
超高速検索がビジネスを変革する!データベースの高速検索エンジン
Text Navigator®
テキストナビゲータ

Text Navigator®とは
増大化し続ける企業内の情報の管理。このような課題はありませんか?
- 情報の増加に伴ないデータ構造やデータ相互の関連性の複雑化が進み、レスポンスの劣化などの問題が
- RDBMSの管理対象にテキストなどの非定型データが大量に入り込み、同様の問題が
- 情報の爆発的増加に対して、RDBMSが所与のパフォーマンスを発揮しきれなくなりつつある
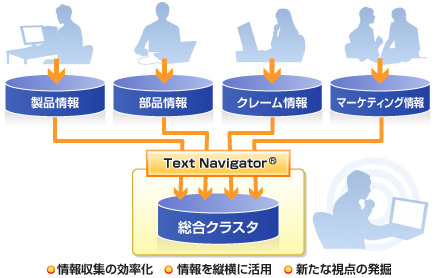
このような課題には、索引を整理・管理し検索を高速化するツールが不可欠です。Text Navigatorは、データベースの高速検索を実現するアプリケーション組込み型のオープンサーバ製品です。日々の活動に伴なって増大化し続ける企業内の情報の管理に有効です。Text Navigatorは、柔軟性の高いインターフェース(API)を提供します。これを使用することにより、Oracle,Informix,Sybase,Microsoft SQL Serverなど、一般的なRDBMSとの連携をサーバレベルで確立することが可能です。また、複数の既存データベースをそのままに統合的に管理し、横断的検索を行うことができます。
大規模データを扱うアプリケーションへのプリバンドル実績もございます。
お取り扱いをご希望の企業様は担当窓口までご相談下さい。
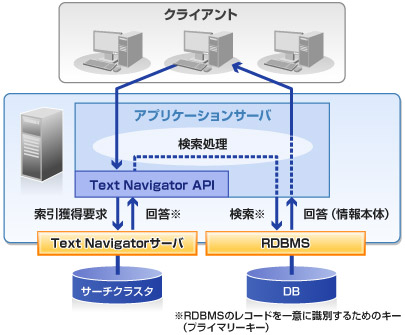
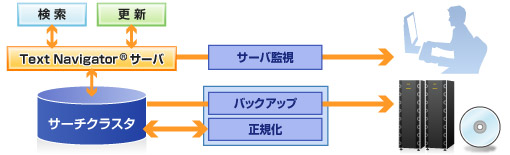
Text Navigator®の概念図
Text Navigator®の特長
 特長1
特長1膨大化・分散化した情報を一括管理、どの情報でもどこからでも同じ操作で高速検索
 特長2
特長2既存業務やシステム環境への与える影響が少なく、低コストで早期に稼動
 特長3
特長3リアルタイム更新による大規模データベースの24時間ノンストップ運転の実現
 特長4
特長4フルサーチの全文検索と用語通覧機能を実現するキーワード検索の併用が可能
機能
Text Navigatorは、当社独自の高速・省資源の方式で索引情報(サーチクラスタ)のみを保持します。検索の際にText Navigatorで対象を絞り込み、獲得した索引情報でデータベースから情報本体を取得することにより、テキスト情報の超高速検索を実現します。
データベースを直接検索する場合との比較
20万件と100万件の図書データの入ったデータベースから、書名に「政治」と「経済」の入っている図書を検索した場合の所要時間を計測した結果です。
| データ総数 | ヒット件数 | DB直接検索の 所要時間 |
Text Navigatorを 利用した場合の所要時間 |
参考: Text Navigatorの 索引取得所要時間 |
|---|---|---|---|---|
| 20万件 | 97件 | 13.423秒 | 0.320秒 | 0.031秒 |
| 100万件 | 236件 | 47.127秒 | 0.762秒 | 0.040秒 |
[書名]="政治" and [書名]="経済"
計測方法:同一マシンにおけるクライアント / サーバ構成でのレスポンス
| CPU | PentiumIII 1GHz |
| メモリ | 512MB |
| OS | Linux |
| RDBMS | Oracle9i |
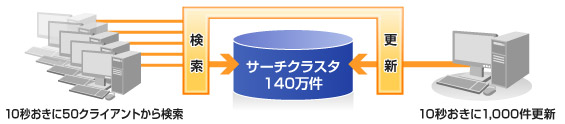
Text Navigatorは、サーチクラスタをリアルタイム更新(レコードの追加・更新・削除)できます。更新による検索への影響は最小限に抑えており、更新中の検索者にストレスを与えません。
日中のオンライン更新(通常業務)を想定した実測値
登録件数140万件のサーチクラスタに対し、10秒おきに1,000件の更新を繰り返し、あわせて10秒おきに50クライアントからの検索を繰り返すという処理を1時間34分16秒間行った結果です。
| 計測時間 | 実処理時間(注意1) | 1件あたり | |
|---|---|---|---|
| 更新 1,000件 | 1時間34分16秒 | 11分06秒 | 0.66秒 |
| 検索(更新中) | 28秒 | 0.06秒 |
(注意1)実処理時間-waitを除いたText Navigatorの実行時間
(1) Happiness®/BASE内蔵
Text Navigatorは、日本語自然文の解析を行う汎用ソフトウェアHappiness/BASEを内蔵し、日本語自然文から意味ある「言葉」としてキーワードを自動抽出します。
抽出したキーワードは、意味のある「言葉」の最小単位(「語基」と呼びます)の組み合わせとして独自の形式に加工し、管理します。これに「語基」の前方一致、後方一致、任意一致などの一致条件を組み合わせることにより、一般的な「形態素解析方式」よりはるかにきめ細かく、漏れの少ない検索を実現します。
| 一般的な形態素解析方式の漏れ発生例 |
|---|
| 研究 総務部 |
(2) 形態素解析方式とNグラム方式の両方を搭載
さらにText NavigatorはNグラム方式を搭載しています。Happiness/BASEによるきめ細かい処理にNグラム方式を加えることにより、最高品質の日本語処理を実現します。方式は、データにより選択可能で、同一フィールドに対して併用することもできます。
| 形態素解析方式の特長 |
|
|---|
| Nグラム方式の特長 |
|
|---|
