![]()
Solaris活用ナビ ~Practical Tips for SPARC~
第3回:SPARC Servers / Solaris上でHadoopとSparkを使ってみよう(Spark環境構築編)
2017年11月28日
第1回、第2回とHadoopの環境構築を行ってきました。
今回は第2回で作成したHadoopのクラスタ環境を利用して、Sparkのクラスタ環境を構築していきます。
SPARC Servers / SolarisでSparkを動作させる利点
Sparkはクラスタを構築することで分散処理は可能ですが、その特長であるインメモリ処理を十分に活かすには、ひとつのマシンに搭載できるメモリ量が多くなければいけません。
SPARC Serversでは安価に大容量メモリが搭載でき、ビルディングブロックを利用することでさらに大容量のメモリを利用することが可能です。
構成について
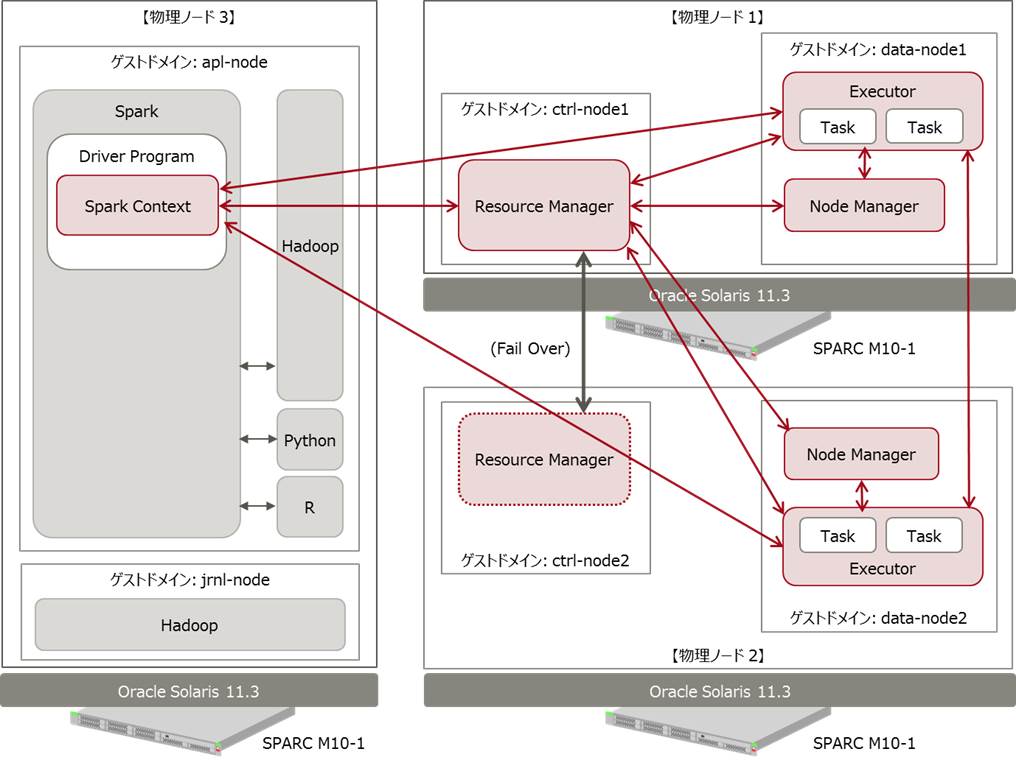
Sparkのクラスタを実現するにはいくつかの方法がありますが、今回はもっともよく利用されているHadoopのYarnを使用します。そのため、環境は第2回で作成したHadoopのクラスタ環境にSpark用のゲストドメイン環境を追加する形をとります。(※ZoneはSparkのPythonインターフェースの使用時に問題が起きるため使用しないようにしてください。)
構成図では物理ノード3に追加していますが、別の物理ノードでもかまいません。
なお、シングル環境で動作させることも可能です。その場合には、第1回で構築したHadoopシングル構成環境にSpark環境をインストールし各種設定を行ってください。
図中の各処理の役割は以下のようになっています。
| Driver Program | アプリケーション本体であり、分散処理時にマスターの役割を行います。Spark環境とのやり取りを行うSpark Contextオブジェクトを生成します。 |
| Executor | 分散処理を実際に行うプロセスです。計算処理の最小単位であるTaskを実行します。Executorを実行するノードのことをワーカーノードと呼びます。 |
| Resource Manager | クラスタマネージャーとして動作し、Driver Programからのリクエストをワーカーノードに割り当てます。障害時にはctrl-node2にFail Overするようになっています。(第2回の記事を参照) |
| Node Manager | Resource Managerと通信し、必要な数のExecutorを起動します。 |
ソフトとしてはSparkの他にRをインストールします。Oracle社がコンパイル済みのSPARC版のRを配布していますが、折角なので今回はソースからコンパイルする方法をとります。その際、SPARC64Xチップに最適化を施すことで高速な実行形式を生成します。Rのインストールで必要となるliblzmaとGNUのlibiconvも一緒にインストールします。
Sparkのバージョンは2.1.0以降を使用してください。それ以前のバージョンではSPARCチップでの動作で不具合が発生します。
確認したOS/ソフトのバージョンは基本的に第2回までと同様です。
- サーバ:SPARC M10-1
- OS:Oracle Solaris11.3 SRU 10.7
- Java:jdk 1.8.0_102
- Hadoop:2.7.3
- Spark:2.1.0
- R:3.2.5
- libiconv:1.1.4
- liblzma:5.2.2
- Oracle Developer Studio:12.5
仮想環境の構築
ゲストドメインの作成
apl-nodeという名前で任意の物理ノードにゲストドメインを追加します。
メモリは可能な限り割り当てます。
必要なパッケージのインストール
SparkはPythonのインターフェースも持っているためpython関連のパッケージもインストールします。Solaris11.3にはPython2系とPython3系がありますが、今回はPython2系(2.7.9)を使用します。Sparkのサンプルでも使用されているnumpyなどのライブラリモジュールは必ずOSのリポジトリからインストールしてください。pipを使用してインターネット経由でインストールした場合、ライブラリの不整合が発生する場合があります。関連するパッケージもインストールされます。
Oracle Developer Studioのモジュールの一部がOSのリポジトリと共に配布されるようになっているので、それらのパッケージもインストールします。
# pkg install developer/java/jdk-7
# pkg install runtime/python-27
# pkg install library/python/*27
# pkg install developer-studio-utilities
/etc/hostsの編集
/etc/hostsを編集します。関連するノードのIPアドレスをすべて記載します。以前に作成したノードの/etc/hostsにもapl-nodeの情報を追加しておきます。
::1 localhost
127.0.0.1 localhost loghost
xxx.xxx.xxx.xxx apl-node1 apl-node.local
xxx.xxx.xxx.xxx ctrl-node1
xxx.xxx.xxx.xxx ctrl-node2
xxx.xxx.xxx.xxx jrnl-node
xxx.xxx.xxx.xxx data-node1
xxx.xxx.xxx.xxx data-node2
Spark/Hadoop用ユーザー/グループの追加
hadoop実行用グループID(hadoop)の作成
# groupadd -g 200 hadoop
MapReduceのジョブ実行用ユーザーの作成及びパスワードの設定
