![]()
Archived content
NOTE: this is an archived page and the content is likely to be out of date.
SPARC64™ carry forward mainframe high reliability technology
SPARC64 series processors incorporated in SPARC Enterprise Mission Critical models, carry forward RAS (Reliability, Availability and Serviceability) technologies developed and proven on enterprise-class mainframes. SPARC Enterprise high reliability is achieved by error detection and recovery mechanisms across all processor circuits to avoid system failures caused by processor errors.
All SPARC64 series processors have mechanisms that assure data transmission and storage within the processor; not only in cache memory but in Arithmetic and Logic Units (ALU), and registers, as well. Processor errors are recovered by ECC data correction processing and instruction retry technology. Even when unrecoverable errors occur the processor doesn't stop. It just dynamically downgrades affected units of CPU core or cache memory and continues. Each processor also continually records all error information, so any error cause can be swiftly detected.
SPARC64 VI, VII, and VII+ with RAS functions on par with mainframe processors, provide the utmost in highly reliable systems.

| Error detection | Error correction | Downgrade Capability | Records | |
|---|---|---|---|---|
| Level1 cache | Redundancy + parity , ECC | Retry, ECC | Dynamic way downgrade (*2) | Error occurrence history |
| Level2 cache | ECC | ECC | ||
| Arithmetic and Logic Units | Parity (*1)
|
Hardware instruction retry | Dynamic core downgrade | |
| Registers | Parity (*1)
ECC (*3) |
ECC(*3)
Hardware instruction retry |
*1: Parity error is corrected by hardware instruction retry function.
*2: A way is a unit of cache memory. SPARC64™ VI/VII/VII+ Level1 cache memory consists of 2 ways, Level2 cache memory consists of 12 ways.
*3: Available for SPARC64™ VII/VII+
 Please notice that above figure is shown solely for the purpose of explaining data protection mechanism, not for displaying actual CPU chipfigure.
Please notice that above figure is shown solely for the purpose of explaining data protection mechanism, not for displaying actual CPU chipfigure.
Please notice that above figure is shown solely for the purpose of explaining data protection mechanism, not for displaying actual CPU chipfigure.
Extensive data protection improves business continuity
Data protection mechanisms in Cache memory
Although infrequent and often random, most processor circuit failures occur in Cache memory(*4). These typically cause a server down or performance slow-down. So cache memory data protection mechanisms are essential for enterprise systems.
The instruction handling components of level1 cache memory are protected by redundancy and parity mechanisms, while the data handling components use ECC. In level2 cache, both instructions and data are protected by ECC. As a result all one-bit errors in cache memory can be detected and corrected.
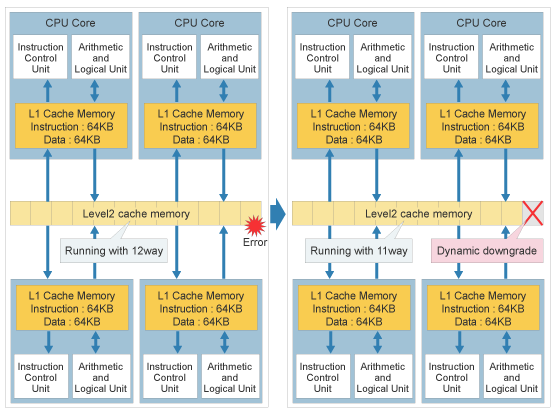
If one-bit errors occur too frequently, cache memory dynamically performs a step downgrade, one way unit at a time. Even if a level2 cache way fails, the remaining 11 ways (out of 12) continue operation. In the rare event that all cache ways have to be downgraded, the specific CPU chip is then automatically isolated from production.
These mechanisms ensure system continuity, system protection, remove effects of infrequent failure, and minimize any resulting performance slowdown. Similar cache failures in other vendor's processors, reduce system availability and performance. Typically their entire system has to be rebooted, downgraded, or the whole CPU chip is immediately made unavailable following such failure.
*4: Infrequent errors occur at random points causing data error. Referred to as “soft errors” they are caused by radiation, magnetic interference and heat.
SPARC64™ VII/VII+
SPARC64™ VI
*5 Infrequent failure is temporary data error at arbitrary point, also referred to as soft error. Infrequent failure happens due to external physical influences such as radiation, electromagnetic wave and heat.
*6 For SPARC64 VI, 6 MB level2 cache memory has 12 ways, 5 MB has 10 ways.
All SPARC64 VII/VII+ processors have 12 ways.
Data protection mechanism on ALU and Registers
SPARC64 VI/VII/VII+ Arithmetic and Logic Units (ALU) and registers protect data using parity checking mechanisms. Each ALU processes instructions, while registers temporally store data for input to the ALU.
Registers in SPARC64 VI/VII/VII+ consist of highly reliable circuits. All one bit errors are detected by parity check. Following any error detection, data is re-read from cache and processed again. Furthermore, SPARC64 VII/VII+ enhanced reliability with ECC protection of integer registers.
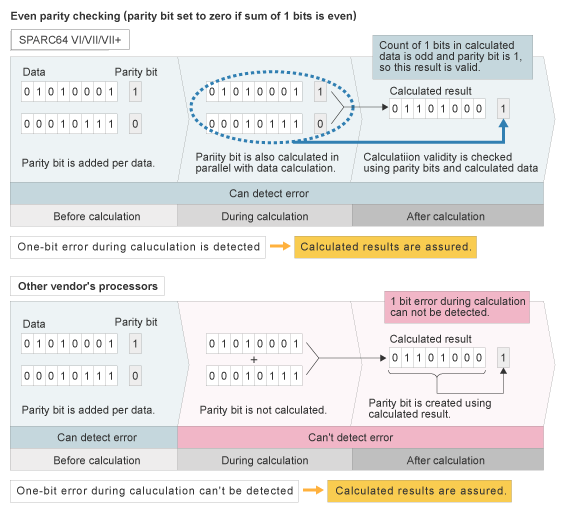
SPARC64 VI/VII/VII+ validates parity values to check if input data has been processed in ALU without data corruption. This sophisticated level of checking means any one-bit error found during calculation is detected. After error detection, all data, in relevant ALU and registers, is cleared. The data is then re-read from level1 cache and the instruction processed again.
Typically with other vendor's processors one-bit errors in ALU are not detected. Their processor architecture doesn't pass parity bits to the ALU from the registers. Nor are parity bits associated with ALU calculation results. With parity checking only prior to ALU input and after ALU output, data corruption occurring in the ALU itself can't be detected.
CPU core downgrade
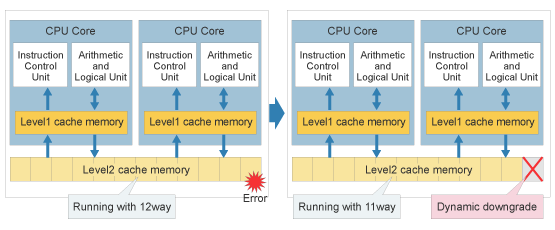
Following detection of an unrecoverable CPU error, the faulty core is isolated and the remaining normal cores maintain processing availability.
History records all processor operations
A history circuit mechanism in SPARC64 VI/VII/VII+ automatically records all processor operations. This history circuit is used for processor fault investigation and processor reliability improvement.
Just like a flight recorder, each history circuit maintains regular records (without software intervention or effect on processor operation). So any error causing process can be detected. The history circuit is the key to fast and exact error cause detection.