
情報検索に“知恵”を吹き込む!日本語形態素解析エンジン
Happiness®/BASE5
ハピネス ベース

Happiness®/BASE5とは
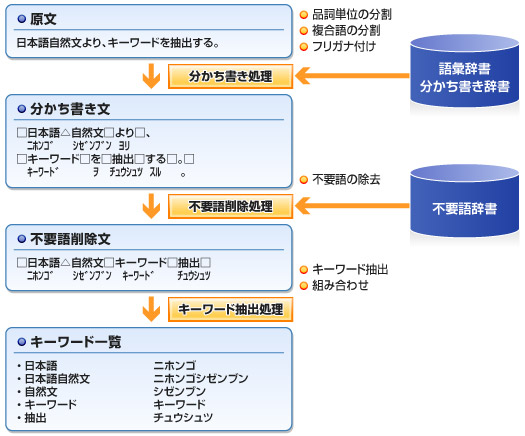
Happinessは、日本語自然文の解析を行う汎用ソフトウェア製品です。利用者は自然言語処理の基幹技術であるHappinessを用いることにより、情報検索や自動翻訳、言語調査などの分野に幅広く活用することが出来ます。特に図書館の目録作成処理におけるアクセス・ポイント(カナ分かち書き)の生成には、なくてはならない機能となっています。
また、Happinessは1983年から販売されている、日本語自然文解析のロングセラー製品です。日本語処理に特有の分かち書き、キーワード抽出、ヨミガナ付け、ローマ字生成、異体字変換等、情報検索や自動翻訳、目録作成、言語調査などの分野で幅広く活用されています。
注)Happiness®/BASE5は、JIS X 0213:2004(JIS2004)に対応したHappiness®シリーズの最新版です。
導入実績
図書館、博物館、資料館
- 蔵書管理・書誌作成支援
- 遡及処理支援(キーワード生成・ふりがな付け・字種変換・異体字変換など)
- 図書検索システム向け索引作成

情報検索
- 統合・メタデータベースの索引作成
- 検索ナビゲーションシステム
- 検索キーワードのログ分析

日本語研究者
- 同義語辞書・シソーラスの作成支援
- 文献情報分析(用語出現頻度分析)
- 新聞記事、Web、ニュース原稿のキーワードによる傾向分析
- 翻訳・要約など日本語処理システム