# useradd -u 101 -m -g hadoop spark
# passwd spark
必要ソフトウェアのインストール
Oracle Developer Studioのインストール
Oracle Developer Studioをダウンロードし、インストールします。
インストールの詳細はマニュアルを参照してください。
Hadoopのインストール
Hadoopをダウンロードし、インストールするノードに転送します。
Hadoopをインストールします。
# cd /opt
#
# ln -s hadoop-2.7.3 hadoop
Hadoopのオーナー/パーミッションを変更します。
# chown -R root:hadoop /opt/hadoop-2.7.3
# chmod -R 755 /opt/hadoop-2.7.3
liblzmaとlibiconvのインストール
Rをインストールする前にliblzmaとGNUのlibiconvをインストールします。Solarisには独自のlzmaとiconvが付属していますが、これを使うとRのコンパイルが失敗します。そのため追加でインストールしたものを優先的に使用するようにします。
liblzmaをダウンロードし、インストールするノードに転送し解凍します。
64bit環境でコンパイルするため、環境変数CFLAGSに-m64を指定し、congiureを実行します。
# cd xz-5.2.2
# export CFLAGS="-m64"
# ./configure
特にエラーが表示されなければmake installを実行します。
# make install
/usr/local/includeにlzma.hが、/usr/local/libにliblzma.so.5.2.2が存在することを確認します。またliblzma.so.5.2.2にliblzma.so.5とliblzma.soがシンボリックリンクで結ばれていることを確認してください。
# cd /usr/local/include
# ls -l lzma.h
-rw-r--r-- 1 root root 9737 10月 10日 08:18 lzma.h
# cd /usr/local/lib
# ls -l liblzma*
-rw-r--r-- 1 root root 579480 10月 10日 08:18 liblzma.a
-rwxr-xr-x 1 root root 949 10月 10日 08:18 liblzma.la
lrwxrwxrwx 1 root root 16 10月 10日 08:18 liblzma.so -> liblzma.so.5.2.2
lrwxrwxrwx 1 root root 16 10月 10日 08:18 liblzma.so.5 -> liblzma.so.5.2.2
-rwxr-xr-x 1 root root 421608 10月 10日 08:18 liblzma.so.5.2.2
次にgnuiconvをダウンロードし、インストールするノードに転送します。
同様に環境変数CFLAGSに-m64を指定し、congiureを実行します。
# cd libiconv-1.14
# export CFLAGS="-m64"
# ./configure
特にエラーが表示されなければmake installを実行します。
# make install
/usr/local/includeにiconv.hが、/usr/local/libにlibiconv.so.2.5.1が存在することを確認します。またlibiconv.so.2.5.1にlibiconv.so.2とlibiconv.soがシンボリックリンクで結ばれていることを確認してください。
# cd /usr/local/include
# ls -l iconv.h
-rw-r--r-- 1 root root 9343 7月 8日 14:06 iconv.h
# cd /usr/local/lib
# ls -l libiconv*
-rw-r--r-- 1 root root 929 10月 2日 14:54 libiconv.la
lrwxrwxrwx 1 root root 17 10月 2日 14:54 libiconv.so -> libiconv.so.2.5.1
lrwxrwxrwx 1 root root 17 10月 2日 14:54 libiconv.so.2 -> libiconv.so.2.5.1
-rwxr-xr-x 1 root root 1075256 10月 2日 14:54 libiconv.so.2.5.1
Rのインストール
Rをダウンロードし、インストールするノードに転送します。
まずは作業用のディレクトリにアーカイブを解凍し、R-3.2.5にcd します。
コンパイル用の環境変数を設定します。この環境変数の中でSPARC64 Xチップへの最適化を行うコンパイルオプションを指定します。RはC, C++, Fortranの言語が混在していますので、それぞれのコンパイラとリンカー向けに環境変数を指定する必要があります。
この中で-xtargetにチップの種類を指定します。SPARC64 X+の場合はsparc64xplus、SPARC64 Xの場合はsparc64xを指定してください。その他のコンパイルオプションの詳しい説明はOracle Developer Studioのマニュアルを参照してください。
