証明書を作成します。
# su - hdfs
# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# logout
# su - yarn
# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# logout
# su - mapred
# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
# logout
各ユーザーで自ノードにSSH通信が出来ることを確認します。
環境変数の設定
各ユーザーにHadoop実行のための環境変数を設定します。
hdfsユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_PID_DIR=/hdpool/run/hdfs
export HADOOP_GROUP=hadoop
yarnユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_PID_DIR=/hdpool/run/yarn
mapredユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export MAPRED_PID_DIR=/hdpool/run/mapred
sparkユーザーの$HOME/.profileに以下の環境変数を設定します。
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Hadoop環境の構築
Hadoop用ディレクトリの設定
Hadoopのデータ格納用のディレクトリを作成していきます。今後の運用を考えてZFSのファイルシステムとして作成します。
hdfsユーザー用ログファイルディレクトリを作成します。
# zfs create -p hdpool/log/hdfs
# chown hdfs:hadoop /hdpool/log/hdfs
yarnユーザー用ログファイルディレクトリを作成します。
# zfs create -p hdpool/log/yarn
# chown yarn:hadoop /hdpool/log/yarn
mapredユーザー用ログファイルディレクトリを作成します。
# zfs create -p hdpool/log/mapred
# chown mapred:hadoop /hdpool/log/mapred
NameNodeのメタデータ用ディレクトリを作成します。
# zfs create -p hdpool/data/1/dfs/nn
# chmod 700 /hdpool/data/1/dfs/nn
# chown -R hdfs:hadoop /hdpool/data/1/dfs/nn
NameNodeのデータブロック保管用ディレクトリを作成します。
# zfs create -p hdpool/data/1/dfs/dn
# chown -R hdfs:hadoop /hdpool/data/1/dfs/dn
yarnユーザーが使用するローカルデータディレクトリを作成します。
# zfs create -p hdpool/data/1/yarn/local
# zfs create -p hdpool/data/1/yarn/logs
# chown -R yarn:hadoop /hdpool/data/1/yarn/local
# chown -R yarn:hadoop /hdpool/data/1/yarn/logs
yarnユーザーが使用するランタイム用のディレクトリを作成します。
# zfs create -p hdpool/run/yarn
# chown yarn:hadoop /hdpool/run/yarn
# zfs create -p hdpool/run/hdfs
# chown hdfs:hadoop /hdpool/run/hdfs
# zfs create -p hdpool/run/mapred
# chown mapred:hadoop /hdpool/run/mapred
一時的なデータ使用のディレクトリを作成します。
# zfs create -p hdpool/tmp
以下のコマンドを実行しディレクトリが作成されていることを確認します。
# zfs list -r hdpool
以下のように表示されれば正常に作成されています。
NAME USED AVAIL REFER MOUNTPOINT
hdpool 5.33M 11.7G 352K /hdpool
hdpool/data 2.36M 11.7G 304K /hdpool/data
hdpool/data/1 2.06M 11.7G 320K /hdpool/data/1
hdpool/data/1/dfs 896K 11.7G 320K /hdpool/data/1/dfs
hdpool/data/1/dfs/dn 288K 11.7G 288K /hdpool/data/1/dfs/dn
hdpool/data/1/dfs/nn 288K 11.7G 288K /hdpool/data/1/dfs/nn
hdpool/data/1/yarn 896K 11.7G 320K /hdpool/data/1/yarn
hdpool/data/1/yarn/local 288K 11.7G 288K /hdpool/data/1/yarn/local
hdpool/data/1/yarn/logs 288K 11.7G 288K /hdpool/data/1/yarn/logs
hdpool/log 1.17M 11.7G 336K /hdpool/log
hdpool/log/hdfs 288K 11.7G 288K /hdpool/log/hdfs
hdpool/log/mapred 288K 11.7G 288K /hdpool/log/mapred
hdpool/log/yarn 288K 11.7G 288K /hdpool/log/yarn
hdpool/run 1.17M 11.7G 336K /hdpool/run
hdpool/run/hdfs 288K 11.7G 288K /hdpool/run/hdfs
hdpool/run/mapred 288K 11.7G 288K /hdpool/run/mapred
hdpool/run/yarn 288K 11.7G 288K /hdpool/run/yarn