| Nグラム方式のノイズ例 |
東京都 輸出産業 |
|---|
Text Navigatorは、サーチクラスタに格納された情報を元に用語の通覧を表示できます。元のテキスト情報に含まれる用語を一覧表示するなど、検索支援はもとより、文書情報の傾向分析など、さまざまな用途に知的活用することができます。 通覧方法はいろいろありますが、以下はKWIC通覧(位置付け語(例:政治)を中心にその語基を持つ索引語を一覧)の例です。
| 政治 | ||
|---|---|---|
| 伝統的 | 政治 | |
| 政治 | システム | |
| 政治 | 改革 | |
| 参院 | 政治 | 改革関連法案 |
| 政治 | 改革特別委員会 | |
| 政治 | 改革法案 | |
| 政治 | 改革法案審議 | |
| 国民 | 政治 | 協会 |
Text Navigatorは、コンパクトなシステムです。
当社独自の高速検索アルゴリズムで、CPU資源を圧迫しません。
Text Navigatorは、大規模データと長期間に渡るノンストップ運用に対応しています。
サーチクラスタには、2G件(≒21.4億件)まで収録可能。
また、サーバ全体の稼動状況やクライアントセッション単位の状況監視、サーチクラスタのバックアップ及び正規化(更新によって細分化されたサーチクラスタ内部の再配置(デフラグ))を実現しています。
動作環境
対応OSWindows版 Windows 10/11
Windows Server 2016/2019/2022
※サーバ機能はIntel x64アーキテクチャのみに対応、クライアント開発キットはx64/x86に対応Linux版 Red Hat Enterprise Linux 7/8/9
※サーバ機能はIntel x64アーキテクチャのみに対応、クライアント開発キットはx64/x86に対応推奨環境サーバ CPU:3GHz(4コア) メモリ:4GB 以上推奨 クライアント 各OSの推奨スペック以上 クライアント Application Program InterfaceC/C++、Java、Microsoft.NET Framework(C#、VB.net、C++等) Unicodeサポート
検索ファシリティ サーチクラスタのコード系、及びText Navigator APIで使用するコード系としてUTF-8をサポート 日本語解析
ファシリティ
(Happiness/BASE)利用者辞書のコード系、及びBASEエージェントで使用するコード系としてUnicode(UTF-16、UTF-8)をサポート 注)記載されている製品・サービス名、会社名及びロゴは、各社の商標または登録商標です。
検索ファシリティ
コンポーネント 説明 Text Navigatorサーバ 検索・通覧エンジン本体(サーバプログラム) Text Navigator API アプリケーションが使用するクライアントAPIライブラリ Text Navigator Java API Text Navigator APIと同等の機能を提供する、Javaクラスライブラリ Text Navigator .NET framework API Text Navigator APIと同等の機能を提供する、Microsoft .NET framework向けクラスライブラリ クラスタ創成プログラム 索引情報の元となるテキスト形式ファイルから、サーバで扱うためのサーチクラスタを作成するバッチプログラム クラスタ正規化プログラム 更新を重ねたサーチクラスタを正規化し、論理的に同一な新しいサーチクラスタを作成するバッチプログラム クラスタバックアップ
指示プログラム起動中のText Navigatorサーバに対し、サーチクラスタのバックアップを指示するバッチプログラム サーバモニタリングツール 起動中のText Navigatorサーバの稼働状況を監視するツール シノニム辞書創成プログラム テキスト形式ファイルから、シノニム検索用の辞書を作成するバッチプログラム クラスタ一括更新プログラム 既存のサーチクラスタに対して、複数レコードを一括して追加・更新・削除するためのバッチプログラム コマンドライン・クライアント Text Navigator APIで提供される全ての機能が使用できる、コマンドライン・インターフェース・アプリケーション 日本語解析ファシリティ(Happiness®/BASE)
コンポーネント 説明 BASEサーバ 独立動作する基本処理エンジン BASEクライアント アプリケーションが使用する、会話処理方式のクライアントAPIライブラリ BASEJavaクライアント BASEクライアントと同等の機能を提供する、Javaクラスライブラリ BASE .NET framework API BASEクライアントと同等の機能を提供する、Microsoft .NET framework向けクラスライブラリ BASEエージェント アプリケーションが使用する、一括処理方式のAPIライブラリ 辞書ツール 辞書の管理等に有効なサービス・プログラム
(辞書マージ、用語抽出、処理結果比較、用語登録効果確認)システム基本辞書 約14万語の辞書用語(Unicode) 標準基本ルール 処理上ルールの定義体 異体字変換表 異なる字形を持つ文字を統一する定義体(JIS2004の追加文字を含む) 国際異体字変換表 中国・台湾の文字を含む異体字変換表 ローマ字ルール ローマ字文を生成するルールの定義体
(日本式、訓令式、ヘボン式、英米標準)活用判別表 活用形判別ルートの定義体 特定用途向け辞書 特定の用途に有効な標準利用者辞書
タイトルKWIC用辞書/漢数字読み下し用辞書/名字辞書