# export CFLAGS="-m64 -xO5 -fma=fused -xlibmieee -xlibmil -xmemalign=8s -xtarget=sparc64xplus -xvector=simd,lib -xpagesize=4M"
# export CC="cc -std=c99"
# export FFLAGS="-m64 -xO5 -fma=fused -xlibmil -dalign -xtarget=sparc64xplus -xvector=simd,lib -xpagesize=4M"
# export F77="f95"
# export CXXFLAGS="-m64 -xO5 -fma=fused -xlibmil -xmemalign=8s -xtarget=sparc64xplus -xvector=simd,lib -xpagesize=4M"
# export CXX="CC -library=stlport4"
# export FC="f95"
# export FCFLAGS=$FFLAGS
# export FCLIBS=""
# export LDFLAGS="-m64 -xO5 -xmemalign=8s -xvector=simd,lib -xpagesize=4M -L/usr/local/lib/sparcv9"
以下は実行時に必要となる環境変数の設定です。
# export R_LD_LIBRARY_PATH="/usr/local/lib"
# export JAVA_HOME=/usr/java
# export LD_LIBRARY_PATH_64=/usr/local/lib:/opt/R/lib/R/lib
以下の設定はコンパイル時のみ必要になります。
# export LD_LIBRARY_PATH_64=/usr/local/lib:`pwd`/lib
次にconfigureを実行するのですが以下のオプション指定が必要になります。
| --prefix=/opt/R-3.2.5 | コンパイル後に/opt/R-3.2.5にインストールします。 |
| --with-ICU=no | ICUライブラリを使用しません。 |
| --enable-R-shlib=yes | Rのライブラリを動的リンクオブジェクトとします。 |
| --with-blas='-library=sunperf' | BLASライブラリにSun Performance Libraryを使用します。 |
| --with-lapack='-library=sunperf' | LAPACKライブラリにSun Performance Libraryを使用します。 |
| --with-system-xz=no | OS付属のlzmaライブラリを使用しません。 |
| --disable-long-double | 倍精度double型を使用しません。 |
# ./configure --prefix=/opt/R-3.2.5 --with-ICU=no --enable-R-shlib=yes --with-blas='-library=sunperf' --with-lapack='-library=sunperf' --with-system-xz=no --disable-long-double
エラーが無ければコンパイルを行います。本数が多いので平行してコンパイルを行うため、gmakeで-jオプションを使用します。
# gmake -j
コンパイル中、ドキュメントを生成するステージでpdflatexがないという理由でエラーが発生しますが、今回はドキュメントは作成しないので、無視してかまいません。
コンパイルが終了したら実行モジュールを所定のディレクトリにコピーします。今回はドキュメントを作成していないため、それらのコピーでエラーが発生するため、-iオプションをつけてエラーを無視します。
# gmake -i install
実行時の環境変数を設定後、Rと入力して以下のような画面が出ればインストールは成功です。
# R
R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: sparc-sun-solaris2.11 (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>
Sparkの環境設定
Sparkのインストール
Sparkをダウンロードし、インストールするノードに転送します。ダウンロード画面の「Choose a package type:」では「Pre-built for Hadoop 2.7 and later」を選択します。
Sparkをインストールします。
# cd /opt
#
# ln -s spark-2.1.0-bin-hadoop2.7 spark
Sparkのオーナー/パーミッションを変更します。
# chown -R root:hadoop /opt/ spark-2.1.0-bin-hadoop2.7
# chmod -R 755 /opt/ spark-2.1.0-bin-hadoop2.7
ユーザー環境の設定
sparkユーザーの$HOME/.profileに以下の環境変数を設定する。
export LD_LIBRARY_PATH_64=/usr/local/lib/sparcv9:/opt/R/lib/R/lib
export JAVA_HOME=/usr/java
export PATH=$PATH:/opt/hadoop/bin:/opt/hadoop/sbin:/opt/spark/bin:/opt/R/bin
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Hadoop環境設定ファイルの作成
Hadoopの構成ファイルに関しては第2回と同じです。
最終的な稼動確認の前に第2回の記事を参考にHadoop環境が問題なく動いていることを確認しておきます。
Sparkのクラスタ向け設定
Sparkをクラスタモードで起動した場合、Sparkは必要とするjarファイルを一旦Hadoop上に展開し、分散環境上でアクセスができるようにします。起動する毎にその処理が実行されるのですが、かなりの時間がそれに費やされます。そこで必要となるjarファイルをHadoop上にコピーしておくことで処理時間の短縮を図ることができます。
今回はHadoopの/apl/spark-2.1.0/jars配下にjarファイルをコピーします。