hdpool/tmp 288K 11.7G 288K /hdpool/tmp
今回はZFSの機能を用いてログ領域の圧縮を行います。設定にもよりますが、ログの書き出しによりディスクが圧迫されることがあります。ディスクへの書き込み不可によってプロセスが異常終了するのを防ぐため、以下のコマンドでログ領域の圧縮を行っておきます。
# zfs set compression=lz4 hdpool/log
Hadoop環境設定ファイルの作成
Hadoopの構成ファイルのディレクトリ(/opt/hadoop/etc/hadoop)に移動します。
hadoop-env.shに以下を追加します。
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export JAVA_HOME=/usr/java
export HADOOP_LOG_DIR=/hdpool/log/hdfs
yarn-env.shに以下を追加します。
export JAVA_HOME=/usr/java
export YARN_LOG_DIR=/hdpool/log/yarn
export HADOOP_HOME=/opt/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
mapred-env.shに以下を追加します。
export JAVA_HOME=/usr/java
export HADOOP_MAPRED_LOG_DIR=/hdpool/log/mapred
export HADOOP_MAPRED_IDENT_STRING=mapred
slavesファイルを編集します。DataNodeの管理下に入るホスト名を記載します。
m10spark
core-site.xmlファイルを以下のように編集します。
mapred-site.xmlファイルを以下のように編集します。
yarn-site.xmlファイルを以下のように編集します。
hdfs-site.xmlファイルを以下のように編集します。
Hadoopプロセスの起動
※注意:以下のようなwarningが出力されますが、動作には影響ありませんので無視してください。
xx/xx/xx xx:xx:xx WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
まずHadoop ファイルシステムをフォーマットします。
# su - hdfs -c 'hdfs namenode -format'
以下のように表示されれば正常にフォーマットされています。
16/10/24 08:17:36 INFO common.Storage: Storage directory /hdpool/data/1/dfs/nn has been successfully formatted.
NameNodeを起動します。
# su - hdfs -c 'hadoop-daemon.sh start namenode'
NameNodeの起動を確認します。
# /usr/java/bin/jps | grep NameNode
以下のように表示されれば正常に起動されています。
25852 NameNode
ResourceManagerを起動します。
# su - yarn -c 'yarn-daemon.sh start resourcemanager'
ResourceManagerの起動を確認します。
# /usr/java/bin/jps | grep ResourceManager
以下のように表示されれば正常に起動されています。
25982 ResourceManager
DataNodeとNodeManagerを起動します。
# su - hdfs -c 'hadoop-daemon.sh start datanode'
# su - yarn -c 'yarn-daemon.sh start nodemanager'
DataNodeの起動を確認します。
# /usr/java/bin/jps | grep DataNode
以下のように表示されれば正常に起動されています。
26240 DataNode
NodeManagerの起動を確認します。
# /usr/java/bin/jps | grep NodeManager
以下のように表示されれば正常に起動されています。
26299 NodeManager
JobHistoryServerを起動します。
# su - mapred -c 'mr-jobhistory-daemon.sh start historyserver'
JobHistoryServerの起動を確認します。
# /usr/java/bin/jps | grep JobHistoryServer
以下のように表示されれば正常に起動されています。
26573 JobHistoryServer
Hadoop内のディレクトリ構成を設定します。
# (name-node1にhdfsでログインする。)
# hadoop fs -mkdir /tmp
# hadoop fs -chmod -R 1777 /tmp
# hadoop fs -mkdir /data
# hadoop fs -mkdir /data/history
# hadoop fs -chmod -R 1777 /data/history
# hadoop fs -chown yarn /data/history
# hadoop fs -mkdir /var
# hadoop fs -mkdir /var/log
# hadoop fs -mkdir /var/log/hadoop-yarn
# hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
# hadoop fs -mkdir /data/spark
# hadoop fs -chown spark /data/spark
以下のコマンドを実行し、すべてのノードからHadoop内のディレクトリ構成が見えることを確認します。
# su - hdfs -c 'hadoop fs -ls -R /'
以下が作成されていれば正常に実行されています。
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:32 /data
drwxrwxrwt - yarn hadoop 0 2016-10-25 07:26 /data/history