Happiness®/BASE5の機能
クライアント/サーバ間機能利用者辞書指定 システム基本辞書に加えて「利用者基本辞書」「利用者辞書」が指定できます。 コード系変換 原文の文字(SJIS/EUC/Unicode(UTF-16,UTF-8))を自動的にコード変換します。 異体字変換表指定 国際異体字変換表や利用者独自の異体字変換表を指定することができます。 ローマ字ルール ローマ字化するためのルールを指定することができます。 利用者外字指定 SJIS,EUCの利用者外字を指定することができます。 分かち書き機能異体字変換 異体字は親字に変換し、辞書引きを確実に行います。 長音代替機能 ルールの指定によりハイフンなどを長音と見なします。 分かち書きパス機能 ルールに指定した記号に挟まれた部分の分かち書きを迂回します。 連単語解釈 連続する熟語間の強弱を判定して最適な分割位置を決定します。 キーワード抽出機能不要語削除処理 分かち書き結果より不要な語を除去してキーワード候補を生成します。 語基組み合わせ 語基の組み合わせによりキーワードを生成します。 組み合わせ範囲 語基を組み合わせる際の語基数の範囲が指定できます。 組み合わせ時期 語基組み合わせの時期として、削除後組み合わせ・削除前組み合わせ・削除後連結組み合わせのいずれかが選択できます。 組み合わせ方式 語基組み合わせの方法として、標準組み合わせ・トランケーション組み合わせがあります。 採用単位 短単位(前後に名詞のない独立した語基)・長単位(熟語のつながっている全体)の採用可否を指定することができます。 組み合わせ迂回 語基組み合わせを迂回することができます。 不要語接続 不要語を除去するのではなく、直前の有用語に接続する結果を生成することができます。 フリガナ付け機能音訓読み 辞書にない熟語でも文字の前後を判断して音訓を決定します。 解釈フリガナ 上記判別を詳細に行う指定が可能です。 連濁 熟語が続く場合、後続する熟語の先頭の読みを濁音とする指定が可能です。 処理結果変換機能ヨミガナ文生成 助詞(は、へ、を)の変換や四つガナ(じ、ぢ、ず、づ)統一等を行ったヨミガナを生成します。 ローマ字文生成 指定のローマ字ルールに従い、フリガナ文又はヨミガナ文からローマ字文を生成します。カナ文字列を入力し(分かち書きを行わずに)直接ローマ字文を生成する事も可能です。 異体字変換 指定の異体字変換表を用いて、異体字を親字に統一します。 字種変換 指定により全角半角変換、カナ統一、大文字小文字統一などを行います。 原文通知 原文自体に異体字変換や字種変換を施した結果の通知を行います。 用語管理機能用語の種類 語彙辞書・副語彙辞書・分かち書き辞書・不要語辞書の4種類があります。 用語タイプ 用語の扱いを示す情報として11個のタイプがあります。 用語オプション 用語に対する特別な索引方法や処理の指定として、(1)分割指示(2)活用形(3)熟語化(4)助数詞(5)小数判別(6)接尾辞解釈要(7)見出し位置変更 があります。 音訓読み 漢字1文字ごとに音読みと訓読みを与えることができます。 解釈フリガナ 漢字1文字の前後を判別する木目細かなフリガナ付けが指示できます。 連濁 熟語が続く場合に連濁させることを指示することができます。 第2フリガナ 用語の分かち書き結果によって異なる読みを指示することができます。 処理結果通知機能取り出し内容 (1)分かち書き結果(2)不要語削除結果(3)不要語接続結果(4)キーワード結果(5)原文 のいずれか(複数可)を得ることができます。 通知形式 上記結果について (1)漢字のままの文章(漢字文)(2)異体字変換した漢字文(3)フリガナ文(4)ヨミガナ文(5)フリガナからのローマ字文(6)ヨミガナからのローマ字文 の通知形式が選べます。(原文の場合は(1)(2)のみ)また原文を除き(1)~(3)については(a)組合わせ可能単語同士を特別な空白で切断する(b)切断する空白は統一する、のいずれかを指定する事ができます。更に漢字と単語とフリガナを組で通知するテーブル形式もあります。 格納方法 通知領域への格納方法として(1)単語の泣き別れを許す(2)空白を空けない(3)単語の泣き別れを禁止する(4)処理結果を格納したポインタを通知する、のいずれかを選択することができます。 字種変換 文章形式の場合、(1)全角統一/半角変換(2)ひらがな統一/カタカナ変換(3)大文字統一/小文字統一を(1)~(3)の組み合わせで指定することができます。 辞書ツール辞書マージ 利用者辞書を翻訳し利用者基本辞書を作成します。 用語抽出 利用者基本辞書より指定した条件に合致した用語を取り出します。 処理結果比較 サンプルの原文を異なる条件(利用者辞書や利用者基本ルール)で処理した結果を比較します。 用語登録効果確認 利用者辞書用語の登録とその効果確認を会話型で行います。
動作環境
対応OSWindows版 Windows 10/11
Windows Server 2016/2019/2022
※サーバ機能はIntel x64アーキテクチャのみに対応、クライアント開発キットはx64/x86に対応Linux版 Red Hat Enterprise Linux 7/8/9
※サーバ機能はIntel x64アーキテクチャのみに対応、クライアント開発キットはx64/x86に対応推奨環境サーバ CPU:3GHz(4コア) メモリ:4GB 以上推奨 クライアント 各OSの推奨スペック以上 クライアント Application Program InterfaceC/C++、Java、Microsoft.NET Framework(C#、VB.net、C++等) 注)記載されている製品・サービス名、会社名及びロゴは、各社の商標または登録商標です。
Happiness®/BASE5のシステム構成
コンポーネント 説明 BASEサーバ 独立動作する基本処理エンジン BASEクライアント クライアント/サーバ方式を使用し、複数のアプリケーションにサービス可能なAPIライブラリ BASE Java クライアント BASEクライアントと同等の機能を提供する、Javaクラスライブラリ BASE .NET
framework APIBASEクライアントと同等の機能を提供する、Microsoft .NET framework向けクラスライブラリ BASEエージェント 単一のアプリケーションをサービス対象とした、高速(非通信)の組み込み型APIライブラリ 辞書ツール 辞書の管理等に有効なサービスプログラム(辞書マージ、用語抽出、処理結果比較、用語登録効果確認) システム基本辞書 約14万語の辞書用語(Unicode) 標準基本ルール 処理上ルールの定義体 異体字変換表 異なる字形を持つ文字を統一する定義体 国際異体字変換表 中国・台湾の文字を含む異体字変換表 ローマ字ルール ローマ字文を生成するルールの定義体
(日本式、訓令式、ヘボン式、英米標準)活用判別表 活用形判別ルートの定義体 特定用途向け辞書 特定の用途に有効な標準利用者辞書
タイトルKWIC用辞書 / 漢数字読み下し用辞書 / 名字辞書