# su - spark
$ cd /opt/spark/jars
$ hadoop fs -put *.jar /apl/spark-2.1.0/jars
$ exit
Sparkの構成ファイルのディレクトリ(/opt/spark/conf)に移動します。
spark-defaults.confを以下のように編集します。
spark.yarn.jars hdfs://mycluster/apl/spark-2.1.0/jars/*.jar
Sparkの稼動確認
サンプルプログラムを実行します。以下の例はクラスタモードでサンプルを起動した例です。
正常に終了すれば確認は終了です。
spark@apl-node:cd /opt/spark
spark@apl-node:~$ run-example --master yarn --deploy-mode cluster SparkPi
17/02/27 15:58:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/02/27 15:58:30 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers
17/02/27 15:58:30 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
17/02/27 15:58:30 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
17/02/27 15:58:30 INFO yarn.Client: Setting up container launch context for our AM
17/02/27 15:58:30 INFO yarn.Client: Setting up the launch environment for our AM container
17/02/27 15:58:30 INFO yarn.Client: Preparing resources for our AM container
17/02/27 15:58:33 INFO yarn.Client: Source and destination file systems are the same. Not copying hdfs://mycluster/apl/spark-2.1.0/jars/JavaEWAH-0.3.2.jar
(途中略)
17/02/27 15:58:58 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 10.20.98.138
ApplicationMaster RPC port: 0
queue: default
start time: 1488178734503
final status: SUCCEEDED
tracking URL: http://ctrl-node1:8088/proxy/application_1484800892214_0016/
user: spark
17/02/27 15:58:58 INFO util.ShutdownHookManager: Shutdown hook called
17/02/27 15:58:58 INFO util.ShutdownHookManager: Deleting directory /var/tmp/spark-3b401dfa-a2c9-4c1c-86f0-dafb5e2404b5
以上で、一通りのSparkのクラスタ環境が構築できました。
補足1:Pythonインターフェースのエラー対応
今回のSparkのバージョンでは、spark-submitコマンドでpythonプログラムを起動したときにエラーがでます。
以下はサンプルプログラムの実行時の例です。
$ spark-submit /opt/spark/examples/src/main/python/pi.py
Traceback (most recent call last):
File "/opt/spark/examples/src/main/python/pi.py", line 32, in
.appName("PythonPi")\
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/session.py", line 169, in getOrCreate
File "/opt/spark/python/lib/pyspark.zip/pyspark/context.py", line 307, in getOrCreate
File "/opt/spark/python/lib/pyspark.zip/pyspark/context.py", line 115, in __init__
File "/opt/spark/python/lib/pyspark.zip/pyspark/context.py", line 256, in _ensure_initialized
File "/opt/spark/python/lib/pyspark.zip/pyspark/java_gateway.py", line 117, in launch_gateway
File "/opt/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py", line 174, in java_import
File "/opt/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py", line 881, in send_command
File "/opt/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py", line 829, in _get_connection