drwxr-xr-x - spark hadoop 0 2016-10-25 07:32 /data/spark
drwxrwxrwt - hdfs hadoop 0 2016-10-24 16:08 /tmp
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:29 /var
drwxr-xr-x - hdfs hadoop 0 2016-10-25 07:29 /var/log
drwxr-xr-x - yarn mapred 0 2016-10-25 07:29 /var/log/hadoop-yarn
動作確認
ブラウザーからhttp://<動作しているマシンのIPアドレス>:50070/にアクセスして以下のような画面が表示されれば正常に動作しています。
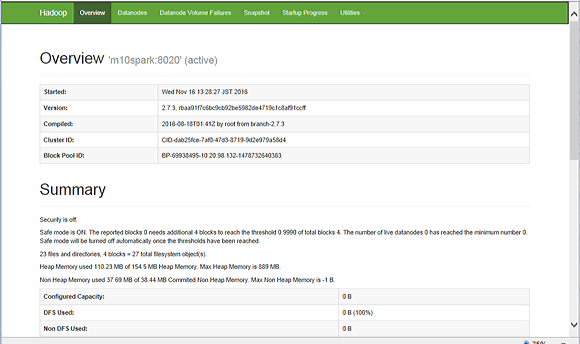
hadoopのサンプルプログラムを実行します。正常に終了すれば確認は終了です。
# su - spark
$ hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 20
Number of Maps = 10
Samples per Map = 20
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
16/11/16 13:47:08 INFO client.RMProxy: Connecting to ResourceManager at m10spark/10.20.98.122:8032
16/11/16 13:47:10 INFO input.FileInputFormat: Total input paths to process : 10
16/11/16 13:47:10 INFO mapreduce.JobSubmitter: number of splits:10
16/11/16 13:47:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1479271455092_0001
16/11/16 13:47:11 INFO impl.YarnClientImpl: Submitted application application_1479271455092_0001
16/11/16 13:47:11 INFO mapreduce.Job: The url to track the job: http://m10spark:8088/proxy/application_1479271455092_0001/
16/11/16 13:47:11 INFO mapreduce.Job: Running job: job_1479271455092_0001
16/11/16 13:47:25 INFO mapreduce.Job: Job job_1479271455092_0001 running in uber mode : false
16/11/16 13:47:25 INFO mapreduce.Job: map 0% reduce 0%
16/11/16 13:47:51 INFO mapreduce.Job: map 10% reduce 0%
16/11/16 13:47:53 INFO mapreduce.Job: map 20% reduce 0%
16/11/16 13:47:54 INFO mapreduce.Job: map 60% reduce 0%
16/11/16 13:48:14 INFO mapreduce.Job: map 80% reduce 0%
16/11/16 13:48:15 INFO mapreduce.Job: map 100% reduce 0%
16/11/16 13:48:17 INFO mapreduce.Job: map 100% reduce 100%
16/11/16 13:48:18 INFO mapreduce.Job: Job job_1479271455092_0001 completed successfully
16/11/16 13:48:18 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=1311574
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2590
HDFS: Number of bytes written=215
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=241698
Total time spent by all reduces in occupied slots (ms)=20138
Total time spent by all map tasks (ms)=241698
Total time spent by all reduce tasks (ms)=20138
Total vcore-milliseconds taken by all map tasks=241698
Total vcore-milliseconds taken by all reduce tasks=20138
Total megabyte-milliseconds taken by all map tasks=247498752
Total megabyte-milliseconds taken by all reduce tasks=20621312
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1410
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=2760
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=2024275968
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 69.642 seconds
Estimated value of Pi is 3.12000000000000000000
以上で、Hadoopのシングルノード環境が構築できました。
次回はHadoopのクラスタ構成の構築を行います。