File "/opt/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py", line 834, in _create_connection
File "/opt/spark/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py", line 943, in __init__
socket.gaierror: [Errno 9] service name not available for the specified socket type
暫定的なエラー対応として以下のようにしてください。
/opt/spark/python/libに移動してpy4j-0.10.4-src.zipのバックアップを取ります。
# cd /opt/spark/python/lib
# cp py4j-0.10.4-src.zip old_py4j-0.10.4-src.zip
/tmp配下でpy4j-0.10.4-src.zipを展開します。
# cd /tmp
# unzip /opt/spark/python/lib/py4j-0.10.4-src.zip
py4j/java_gateway.javaの943行目と2004行目を下記のように修正します。
af_type = socket.getaddrinfo(self.address, self.port)[0][0]
↓
af_type = socket.getaddrinfo(self.address, None)[0][0]
修正したソースを以下のようにしてシステムに反映させます。
# zip -u -r /opt/spark/python/lib/py4j-0.10.4-src.zip py4j
先ほどと同じサンプルを実行します。正常に終了すれば処置は完了です。
$ spark-submit /opt/spark/examples/src/main/python/pi.py
17/03/15 11:00:39 INFO spark.SparkContext: Running Spark version 2.1.0
17/03/15 11:00:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/03/15 11:00:40 INFO spark.SecurityManager: Changing view acls to: spark
17/03/15 11:00:40 INFO spark.SecurityManager: Changing modify acls to: spark
17/03/15 11:00:40 INFO spark.SecurityManager: Changing view acls groups to:
17/03/15 11:00:40 INFO spark.SecurityManager: Changing modify acls groups to:
(中略)
17/03/15 11:00:46 INFO scheduler.DAGScheduler: Job 0 finished: reduce at /opt/spark/examples/src/main/python/pi.py:43, took 2.932051 s
Pi is roughly 3.143480
17/03/15 11:00:46 INFO server.ServerConnector: Stopped ServerConnector@61399f47{HTTP/1.1}{0.0.0.0:4040}
17/03/15 11:00:46 INFO handler.ContextHandler: Stopped
(後略)
補足2:RのM12最適化コンパイル
RをM12上で最適化してコンパイルする場合は以下のようにしてください。
必要なOS/ソフトは以下となります。
- OS:Oracle Solaris11.3 SRU 20以上
- Oracle Developer Studio:12.6
コンパイル用の環境変数は以下のように設定します。-xtargetにはsparc64xiiを指定してください。その他のコンパイルオプションの詳しい説明はOracle Developer Studioのマニュアルを参照してください。
export CFLAGS="-m64 -xO5 -fma=fused -xlibmieee -xlibmil -xmemalign=8s -xtarget=sparc64xii -xvector=simd,lib -xpagesize=4M"
export CC="cc -std=c99"
export FFLAGS="-m64 -xO5 -fma=fused -xlibmil -dalign -xtarget=sparc64xii -xvector=simd,lib -xpagesize=4M"
export F77="f95"
export CXXFLAGS="-m64 -xO5 -fma=fused -xlibmil -xmemalign=8s -xtarget=sparc64xii -xvector=simd,lib -xpagesize=4M"
export CXX="CC -library=stlport4"
export FC="f95"
export FCFLAGS=$FFLAGS
export FCLIBS=""
export LDFLAGS="-m64 -xO5 -xmemalign=8s -xvector=simd,lib -xpagesize=4M -L/usr/local/lib"
コンパイルの手順はM10の場合と同様です。
これまで3回にわたり、SPARC Servers / Solaris上でのHadoopとSparkの環境構築について説明してきました。
いかがだったでしょうか。
今後もSolarisでの様々な活用ソリューションをお届けしたいと思います。